






5-Kernel Logistic Regression
Last class, we learnt about soft margin and its application. Now, a new idea comes to us, could we
apply the kernel trick to our old frirend logistic regression?
Firstly, let's review those four concepts of margin handling:

As we can see, the differences between "Hard" and "Soft" is showed from constant C, which is a bit similar to Regularization.
Since we define a new factor called ξ, we can use MAX function smoothly express the margin violation:

thus the unconstrained form of soft-margin SVM:

We can easily find that the form of this subject is similar to L2 regularization.
However, there is no QP formation and the function of max may lead to some place not differentiable.
Thus we get the idea, which apply SVM as a regularization model:

For the REGULARIZATION FORM SVM, a larger C means the smaller influence from wTw, which is the regularization factor.
Then, a comparition about error will be given,
the SVM error has different appearance with the middle point, which we called hinge error measure.
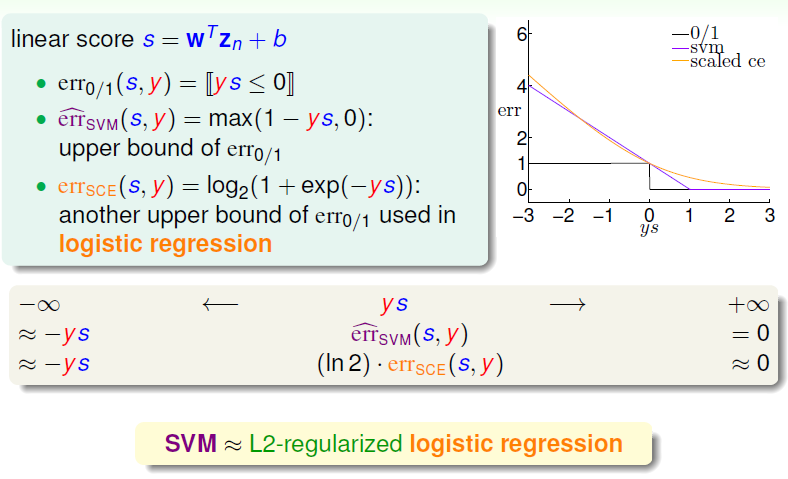
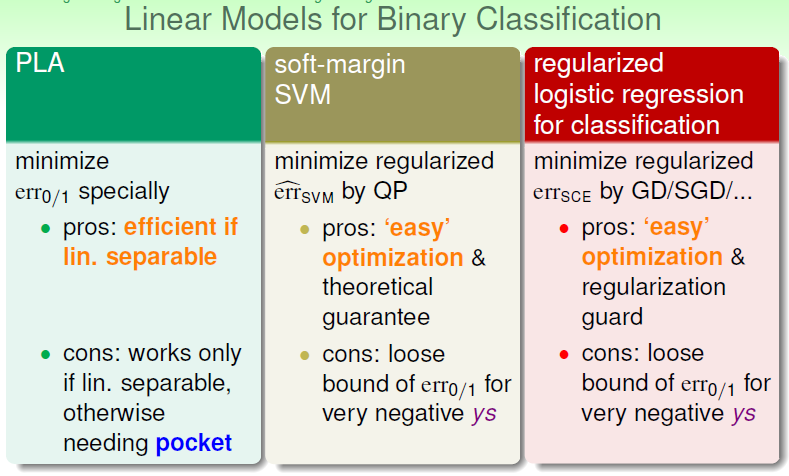
Now for this binary Classification, could LogReg and SVM be joint?
Because we know the advantage of SVM, which is able to simplify the computing by kernel, while the LogReg holds some other benefits.

Here we apply the Platt's Scaling https://en.wikipedia.org/wiki/Platt_scaling
which is found to be a nice method to better the binary problem.
We caculate the transforming of SVM to get the w and b, and we other tool to find best A and B.

In conclusion, the structure of our demand is like that :
we want to use KERNEL -> we need wT*Z (to package into KERNEL) -> we need linear combination of Zn
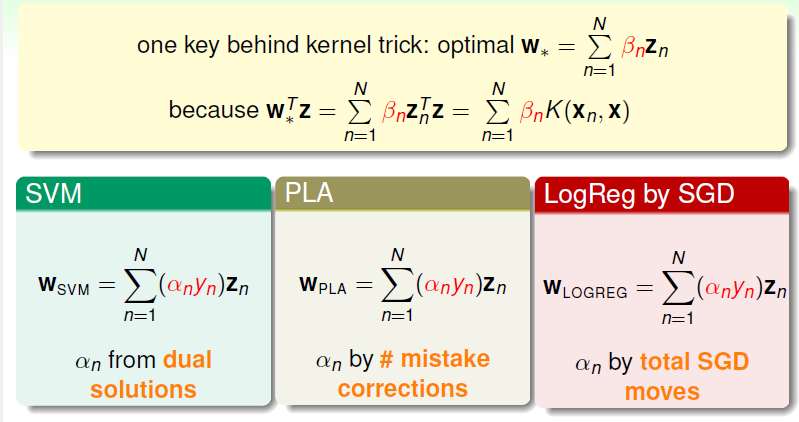
optimal w be represented by zn:

Since the w|| can be prpved to be the only subitem in w:
It can be proved that any L2- regularized linear model can be kernelized.
So, here we get a new represention called Kernel Logistic Regression (KLR),
There are something we should pay attention:
1. the dimention of this issue is subject to N of samples.
2. the β can be seen as a description toward the relationship between xn and any other points in X space.
3. βn could not be zero, which means larger computing cost compared to the process of finding good w.


















 1164
1164

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









