



 本文介绍如何利用查找表(LUT)优化图像颜色减少处理的速度。通过三种不同的方法实现:使用Mat的ptr()指针访问,使用MatIterator迭代器安全访问以及使用at()方法随机访问。并对比了这些方法的效率。
本文介绍如何利用查找表(LUT)优化图像颜色减少处理的速度。通过三种不同的方法实现:使用Mat的ptr()指针访问,使用MatIterator迭代器安全访问以及使用at()方法随机访问。并对比了这些方法的效率。
使用LUT(lookup table)检索表的方法,提高color reduce时对像素读取的速度。
实现对Mat对象中数据的读取,并计算color reduce的速度。
方法一:使用Mat的ptr()遍历行(row),效率较高,使用时需要小心细节
1 #include <opencv2/core/core.hpp> 2 #include <opencv2/highgui/highgui.hpp> 3 #include <iostream> 4 #include <sstream> 5 6 using namespace std; 7 using namespace cv; 8 9 static void help(){ 10 cout 11 << "Author: BJTShang" << endl 12 << "2016-12-22, CityU" << endl 13 << "Use: " << "./1222_LUP imageName divideWith [G]" << endl 14 <<endl; 15 } 16 17 Mat& ScanImageAndReduceC(Mat& I, const uchar* table); 18 Mat& ScanImageAndReduceIterator(Mat& I, const uchar* table); 19 20 int main(int argc, char** argv){ 21 help(); 22 if(argc<3){ 23 cout << "Not enough parameters!" << endl; 24 return -1; 25 } 26 27 Mat I; 28 char* imageName = argv[1]; 29 if(argc==4 && !strcmp(argv[3],"G")){ 30 I = imread(imageName, CV_LOAD_IMAGE_GRAYSCALE); 31 }else{ 32 I = imread(imageName, CV_LOAD_IMAGE_COLOR); 33 } 34 35 if(!I.data){ 36 cout << "The image" << imageName << " has no data!"; 37 return -1; 38 } 39 40 int divideWith = 0; 41 stringstream s; 42 s << argv[2]; 43 s >> divideWith; 44 if(!s || !divideWith){ 45 cout << "Invalid divideWith, input again (positive integer)!" << endl; 46 return -1; 47 } 48 49 // use this table to search for (by simple assignment) reduced intensity, 50 // instead of calculating for each pixel, which is computational high-cost 51 uchar table[256]; 52 for(int