



 本文深入解析HDFS的数据写入与读取流程,包括客户端与NameNode、DataNode之间的交互过程,网络拓扑下的机架感知策略,以及数据一致性模型。通过具体步骤和代码示例,帮助读者理解HDFS如何高效、可靠地处理大规模数据。
本文深入解析HDFS的数据写入与读取流程,包括客户端与NameNode、DataNode之间的交互过程,网络拓扑下的机架感知策略,以及数据一致性模型。通过具体步骤和代码示例,帮助读者理解HDFS如何高效、可靠地处理大规模数据。

1. HDFS 写数据流程
1.1. 文件写入
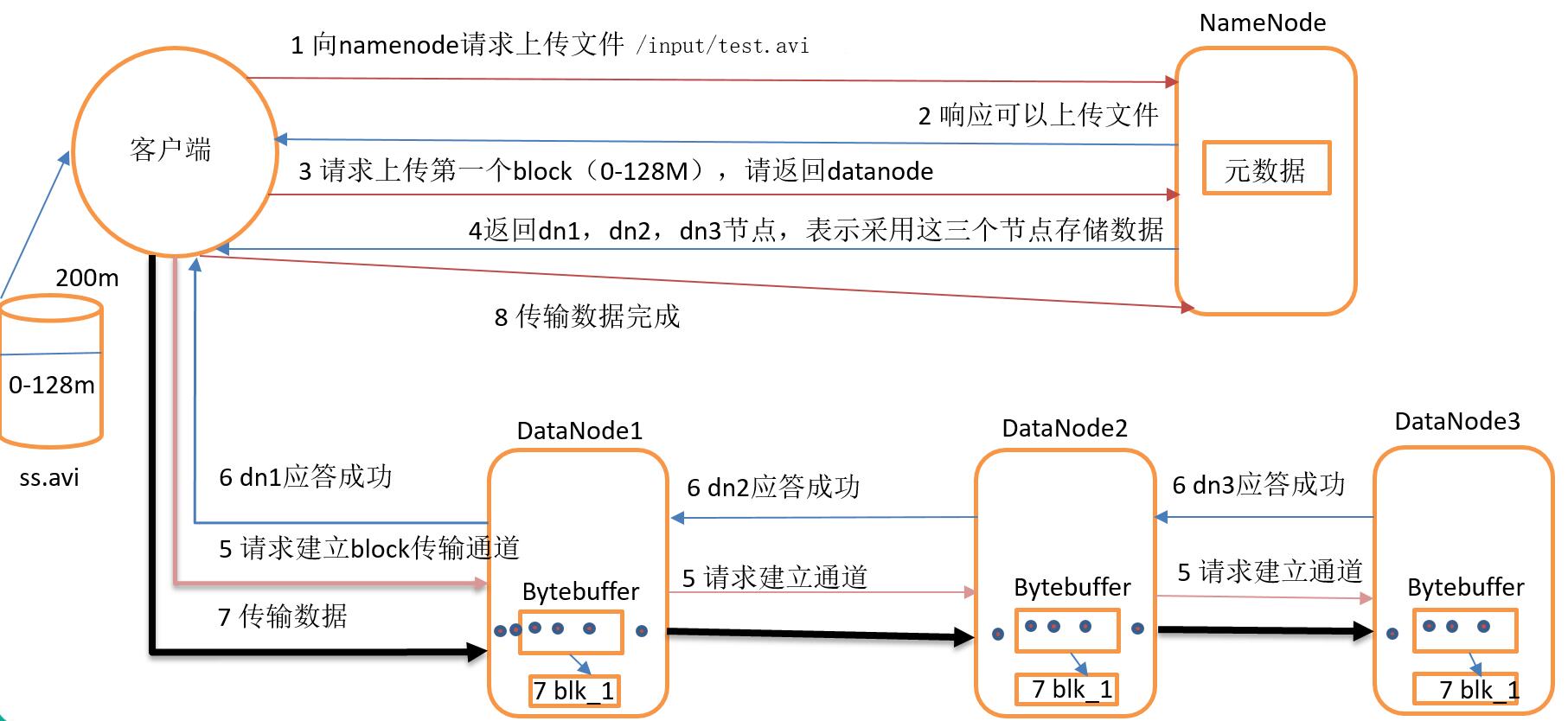
(1) 客户端向 namenode 请求上传文件,namenode 检查目标文件是否已存在,父目录是否存在;
(2) namenode 返回是否可以上传;
(3) 客户端请求第一个 block 上传到哪几个 datanode 服务器上;
(4) namenode 返回3个 datanode 节点,分别为 dn1、dn2、dn3;
(5) 客户端请求 dn1 上传数据,dn1 收到请求会继续调用 dn2,然后 dn2 调用 dn3,将这个通信管道建立完成;
