



 本文介绍了一个使用Python爬取京东iPhone 8商品评论数据的过程,并通过数据分析生成了评论词云图。
本文介绍了一个使用Python爬取京东iPhone 8商品评论数据的过程,并通过数据分析生成了评论词云图。

前言:
最近关注了ID王大伟的博客, 看见他的博文对Python爬虫的爬取觉得很有意思, 于是跟着操作, 以下是操作步骤:
1. 上京东店铺商品品评论经行分析,话不多说直接上图:
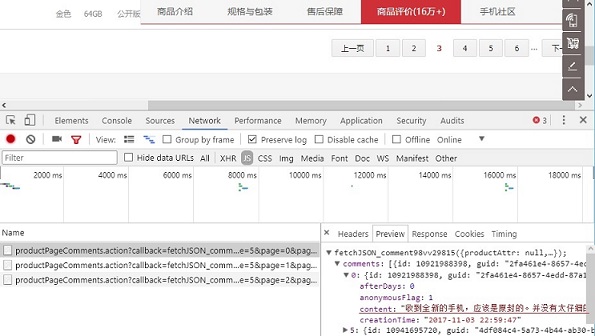
评论翻页,可能是异步加载所以网址不变 , 打开浏览器开发者模式 , 点击Network--Presecer log 然后clear , 选择Js . 每当点击分页就会增加一条Js , 它们唯一不同的就是page的值不同 . 在看Perview中content是顾客评论的内容 , 然后还有追评 .
2. 分析后开始爬取数据
import re # 正则表达式
import pandas as pd # pandas 数据分析包
import requests # Python支持HTTP返回参数
f = open('d:/comment_iphone8.txt','a') #
for i in range(0,720):#720
response = requests.get('https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98vv4962&productId=5089225&score=0&sortType=5&page='+str(i)+'&pageSize=10&isShadowSku=0&rid=0&fold=1')
response = response.text
#print(response)
pat = '"content":"(.*?)","'
res = re.findall(pat,response)
for j in res:
for j in res:
k = j.replace('\\n','')
# print(k)
f.write(k)
f.write('\\n')
f.close()然后找到生成的文件:
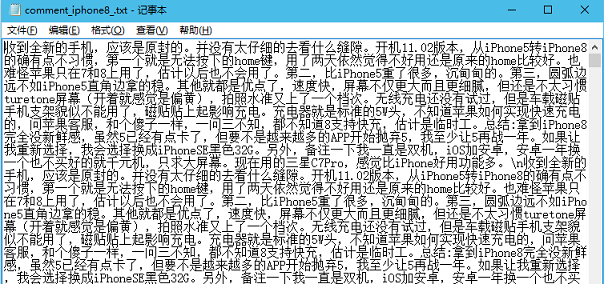
3. 制作评论词云图
# 导入模块
from os import path # 操作系统功能
from scipy.misc import imread # 专为科学和工程设计的Python工具包
import matplotlib.pyplot as plt # python最著名的绘图库
import jieba # 结巴分词
from wordcloud import WordCloud # 制作词云
f = open('d:/comment_iphone8_.txt','r')
text = f.read()
cut_text = ' '.join(jieba.lcut(text))
print(cut_text)
color_mask = imread("iphone8_.jpg") # 图片在本执行路径下
cloud = WordCloud(
font_path='FZMWFont.ttf', # 字体最好放在与脚本相同的目录下,而且必须设置
background_color='white',
mask=color_mask,
max_words=200,
max_font_size=5000
)
word_cloud = cloud.generate(cut_text)
plt.imshow(word_cloud)
plt.axis('off')
plt.show()最后我的效果如下:


传送门: https://ask.hellobi.com/blog/wangdawei/10230

















 379
379

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









