







 LMDB是一款轻量级数据库,采用内存映射技术实现高效读写,支持ACID特性。文章介绍了LMDB的基本架构,包括其使用mmap技术以及B+Tree数据结构。详细阐述了内存映射原理、Linux下的mmap实现,以及LMDB中mmap的过程。此外,还讨论了B-tree、B+tree和B*tree的区别,并解释了LMDB如何在内存中组织B+Tree。文章还涉及了LMDB的COW和MVCC机制,以及事务控制和核心数据结构。
LMDB是一款轻量级数据库,采用内存映射技术实现高效读写,支持ACID特性。文章介绍了LMDB的基本架构,包括其使用mmap技术以及B+Tree数据结构。详细阐述了内存映射原理、Linux下的mmap实现,以及LMDB中mmap的过程。此外,还讨论了B-tree、B+tree和B*tree的区别,并解释了LMDB如何在内存中组织B+Tree。文章还涉及了LMDB的COW和MVCC机制,以及事务控制和核心数据结构。

发现一篇讲解LMDB不错的文章,记录一下,原文在这里。
Overview
- homepage: http://symas.com/mdb/
- https://github.com/LMDB/lmdb
- source codes doc: http://symas.com/mdb/doc/starting.html
- official repo on openldap.org: http://www.openldap.org/software/repo.html
LMDB(Lightning Memory-Mapped Database) is a tiny database with some great capabilities:
- Ordered-map interface (keys are always sorted, supports range lookups)
- Fully transactional, full ACID (Atomicity, Consistency, Isolation, Durability) semantics with MVCC(Multiversion concurrency control).
- Reader/writer transactions: readers don't block writers and writers don't block readers. Writers are fully serialized, so writes are always deadlock-free.
- Read transactions are extremely cheap, and can be performed using no mallocs or any other blocking calls.
- Supports multi-thread and multi-process concurrency, environments may be opened by multiple processes on the same host.
- Multiple sub-databases may be created with transactions covering all sub-databases.
- Memory-mapped, allowing for zero-copy lookup and iteration.
- Maintenance-free, no external process or background cleanup/compaction required.
