



 本文探讨了深度学习在机器翻译领域的应用,特别是通过seq2seq模型实现不同语言间的转换。文章详细介绍了编码器和解码器的工作原理,并讨论了注意力模型如何改善翻译质量。
本文探讨了深度学习在机器翻译领域的应用,特别是通过seq2seq模型实现不同语言间的转换。文章详细介绍了编码器和解码器的工作原理,并讨论了注意力模型如何改善翻译质量。

如果说深度学习在自然语言的有比较大的进步的话,机器翻译可能算一个。
传统机器学习或者专家系统,在机器翻译上折腾好几十年,好多语言学家,整理了各种语言学,形式逻辑规则,但作用有限。因为人类的语言实在是太复杂,而且本身还在不断的演化当中。
直到大家放弃语言规则,投入统计学方向,比如n-gram,cbow等,就是统计词语序列符合人类语言的最大概率。看似简单,但效果超好。
既然是统计问题,那深度学习就可以派上用场,尤其是序列预测问题。对于双语之间的翻译,其实就是寻找两个序列之间的对应关系。而这两种对应关系,还必须符合各自语种的表达习惯。这里的模型就是seq2seq。
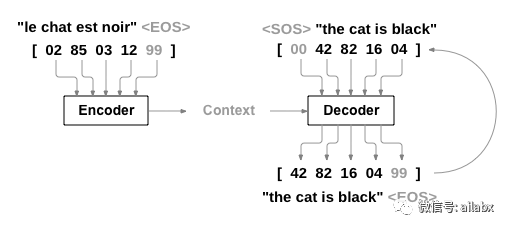
输入一句法文,输出对应的英文翻译。
如上图所示,翻译过程就是将原文句子编码,信息在hidden的context里,然后经过解码器输出。
编码器就是一个很“传统”的1层的GRU。先把input做词嵌入,然后过gru输出output和hidden。
#编码器
class EncoderRNN(nn.Module):
#这是为何没有embedding_size,而直接=hidden_size是必须的吗?
#另外gru的hidden就一个?
def __init__(self, vocab_size, hidden_size, n_layers=1):
super(EncoderRNN, self).__init__()
self.n_layers = n_layers
self.hidden_size = hidden_size
self.embedding = nn.Embedding(vocab_size, hidden_size)
self.gru = nn.GRU(hidden_size, hidden_size)
def forward(self, input, hidden):
embedded = self.embedding(input).view(1, 1, -1)
output = embedded
for i in range(self.n_layers):
output, hidden = self.gru(output, hidden)
return output, hidden
def initHidden(self):
result = Variable(torch.zeros(1, 1, self.hidden_size))
return result
解码器的结构也类似,就是input是编码之后的output,所以输入维度是hidden_size。
class DecoderRNN(nn.Module):
def __init__(self, hidden_size, output_size, n_layers=1):
super(DecoderRNN, self).__init__()
self.n_layers = n_layers
self.hidden_size = hidden_size
self.embedding = nn.Embedding(output_size, hidden_size)
self.gru = nn.GRU(hidden_size, hidden_size)
self.out = nn.Linear(hidden_size, output_size)
self.softmax = nn.LogSoftmax()
def forward(self, input, hidden):
output = self.embedding(input).view(1, 1, -1)
for i in range(self.n_layers):
output = F.relu(output)
output, hidden = self.gru(output, hidden)
output = self.softmax(self.out(output[0]))
return output, hidden
def initHidden(self):
result = Variable(torch.zeros(1, 1, self.hidden_size))
return result
细心的同学可能看出来,这里传递过来的上下文是整句的。但对于某一个词的翻译,所需要的信息是不一样的。这就有了注意力模型。
#带注意力模型的GRU解码器
class AttnDecoderRNN(nn.Module):
def __init__(self, hidden_size, output_size, n_layers=1, dropout_p=0.1, max_length=MAX_LENGTH):
super(AttnDecoderRNN, self).__init__()
self.hidden_size = hidden_size
self.output_size = output_size
self.n_layers = n_layers
self.dropout_p = dropout_p
self.max_length = max_length
self.embedding = nn.Embedding(self.output_size, self.hidden_size)
self.attn = nn.Linear(self.hidden_size * 2, self.max_length)
self.attn_combine = nn.Linear(self.hidden_size * 2, self.hidden_size)
self.dropout = nn.Dropout(self.dropout_p)
self.gru = nn.GRU(self.hidden_size, self.hidden_size)
self.out = nn.Linear(self.hidden_size, self.output_size)
def forward(self, input, hidden, encoder_output, encoder_outputs):
embedded = self.embedding(input).view(1, 1, -1)
embedded = self.dropout(embedded)
#这里计算注意力权重
attn_weights = F.softmax(
self.attn(torch.cat((embedded[0], hidden[0]), 1)))
attn_applied = torch.bmm(attn_weights.unsqueeze(0),
encoder_outputs.unsqueeze(0))
output = torch.cat((embedded[0], attn_applied[0]), 1)
output = self.attn_combine(output).unsqueeze(0)
#下面仍然到GRU/log_softmax
for i in range(self.n_layers):
output = F.relu(output)
output, hidden = self.gru(output, hidden)
output = F.log_softmax(self.out(output[0]))
return output, hidden, attn_weights
def initHidden(self):
result = Variable(torch.zeros(1, 1, self.hidden_size))
return result
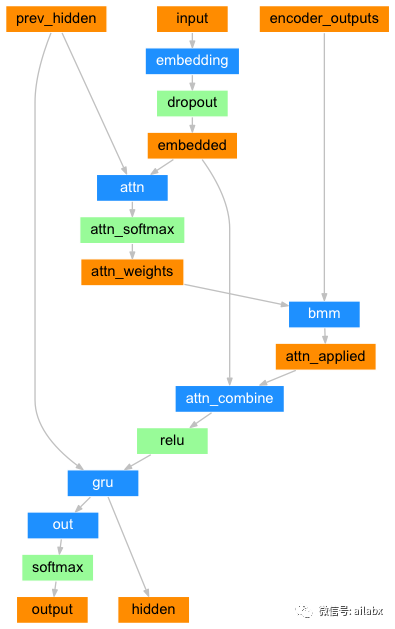
网络结构如上,具体注意力模型的原理,明天继续分析。
关于作者:魏佳斌,互联网产品/技术总监,北京大学光华管理学院(MBA),特许金融分析师(CFA),资深产品经理/码农。偏爱python,深度关注互联网趋势,人工智能,AI金融量化。致力于使用最前沿的认知技术去理解这个复杂的世界。
扫描下方二维码,关注:AI量化实验室(ailabx),了解AI量化最前沿技术、资讯。

















 4278
4278

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









