







使用scrapy爬取京东网上图书 里面涉及的图书目录涉及到使用JavaScript动态渲染的页面
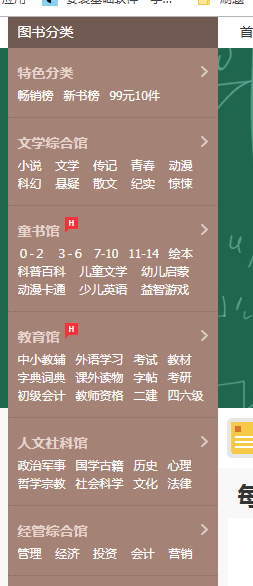
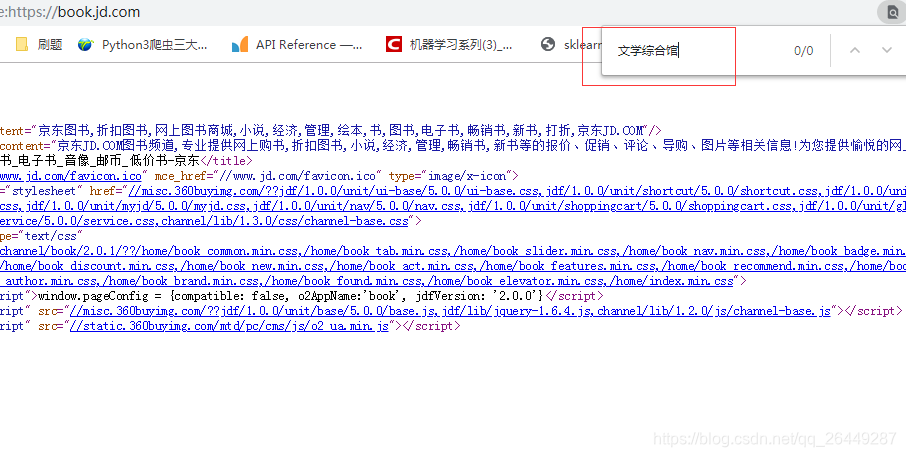
类别在源码中找不到,因为它采用了js加载 的
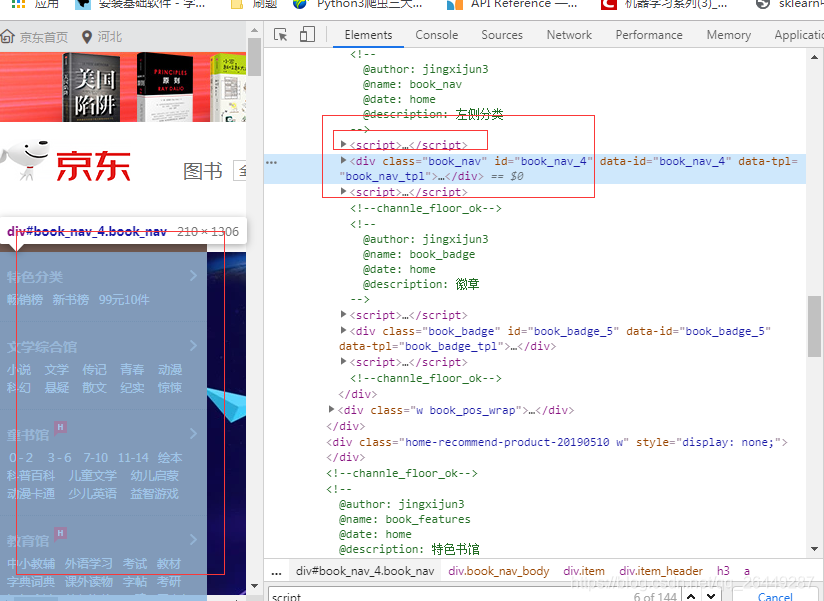
对于使用js加载的数据我们可以采用,前面在((好久没写爬虫了,好多东西都忘了)使用scrapy爬取京东网上图书)提到的抓包分析,也可以使用模拟浏览器的方法进行提取图书类别。模拟浏览器我们采用的是selenium
下面直接使用 selenium 爬取京东动态加载数据(JavaScript动态渲染的页面) 直接给出代码,里面有详细的介绍:
#-*-coding:utf-8-*-
__author__ = 'fankai'
from lxml import etree
from selenium import webdriver
import time
# 使用selenium模拟人为访问页面,获取数据
def spider_jd(url):
browser = webdriver.Chrome(r'C:\SoftWare\G 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 446
446

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