- Crash-proof, no logs or crash recovery procedures required.
- No application-level caching. LMDB fully exploits the operating system's buffer cache.
- 32KB of object code and 6KLOC of C.
LMDB基本架构
lmdb的基本架构如下:
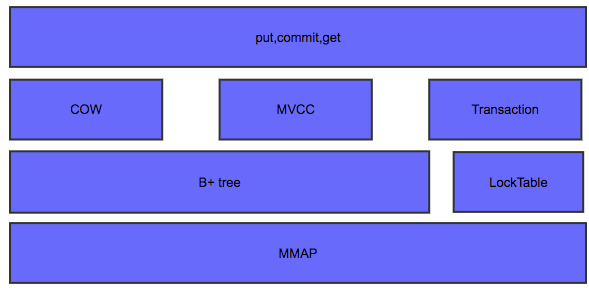
lmdb的基本做法是使用mmap文件映射,不管这个文件存储实在内存上还是在持久存储上。lmdb的所有读取操作都是通过mmap将要访问的文件只读的映射到虚拟内存中,直接访问相应的地址.因为使用了read-only的mmap,同样避免了程序错误将存储结构写坏的风险。并且IO的调度由操作系统的页调度机制完成。而写操作,则是通过write系统调用进行的,这主要是为了利用操作系统的文件系统一致性,避免在被访问的地址上进行同步。
lmdb把整个虚拟存储组织成B+Tree存储,索引和值读存储在B+Tree的页面上.对外提供了关于B+Tree的操作方式,利用cursor游标进行。可以进行增删改查。
使用Memory Map
Memory Map原理
内存映射就是把物理内存映射到进程的地址空间之内,这些应用程序就可以直接使用输入输出的地址空间.由此可以看出,使用内存映射文件处理存储于磁盘上的文件时,将不需要由应用程序对文件执行I/O操作,这意味着在对文件进行处理时将不必再为文件申请并分配缓存,所有的文件缓存操作均由系统直接管理,由于取消了将文件数据加载到内存、数据从内存到文件的回写以及释放内存块等步骤,使得内存映射文件在处理大数据量的文件时能起到相当重要的作用。
Linux下mmap的实现过程与普通文件io操作
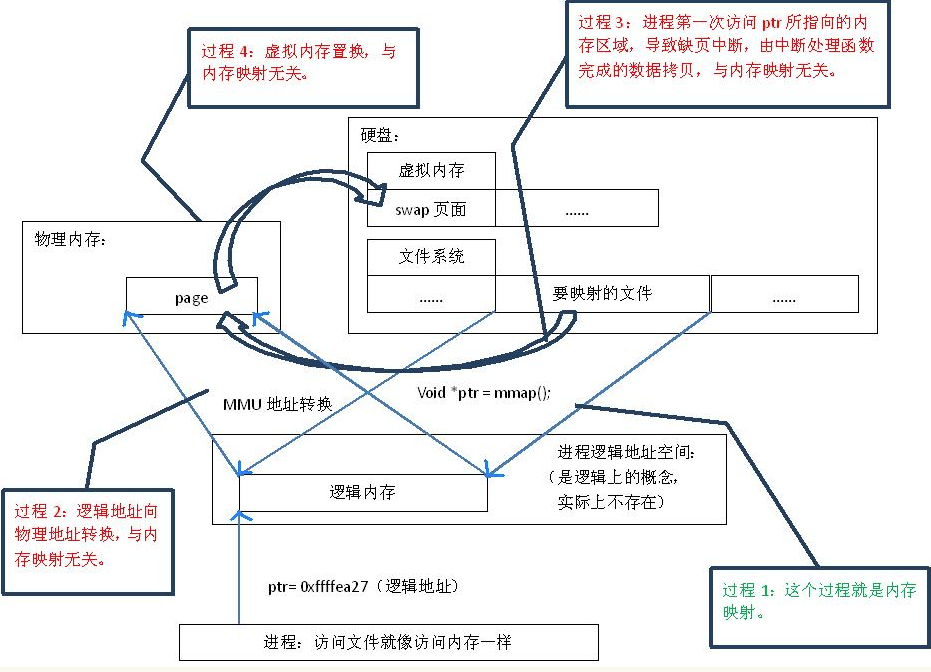
mmap映射原理与过程:
一般文件io操作方式:
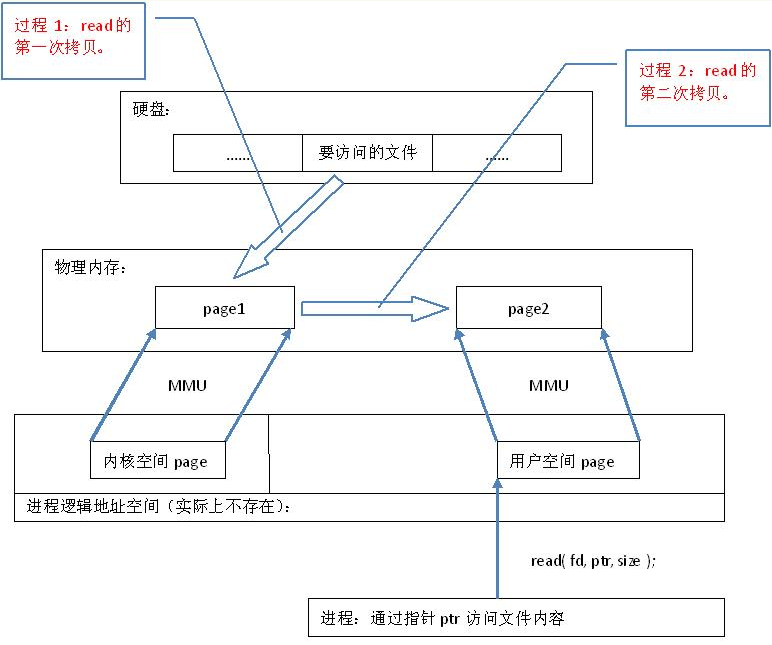
通过内存映射的方法访问硬盘上的文件,效率要比read和write系统调用高, read()是系统调用,其中进行了数据拷贝,它首先将文件内容从硬盘拷贝到内核空间的一个缓冲区,然后再将这些数据拷贝到用户空间,在这个过程中,实际上完成了 两次数据拷贝 ;而mmap()也是系统调用,如前所述,mmap()中没有进行数据拷贝,真正的数据拷贝是在缺页中断处理时进行的,由于mmap()将文件直接映射到用户空间,所以中断处理函数根据这个映射关系,直接将文件从硬盘拷贝到用户空间,只进行了 一次数据拷贝 。因此,内存映射的效率要比 read/write效率高。
lmdb使用mmap过程
lmdb创建完env对象,打开时,会做data file和lock file的mmap映射:
env->me_lfd = open(lpath, O_RDWR|O_CREAT|MDB_CLOEXEC, mode);
void *m = mmap(NULL, rsize, PROT_READ|PROT_WRITE, MAP_SHARED,
env->me_lfd, 0);
env->me_txns = m;
env->me_fd = open(dpath, oflags, mode);
env->me_map = mmap(addr, env->me_mapsize, prot, MAP_SHARED,
env->me_fd, 0); 其他时刻都直接使用内存指针,通过系统级别的缺页异常获取对应的数据。页面内数据的获取和使用MDB_CURSOR_GET进行。页面的获取和key查询通过 mdb_page_get/mdb_page_search 完成.
