






 本文介绍了如何使用Python爬虫批量下载相册中的所有图片,包括封装爬取图片的函数、创建文件夹、保存图片等步骤。在实际操作中遇到了因相册名称包含特殊字符导致的异常,最后通过排除或处理该问题完成了119个相册共830张图片的下载,耗时15分钟。文章适合初学者学习爬虫基础。
本文介绍了如何使用Python爬虫批量下载相册中的所有图片,包括封装爬取图片的函数、创建文件夹、保存图片等步骤。在实际操作中遇到了因相册名称包含特殊字符导致的异常,最后通过排除或处理该问题完成了119个相册共830张图片的下载,耗时15分钟。文章适合初学者学习爬虫基础。

接上一篇,昨天我们把相册中的一个图片,最终根据网页地址提取了图片地址,下载了下来。今天,我们用一个for循环,把相册中的所有图片先下载下来。
一、爬取网页(一个相册)的所有照片
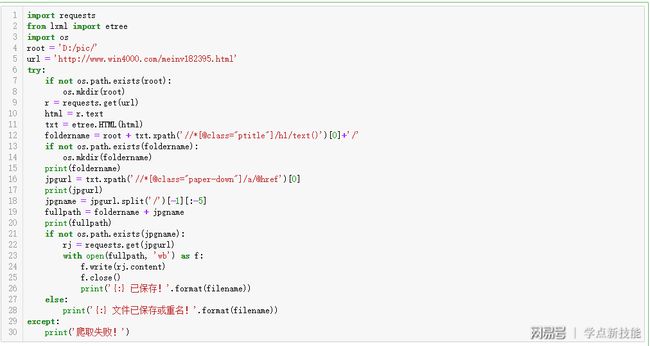
既然是循环,肯定要多次重复的执行代码,我们先把它封装成函数,这样,结构上能够简洁点;上图是昨天的代码,对比用。
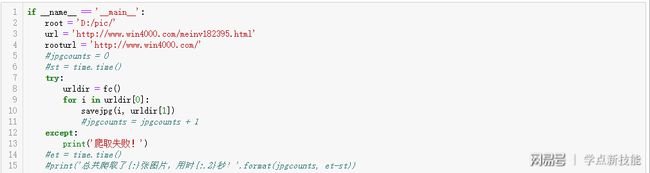
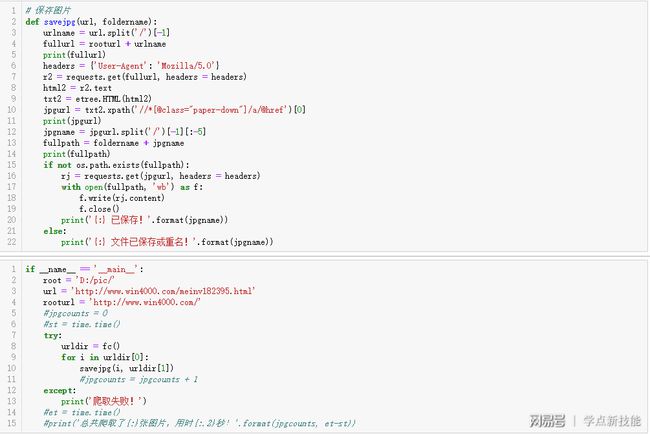