(6) dn1、dn2、dn3 逐级应答客户端;
(7) 客户端开始往 dn1上传第一个 block(先从磁盘读取数据放到一个本地内存缓存),以 packet 为单位,dn1 收到一个 packet 就会传给 dn2,dn2 传给 dn3;dn1 每传一个 packet 会放入一个应答队列等待应答;
(8) 当一个 block 传输完成之后,客户端再次请求namenode 上传第二个 block 的服务器。(重复执行3-7步)
1.2. 网络拓扑
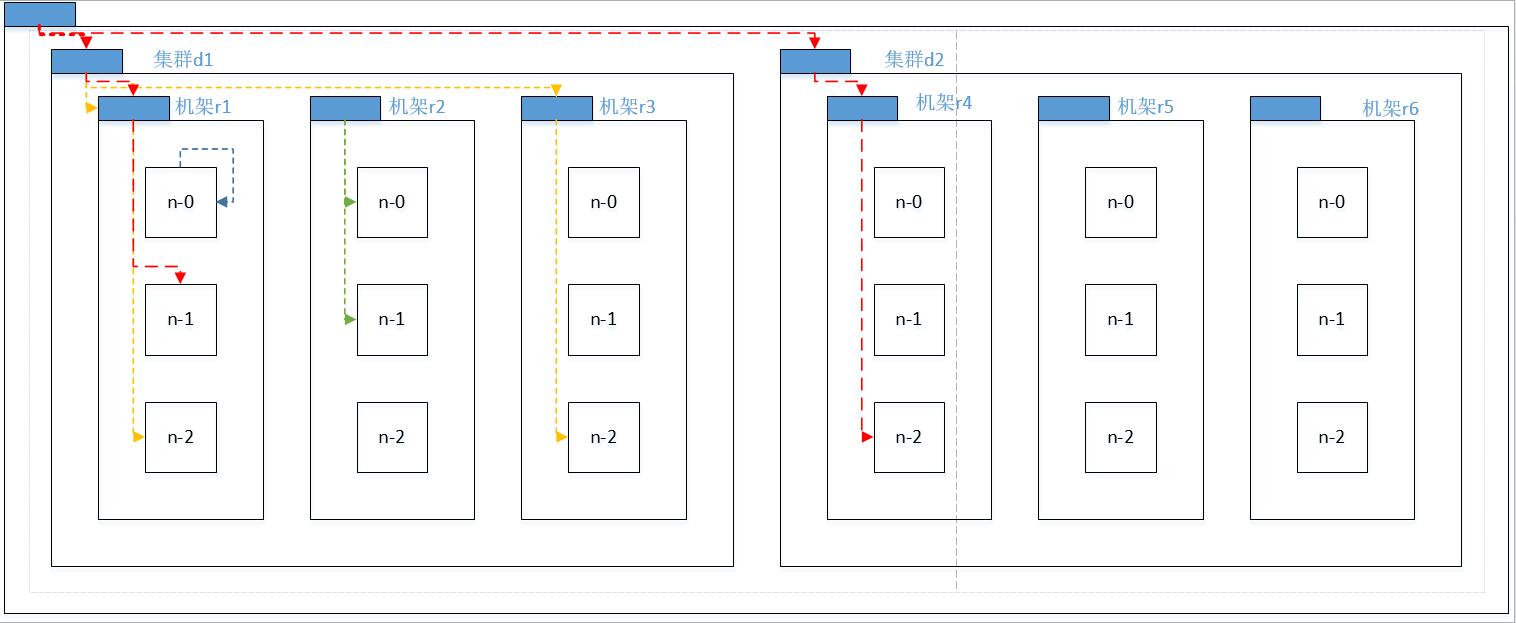
在本地网络中,两个节点被称为“彼此近邻”是什么意思?在海量数据处理中,其主要限制因素是节点之间数据的传输速率——带宽很稀缺。这里的想法是将两个节点间的带宽作为距离的衡量标准。
节点距离:两个节点到达最近的共同祖先的距离总和。
例如,假设有数据中心 d1 机架 r1 中的节点 n1。该节点可以表示为 /d1/r1/n1。利用这种标记,这里给出四种距离描述。
Distance(/d1/r1/n1, /d1/r1/n1)=0(同一节点上的进程)