i=0; i < 256; ++i){ 53 table[i] = uchar((i/divideWith)*divideWith); 54 } 55 56 int64 t0 = getTickCount(); 57 Mat J = I.clone(); 58 J = ScanImageAndReduceC(J, table); 59 double t = (double)(getTickCount() - t0)/getTickFrequency(); 60 cout << "Elapse time = " << t*1000 << " ms" <<endl; 61 62 namedWindow("before", CV_WINDOW_AUTOSIZE); 63 namedWindow("after color reduce by LUT", CV_WINDOW_AUTOSIZE); 64 imshow("before", I); 65 imshow("after color reduce by LUT", J); 66 waitKey(0); 67 return 0; 68 } 69 70 Mat& ScanImageAndReduceC(Mat& I, const uchar* table){ 71 CV_Assert(I.depth() == CV_8U); 72 const int channels = I.channels(); 73 74 int nRows = I.rows; 75 int nCols = I.cols*channels; 76 77 if (I.isContinuous()){ 78 nCols *= nRows; 79 nRows = 1; 80 } 81 82 uchar* p = NULL; 83 for(size_t i=0; i<nRows; ++i){ 84 p = I.ptr<uchar>(i); 85 for(size_t j=0; j<nCols; ++j){ 86 p[j] = table[p[j]]; 87 } 88 } 89 // Mat结构的ptr()方法,返回指向Mat每一行的头元素指针 90 // Mat结构的data属性,返回指向元素的指针,p++指针自加到下一块元素地址。 91 // 如果Mat中元素连续,才可以使用*p++取出所有元素值;若Mat中元素不连续,*p++取出第二行开始肯定错误! 92 // uchar* p = I.data; 93 // for(size_t i = 0; i < nRows*nCols; ++i){ 94 // *p++ = table[*p]; 95 // } 96 return I; 97 }
结果:
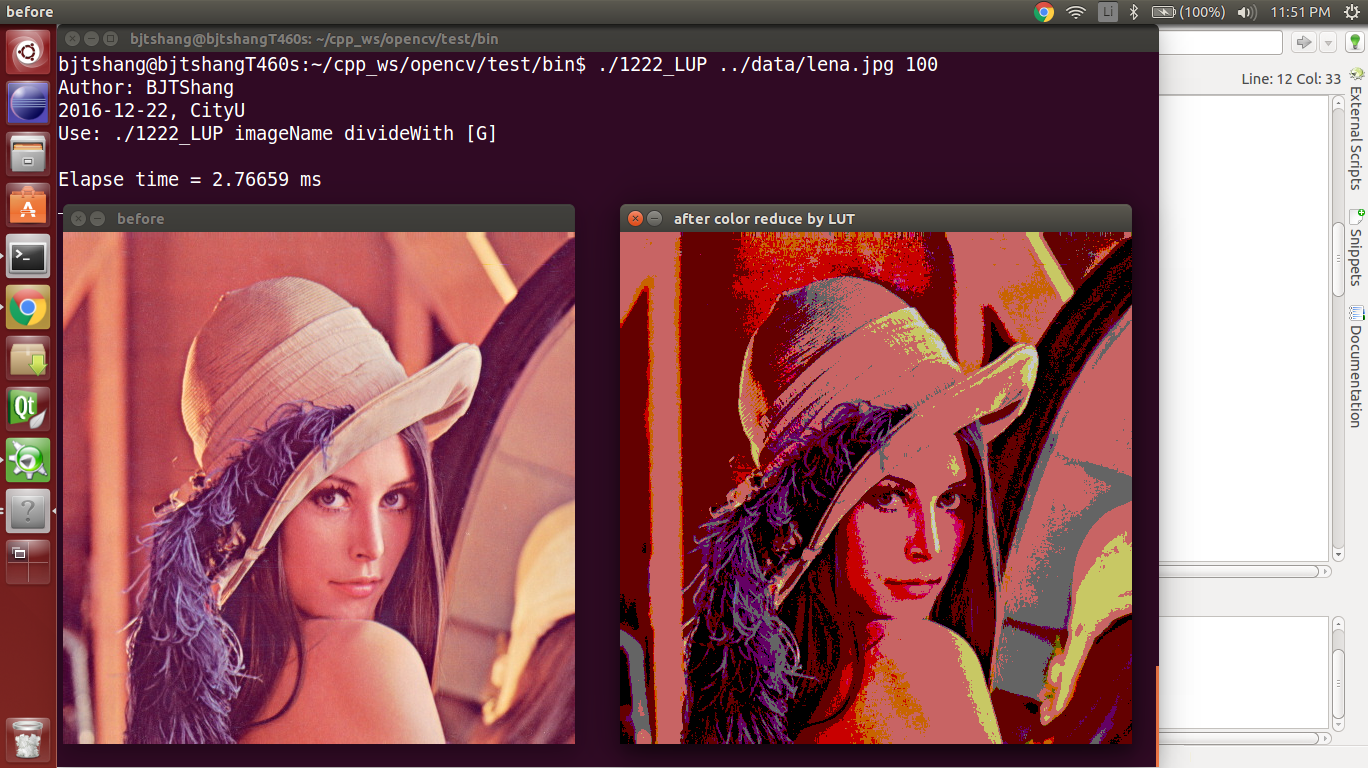
如果使用*p++的方法,结果不同:
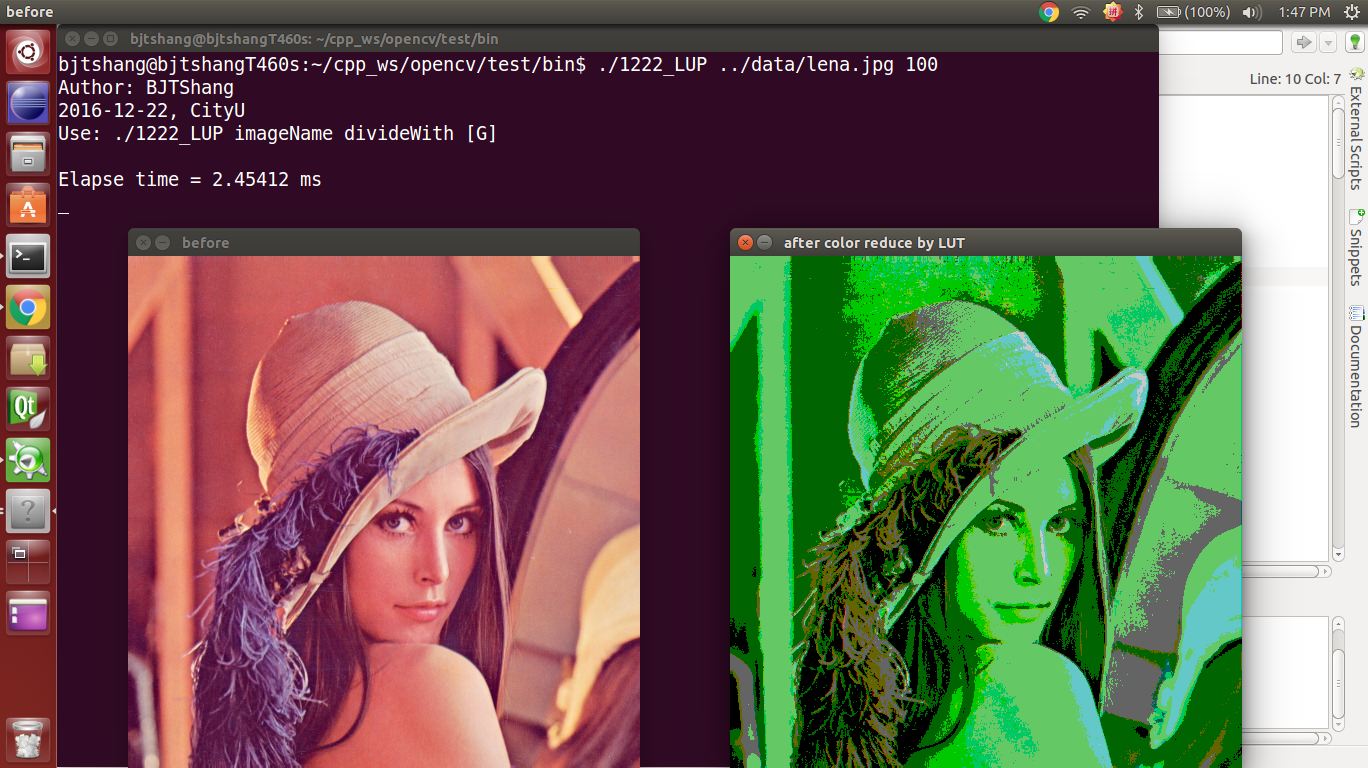
这种方法,需要自己考虑图像每一行之间的gap,以及元素类型(uchar和float32f的不同)。效率较高,但不小心会出问题。
方法二:通过MatIterator类安全地访问Mat结构
效果相同,但是运行时间会变长几倍(我的电脑上大约是3倍)