我们结合今天的目标,来改成函数。这是主程序,第4行,图片网页地址的前缀rooturl;第8行,通过fc函数创建相册文件夹,返回图片网页地址列表urldir[0]和文件夹路径urldir[1];for循环图片网页地址列表urldir[0],调用savejpg函数把图片下载下来保存在相册文件夹里;这是和昨天代码不一样的地方。
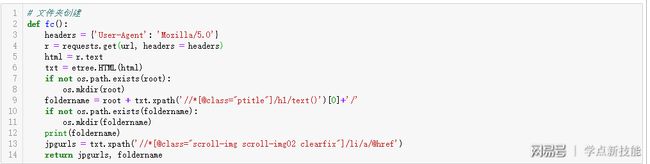
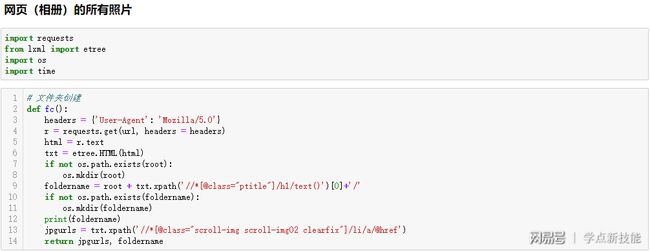
我们先来看第一个函数fc:第3到6行,把图片的网页地址实例化;第7到9行,创建相册文件夹,连接成完整的相册文件夹路径;第10到12行,创建相册文件夹并输出;第13到14行,用xpath解析出所有的图片网页地址,并返回图片网页地址列表和文件夹名字。
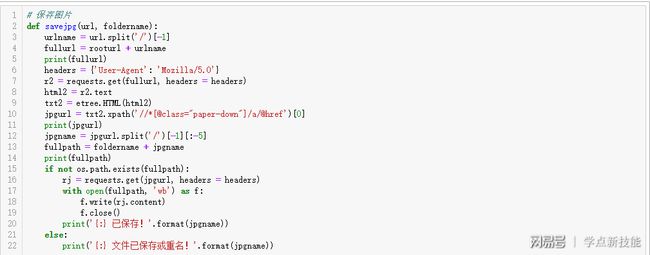
再看第二个函数savejpg:第一个参数是图片网页地址,第二个是文件夹名字。第3到5行,得到完整的网页地址并输出;第6到9行,把图片的网页地址实例化;第10到11行,提取图片地址并输出;第12到14行,得到完整的图片路径并输出;第15到22行,保存图片并提示。

记得先导入库文件。
完整代码见上图。
二、爬取所有相册的所有照片
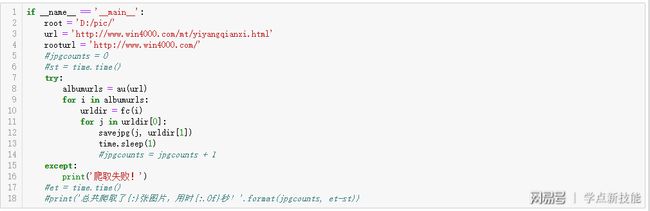
说下和第一部分代码有变化的地方,第3行:既然要爬取所有的相册,那url的内容就要再往上一级;第9行,又多了一个for循环。
