






 本文详细解读了MapReduce中的关键步骤,包括Shuffle过程中的三次排序、Partitioner的作用、Combiner如何在Map端压缩数据量以及多个Reduce端生成的不合并结果文件。提供了对MapReduce流程图的理解和参考博客链接。
本文详细解读了MapReduce中的关键步骤,包括Shuffle过程中的三次排序、Partitioner的作用、Combiner如何在Map端压缩数据量以及多个Reduce端生成的不合并结果文件。提供了对MapReduce流程图的理解和参考博客链接。
看了两天的各种博客,终于把MapReduce的原理理解了个大概。花了1个小时画了个流程图。大家看看,有不对的地方欢迎指正。
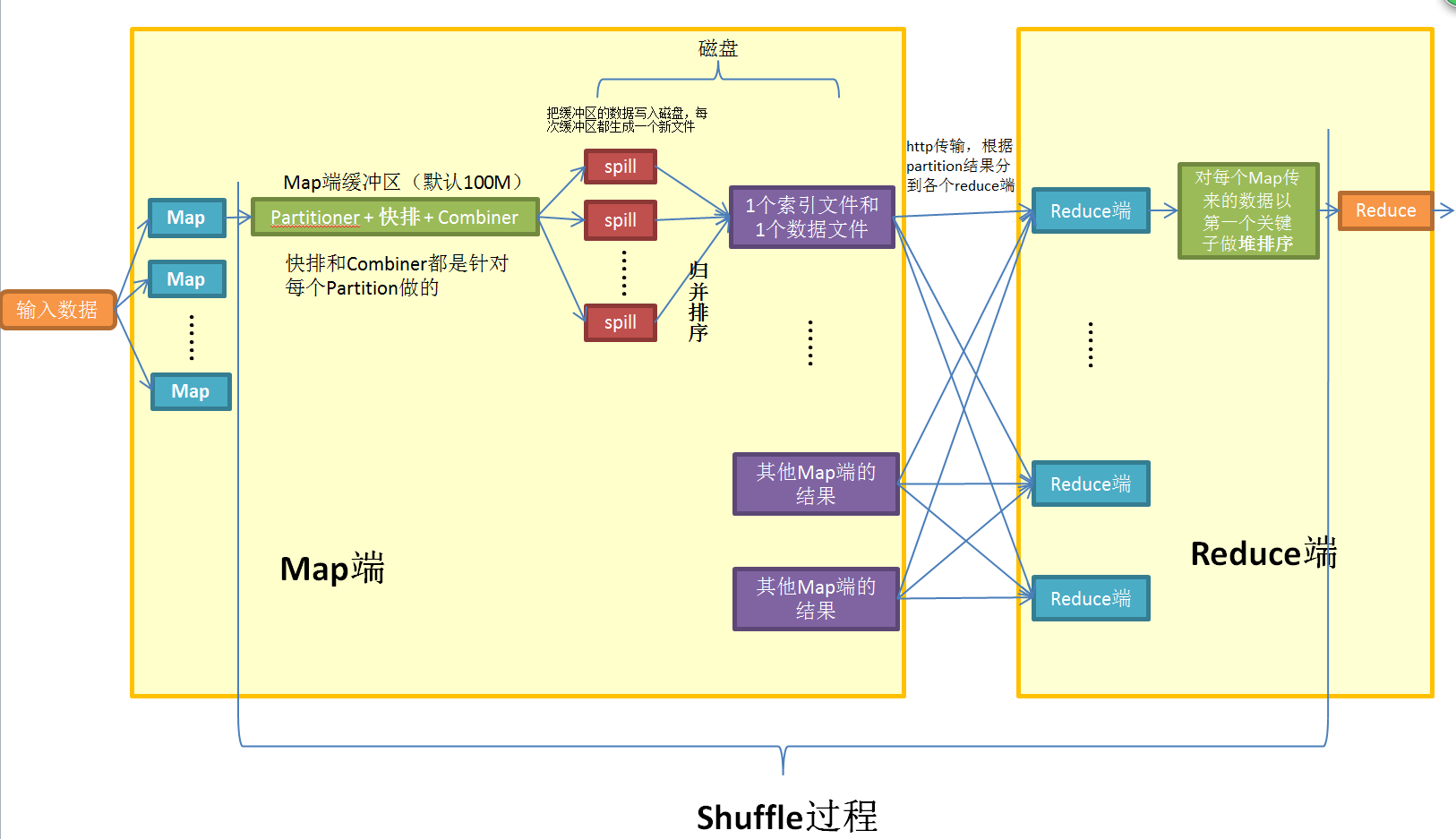
关键步骤:
Map, Reduce就不多说了。记录一下我看了很久的部分:
1. Shuffle :指的是从Map输出到Reduce输入之间的操作。期间有三次排序操作,Partition与Combine如果选择了也在Shuffle过程中。
2. Partitioner :是在使用多个Reduce端的时候决定数据发往哪个Reduce端的,默认是对Key哈希,保证同一个Key值的数据送往同一个Reduce端。
3. Combiner : 在Map端对数据做一次小型的Reduce操作,压缩数据量,减少之后传输的压力。(当服务器太忙的时候,就算选择了Combiner也不执行)
4. 输出:这里我有点困惑,多个Reduce生成了多个结果文件,网上说这些结果文件是不合并的,如果合并需要自己加一个合并的语句。见关于MapReduce中多个reduce输出的问题
参考博客见这里:【hadoop】有参考价值的博客整理


















 1883
1883

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









