







 本文介绍了一种名为Shunted Self-Attention (SSA) 的Transformer改进方法,旨在解决ViT在处理多尺度任务时的局限。通过分组注意力头并采用不同下采样率,SSA能更好地处理混合尺度注意力。实验部分展示了SSA在图像分类、对象检测与实例分割、语义分割任务上的优秀性能,并进行了详细的消融研究。
本文介绍了一种名为Shunted Self-Attention (SSA) 的Transformer改进方法,旨在解决ViT在处理多尺度任务时的局限。通过分组注意力头并采用不同下采样率,SSA能更好地处理混合尺度注意力。实验部分展示了SSA在图像分类、对象检测与实例分割、语义分割任务上的优秀性能,并进行了详细的消融研究。
文章地址:https://arxiv.org/abs/2111.15193
1. Motivation
ViT的每层特征的感受野大小是相似的,导致无法处理多尺度目标大小的任务。
2. Contribution
提出SSA,将attention head分组,每组负责不同的attention granularity,来处理hybrid-scale attention
3. Methods
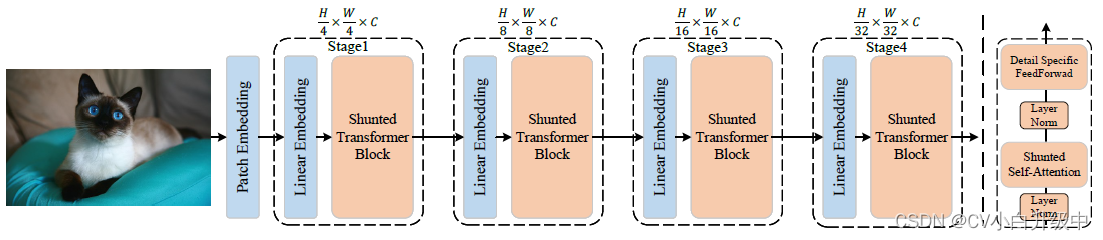
3.1 Shunted transformer block
Shunted self-attention: multi-head self-attention中不同head的key和value采用不同的下采样率
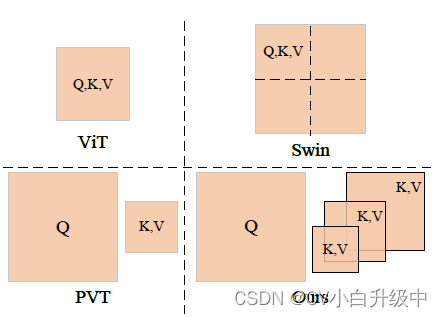
<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4024
4024

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