Distance(/d1/r1/n1, /d1/r1/n2)=2(同一机架上的不同节点)
Distance(/d1/r1/n1, /d1/r3/n2)=4(同一数据中心不同机架上的节点)
Distance(/d1/r1/n1, /d2/r4/n2)=6(不同数据中心的节点)
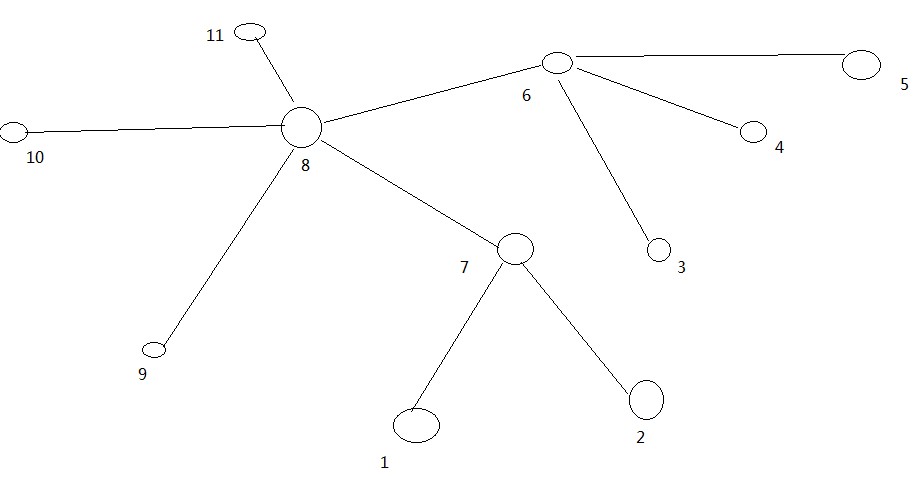
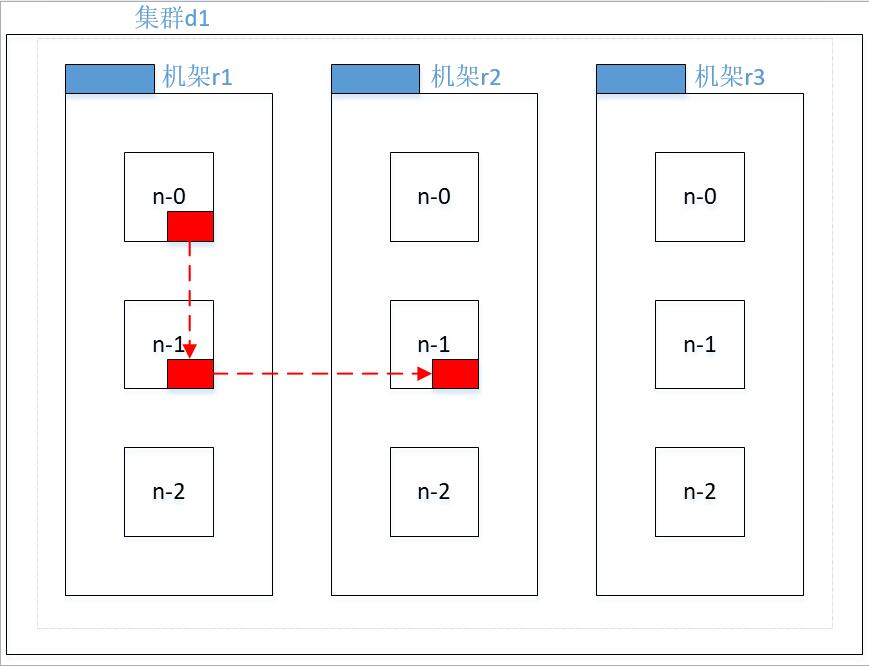
大家可以算算下面两个节点间的距离
1.3. 机架感知
(1) 官方 ip 地址:
http://hadoop.apache.org/docs/r2.7.3/hadoop-project-dist/hadoop-common/RackAwareness.html
http://hadoop.apache.org/docs/r2.7.3/hadoop-project-dist/hadoop-hdfs/HdfsDesign.html#Data_Replication
(2) 低版本 Hadoop 副本节点选择
第一个副本在 client 所处的节点上。如果客户端在集群外,随机选一个。
第二个副本和第一个副本位于不相同机架的随机节点上。