该页面下有24个相册。
总共有5页。
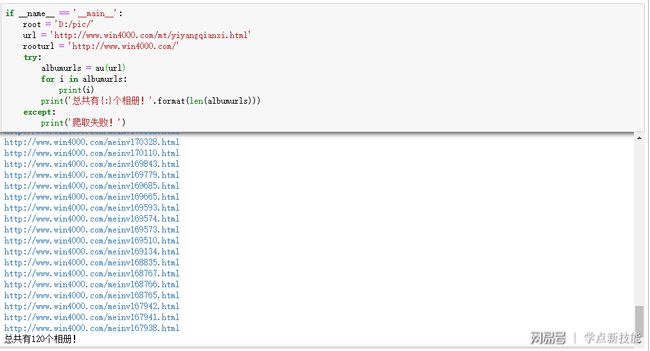
合计120个相册。

和第一部分相比,多了一个获取相册地址au的函数:第2到3行,url指的是某人所有相册的初始地址,空列表准备存放所有的相册地址,这也是该函数的返回值。
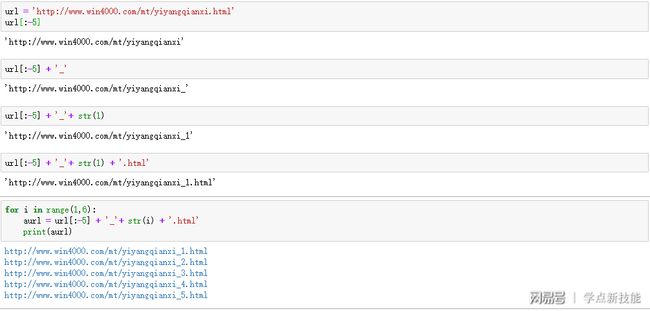
第5行,因为有五个主页面,不同的变化在文件名最后,以数字区分,用for循环i从1到5变化,合成正确的主页面地址,记着改成字符串类型。
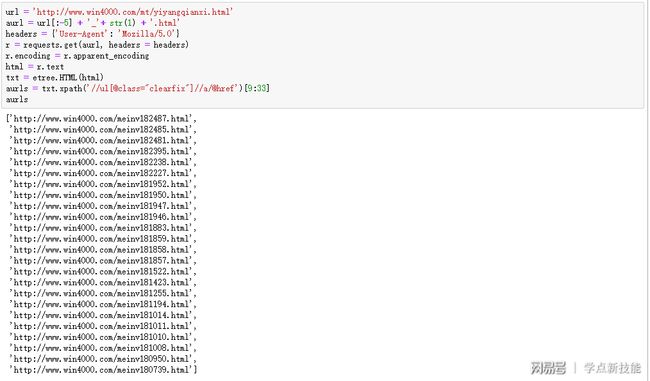
第7到11行,把当前主页面实例化;第12行,提取当前页面的24个相册地址;第13行,依次添加到之前准备的空列表里。上图是第1个主页面的所有相册地址。
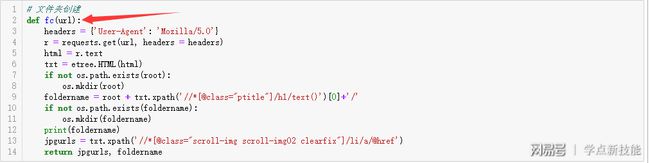
文件夹创建函数fc多了一个参数,毕竟第一部分的相册地址是固定,这次需要遍历120次。
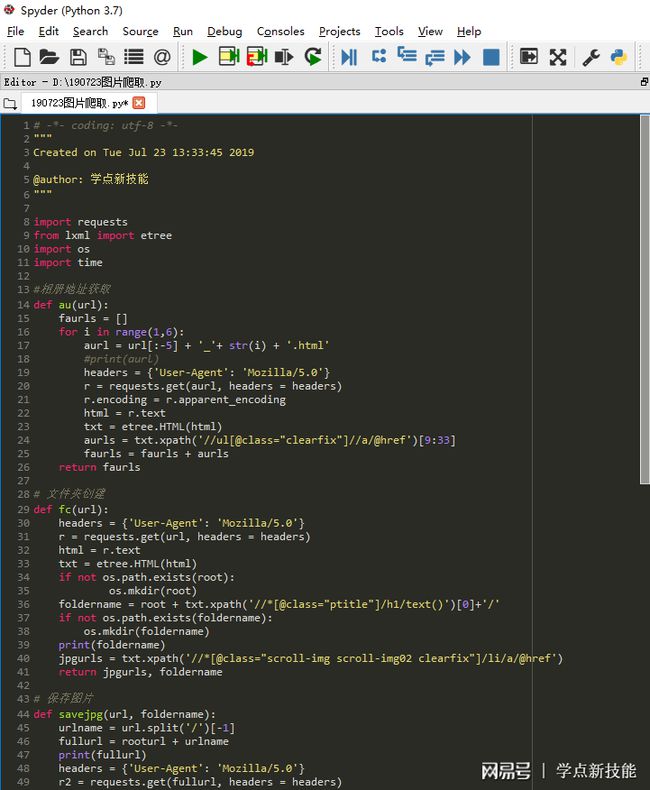
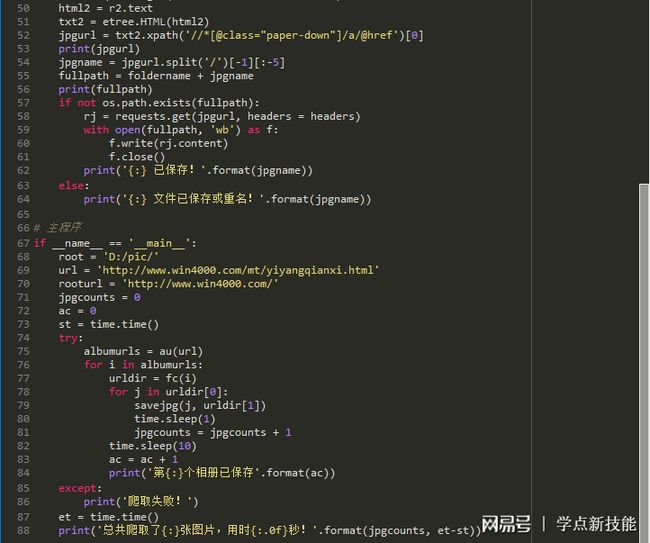
完整代码见上图。
三、遇到的问题
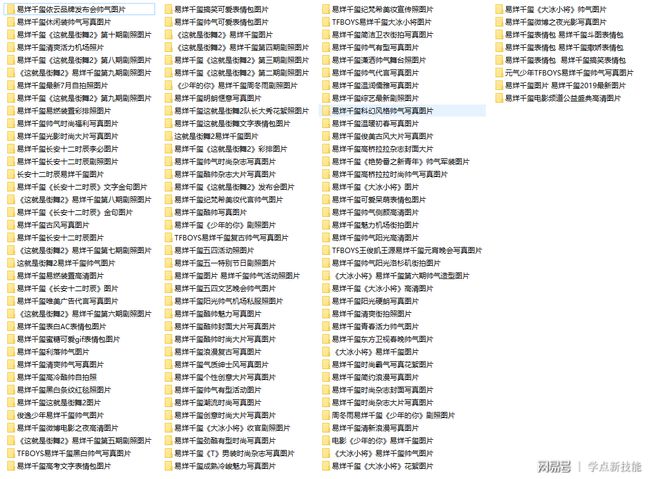