页面头部大小及内容是固定的,具体的含义代表根据flags决定,在头部之后紧接的是node,真正的key-value值对所在位置的索引,因此访问这些node时通过指针计算即可得到对应的位置。
lmdb 之后是如何将页面给映射进进程地址空间呢.lmdb通过 mdb_page_get 函数以 pgno 为主要参数获得页面并返回页面指针。若仅仅是只读事务且环境对象是以只读方式打开的,page的获取很简单,根据
page= (MDB_page *)(env->me_map + env->me_psize * pgno); 获得。
在lmdb中B+Tree的是基于append-only B+Tree改造的。对于数据增加、修改、删除导致页面增加时,pageno也增加,当旧页面(数据旧版本)被重用时,pageno 保持不变,因此pageno保持了在数据文件中的顺序性,从而在获取页面时,只需要进行简单计算即可以。同时在创建env对象时,数据库已经被整个映射进整个进程空间,因此系统在映射时,会给数据库文件保留全部地址空间,从而在根据上述算法获取真实数据库,系统触发缺页错误,进而从数据文件中获取整个页面内容。此为最简单有效方式,否则不将全部数据映射进地址空间,对于未映射部分还需要在访问页面时判断是否已经被映射,未被映射时进行映射。
在需要时在通过文件方式写入。lmdb保证任意时刻只有一个写操作在进行,从而避免了并发时数据被破坏。
B-tree/B+tree/B*tree
B-tree
B-tree又叫平衡多路查找树。一棵m阶的B-tree (m叉树)的特性如下:
- 树中每个结点至多有m个孩子;
- 除根结点和叶子结点外,其它每个结点至少有有ceil(m / 2)个孩子;
- 若根结点不是叶子结点,则至少有2个孩子(特殊情况:没有孩子的根结点,即根结点为叶子结点,整棵树只有一个根节点);
- 所有叶子结点都出现在同一层,叶子结点不包含任何关键字信息(可以看做是外部结点或查询失败的结点,实际上这些结点不存在,指向这些结点的指针都为null);
- 每个非终端结点中包含有n个关键字信息: (n,P0,K1,P1,K2, P2,……,Kn,Pn)。其中:
- Ki (i=1…n)为关键字,且关键字按顺序排序K(i-1)< Ki。
- Pi为指向子树根的接点,且指针P(i-1)指向子树种所有结点的关键字均小于Ki,但都大于K(i-1)。
- 关键字的个数n必须满足: ceil(m / 2)-1 <= n <= m-1。
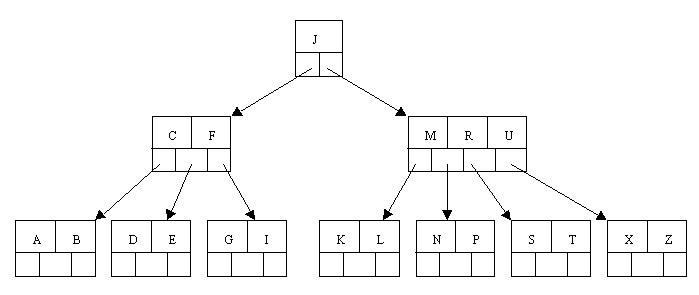
B+tree
B+ tree:是应文件系统所需而产生的一种B-tree的变形树。一棵m阶的B+-tree和m阶的B-tree的差异在于:
- 有n棵子树的结点中含有n个关键字; (B-tree是n棵子树有n-1个关键字)
- 所有的叶子结点中包含了全部关键字的信息,及指向含有这些关键字记录的指针,且叶子结点本身依关键字的大小自小而大的顺序链接。 (B-tree的叶子节点并没有包括全部需要查找的信息)
- 所有的非终端结点可以看成是索引部分,结点中仅含有其子树根结点中最大(或最小)关键字。 (B-tree的非终节点也包含需要查找的有效信息)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 8682
8682

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









