



 本文详细介绍了SQL中的row_number(), rank() 和 dense_rank() 函数的使用方法,包括如何为数据集中的记录分配唯一的行号、如何处理重复值的排名问题,并提供实际应用场景如成绩排名的例子。
本文详细介绍了SQL中的row_number(), rank() 和 dense_rank() 函数的使用方法,包括如何为数据集中的记录分配唯一的行号、如何处理重复值的排名问题,并提供实际应用场景如成绩排名的例子。

参考链接:https://www.cnblogs.com/scwbky/p/9558203.html
一、介绍
这三个函数都是为了给每一条数据加上一个rank等级数字。可以实现:全班同学的数学分数排名,小明所有课程的分数排名等。
二:具体使用:
-
1、row_number()函数
分组排序后,给每条数据加上一个序号求每门课程的分数排名,按照课程分组分组,按照分数降序排序即可
select NAME, SUBJECT, SCORE, row_number() over(partition by SUBJECT order by SCORE desc) rank from student_score;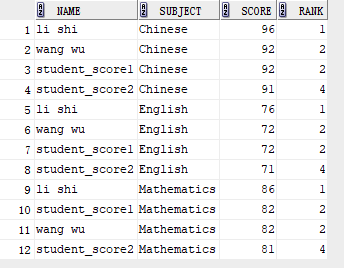
-
2、rank()函数
排序后,如果值相同,则rank值一样,但是会跳跃,比如1、2、2、4。而不是1、2、2、3。这样子会导致第三名的人变成第四名。
select NAME, SUBJECT, SCORE, rank() over(partition by SUBJECT order by SCORE desc) rank from student_score;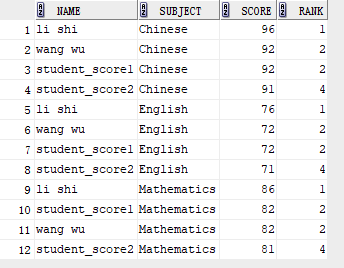
-
3、dense_rank()
解决了rank()跳跃问题,原来的4会变成3。
select NAME, SUBJECT, SCORE, dense_rank() over(partition by SUBJECT order by SCORE desc) rank from student_score;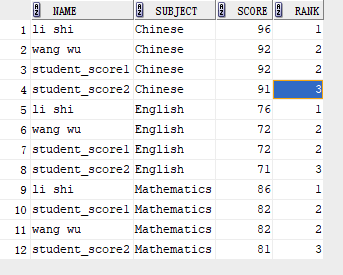
三、利用row_number排重
-
1、在数据中经常会有重复的数据,那么如何排重呢?
既然可以通过“某些字段”分组并且进行排序来给每条数据加上数据rank标识,那么相同的数据他们的rank肯定是1、2、3.。。这样的结构,所以可以通过判断rank = 1来控制只取出一条数据来达到去重的效果。
比如上述表中,学生相同的数据有很多,现在将它们去重,只需要分数最高的那条数据。
第一步:按照NAME分组,并且按照SCORE排序,给每条数据加上rank
select * , row_number() over(partition by NAME, order by SCORE desc) rank from student_score第二步:从上面结果集中,取出rank = 1的数据
select NAME, SUBJECT, SCORE from (select * , row_number() over(partition by NAME, order by SCORE desc) rank from student_score) t1 where t1.rank = 1;

















 1270
1270

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









