



 本文探讨了量子力学中复数的应用及其数学意义。通过引入复数的概念,文章解释了其在构建多维空间中的作用,并进一步讨论了这些空间与量子理论之间的联系。
本文探讨了量子力学中复数的应用及其数学意义。通过引入复数的概念,文章解释了其在构建多维空间中的作用,并进一步讨论了这些空间与量子理论之间的联系。
量子力学不仅仅只是物理,实际上是量了理论,还包含了很深刻的数学,当然还有计算机科学.这其实是未来看得见的终极科学,虽然艰难,但值得学习.
刚开始一点点,就遇到数学上的问题.首先是复数,这个忘的差不多了,不过刚又看了下还算容易理解,虚数,就是-1的根,也就是虚数的平方是-1.
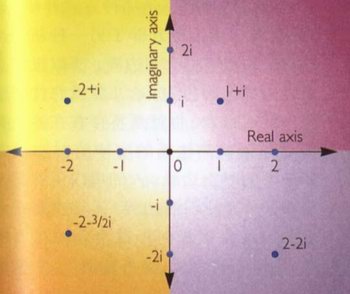
所以说,还是得夸学科啊,只学一门专业,注定一生脑残,用计算机的头脑再回头看这个数轴,就更容易理解了,i就是实数轴上的另一个维度.这个维度,和实数正好是正交的.
再用函数式来理解,也是一样的,f(x(a)), x(f(a)),看,不同的维度可以互换正交.i^2, 刚好就是-1了,而-i^2,则变成了+1.
简单来说,实数就是一根线,而复数,就变成一个面了.面上,就产生了方向,所以有了失量.
如果再增加一个维度,则就是个球状了.那么方向就有三个量了.
如果在复数上再加上些变量,那么这个三维或二维空间就变得奇形怪状了.就变成复变函数了.f(xi),对应的函数式.这样的东西能写成程序吗?
而量子力学,则是量子在这种奇形怪状的空间神出鬼没的物理表象,量子理论就是描述这些的理论,而相关的数学提供了支持.
可见,我们生活的现实空间,其实并非三维,只是三维刚好被我们所理解.这可能和人体的机能有关系.
复变函数组成的奇奇怪怪的空间图案,真是美妙无比,如果说人类的肉眼看见的是三给空间的话,那么天眼看到的就是复变空间了.也就是分形,也就是本质.


















 4
4

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