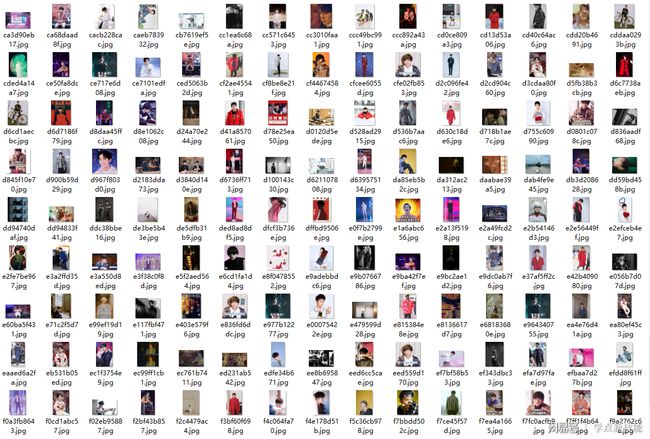
119个文件夹,看着是不是很壮观
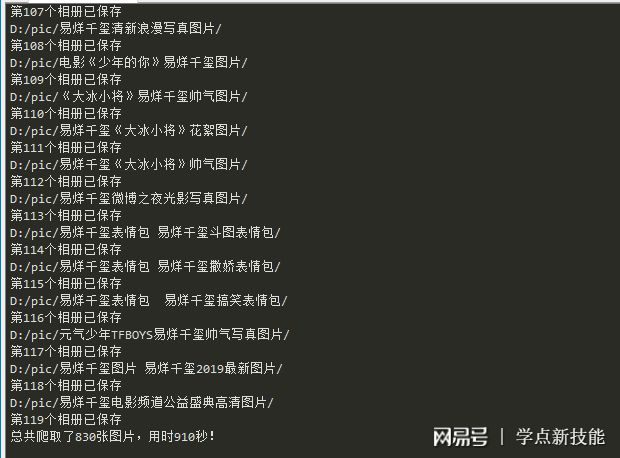
爬取了830张图片,用了15分钟多。
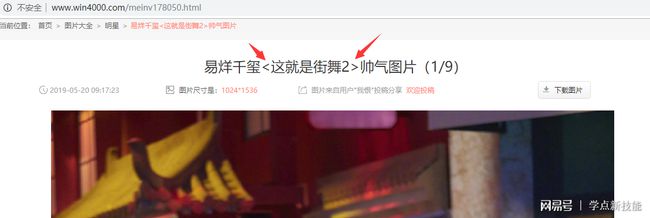
至于为什么是119个相册,是因为这个相册的名字有问题。

含有系统不认可的字符。
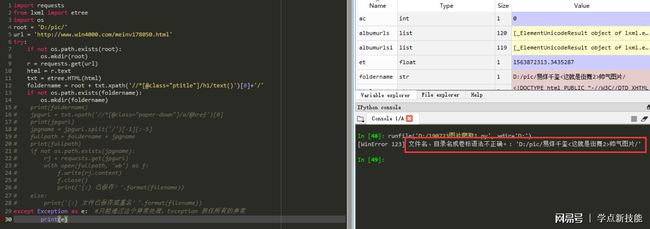
刚开始我也没搞清楚,每次都是到爬完48个相册,就不执行了;把这个相册隔过去,就正常了。
四、解决方法:
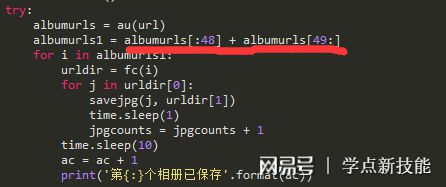
我想到的有三种,1.把它隔过去;
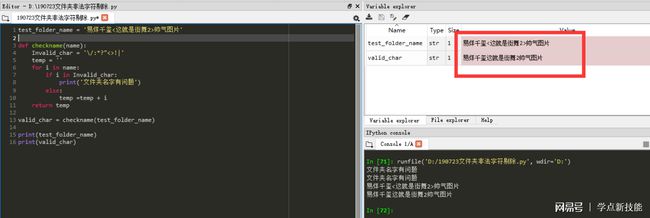
2.创建一个函数,把系统不认可的字符剔除;
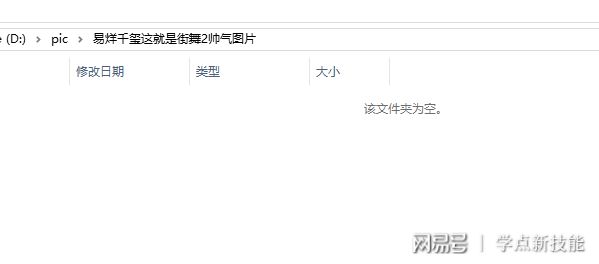
3.舍弃这个相册的9张图片。
结尾
希望你能通过这两天的内容,学会爬取图片的一些基础方法。

















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