1 Mat& ScanImageAndReduceIterator(Mat& I, const uchar* table){ 2 CV_Assert(I.depth() == CV_8U); 3 int channels = I.channels(); 4 5 switch(channels){ 6 case 1: 7 { 8 MatIterator_<uchar> it,end; 9 for(it = I.begin<uchar>(), end = I.end<uchar>(); it!=end; ++it) 10 *it = table[*it]; 11 break; 12 } 13 case 3: 14 { 15 MatIterator_<Vec3b> it, end; 16 for(it = I.begin<Vec3b>(), end = I.end<Vec3b>(); it!=end; ++it){ 17 (*it)[0] = table[(*it)[0]]; 18 (*it)[1] = table[(*it)[1]]; 19 (*it)[2] = table[(*it)[2]]; 20 } 21 break; 22 } 23 } 24 return I; 25 }
对于3通道彩色图像,需要指定迭代器中元素类型为short vector: <Vec3b>。如果指定为uchar,迭代器器将只会扫描B蓝色通道;当然,这里的情况因为使用了[]操作符访问short vector中的sub colomun, 编译就通不过。。。
方法三:最容易理解,但是最不推荐的是使用Mat的at()方法
1 Mat& ScanImageAndReduceRandomAccsee(Mat& I, const uchar* table){ 2 CV_Assert(I.depth() == CV_8U); 3 4 const int channels = I.channels(); 5 switch(channels){ 6 case 1: 7 { 8 for(int i=0; i<I.rows; ++i) 9 for(int j=0; j<I.cols; ++j) 10 I.at<uchar>(i,j) = table[I.at<uchar>(i,j)]; 11 break; 12 } 13 case 3: 14 { 15 Mat_<Vec3b> _I = I; // this was used to check the data (3 channels), as well as to use [] operator to access different channels 16 for(int i=0; i<I.rows; ++i) 17 for(int j=0; j<I.cols; ++j){ 18 _I(i,j)[0] = table[_I(i,j)[0]]; // equal to _I.at(i,j*3) = table[_I.at(i,j*3)] 19 _I(i,j)[1] = table[_I(i,j)[1]]; // equal to _I.at(i,J*3+1) = table[_I.at(i,j*3+1)] 20 _I(i,j)[2] = table[_I(i,j)[2]]; // equal to _I.at(i,j*3+2) = table[_I.at(i,j*3+2)] 21 } 22 I = _I; 23 break; 24 } 25 } 26 return I; 27 }
效率和安全的使用MatIterator类差不多,想访问矩阵中特定位置的元素使用这种方法是比较合适的。
最后,OpenCV封装了LUT的color reduce方法。平常直接使用即可,效率比较高。
1 Mat lookUpTable(1, 256, CV_8U); 2 uchar* p = lookUpTable.data; 3 for(int i=0; i<256; i++) 4 p[i] = table[i]; 5 LUT(I,lookUpTable,J);

















 3171
3171

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