第三个副本和第二个副本位于相同机架,节点随机。
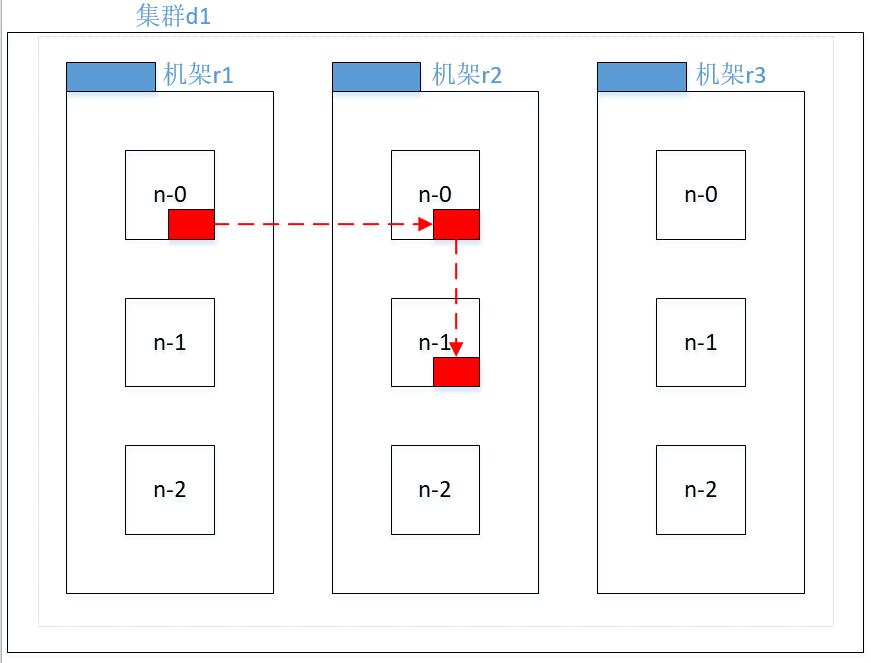
(3) Hadoop2.7.2 副本节点选择
第一个副本在 client 所处的节点上。如果客户端在集群外,随机选一个。
第二个副本和第一个副本位于相同机架,随机节点。
第三个副本位于不同机架,随机节点。
2. HDFS 读数据流程
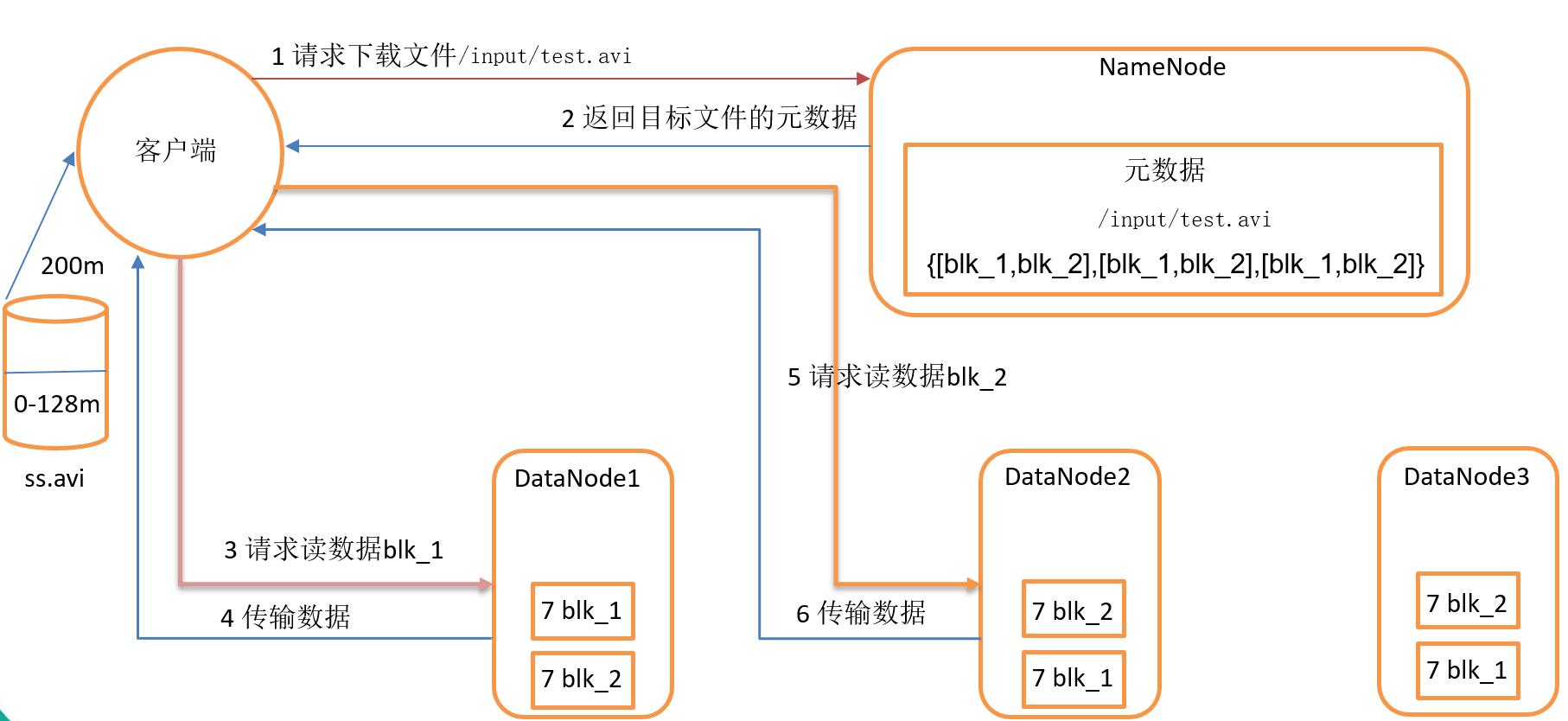
(1) 客户端向 namenode 请求下载文件,namenode 通过查询元数据,找到文件块所在的 datanode 地址;
(2) 挑选一台 datanode(就近原则,然后随机)服务器,请求读取数据;
(3) datanode 开始传输数据给客户端(从磁盘里面读取数据放入流,以 packet 为单位来做校验);
(4) 客户端以 packet 为单位接收,先在本地缓存,然后写入目标文件。
3. 一致性模型
(1) debug 调试如下代码
@Test
public void writeFile() throws Exception{
// 1 创建配置信息对象
Configuration configuration = new Configuration();
fs = FileSystem.get(configuration);
// 2 创建文件输出流
Path path = new Path("hdfs://hadoop01:8020/user/hello.txt");
FSDataOutputStream fos = fs.create(path);
// 3 写数据
fos.write("hello".getBytes());
// 4 一致性刷新
fos.hflush();
fos.close();
}(2) 总结
写入数据时,如果希望数据被其他 client 立即可见,调用如下方法
FsDataOutputStream. hflush (); //清理客户端缓冲区数据,被其他 client 立即可见
本文为原创文章,如果对你有一点点的帮助,别忘了点赞哦!比心!如需转载,请注明出处,谢谢!

















 171
171

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









