



 本文详细解析了Scrapy爬虫项目的模块构成,包括初始化配置、数据结构定义、爬虫编写及数据抓取过程。阐述了从URL请求到数据处理的完整流程,以及Request与Item在队列中的循环与传递机制。
本文详细解析了Scrapy爬虫项目的模块构成,包括初始化配置、数据结构定义、爬虫编写及数据抓取过程。阐述了从URL请求到数据处理的完整流程,以及Request与Item在队列中的循环与传递机制。
scrapy项目模块简单分析
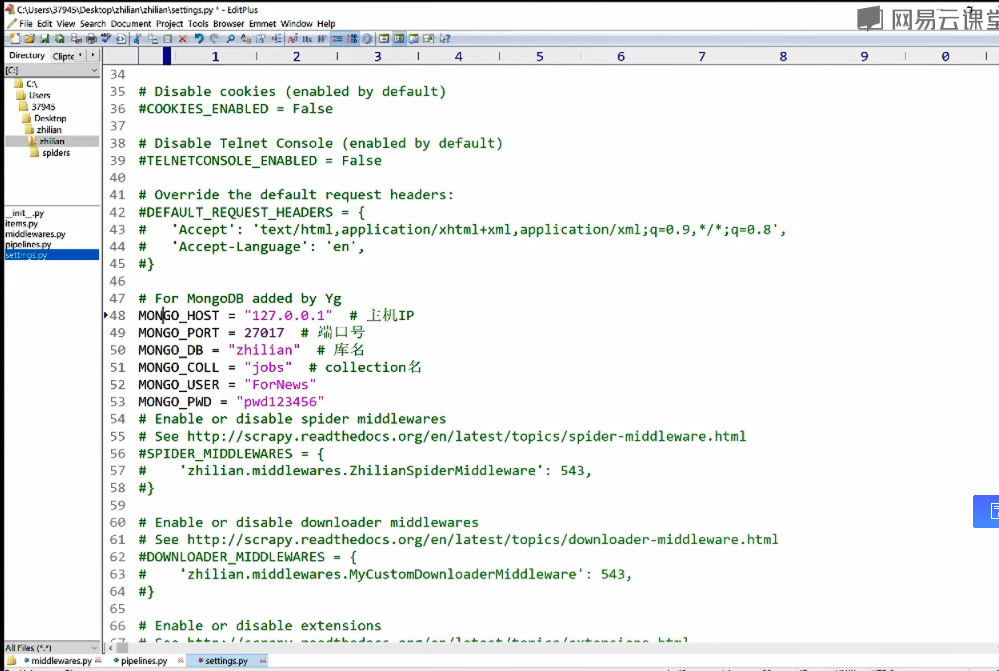
1.__init__配置初始化,比如配置数据库
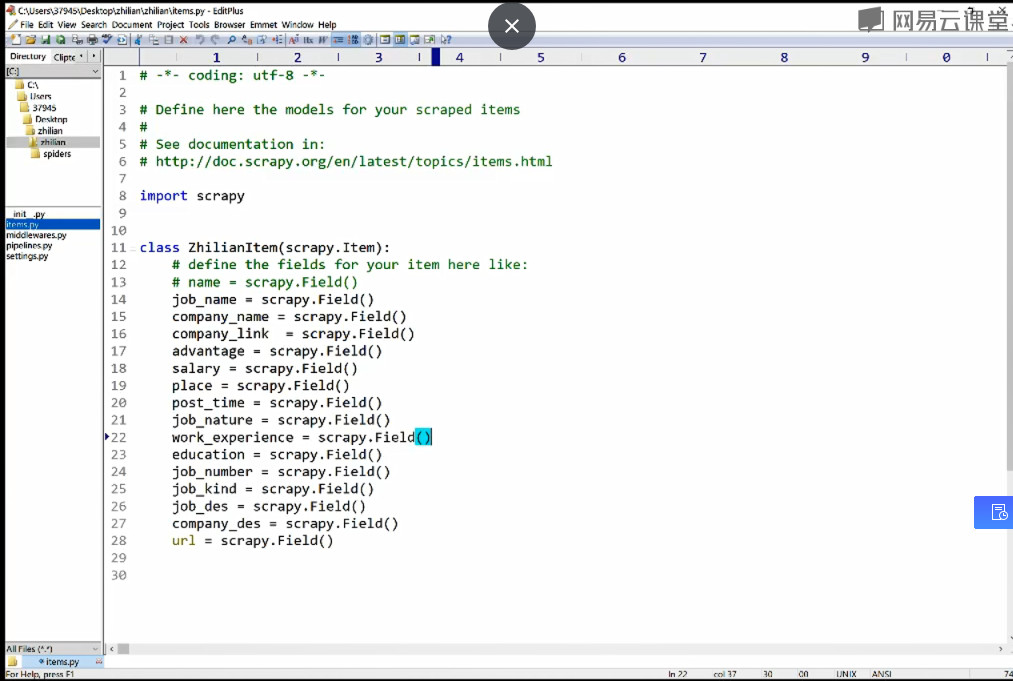
2.Items定义数据结构
3.Spider-编写爬虫程序(名称、域名、从哪个url开始爬取数据)
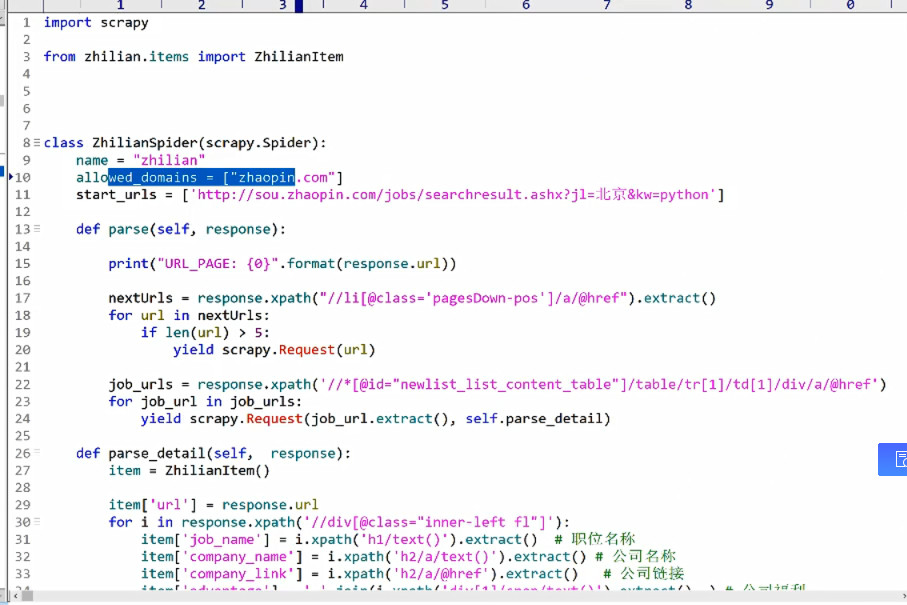
scrapy.Request(job_url.extract(), self.parse_detail)
写回调函数,当你有了url时,回调parse_detail;
4.编写parse函数,爬取数据
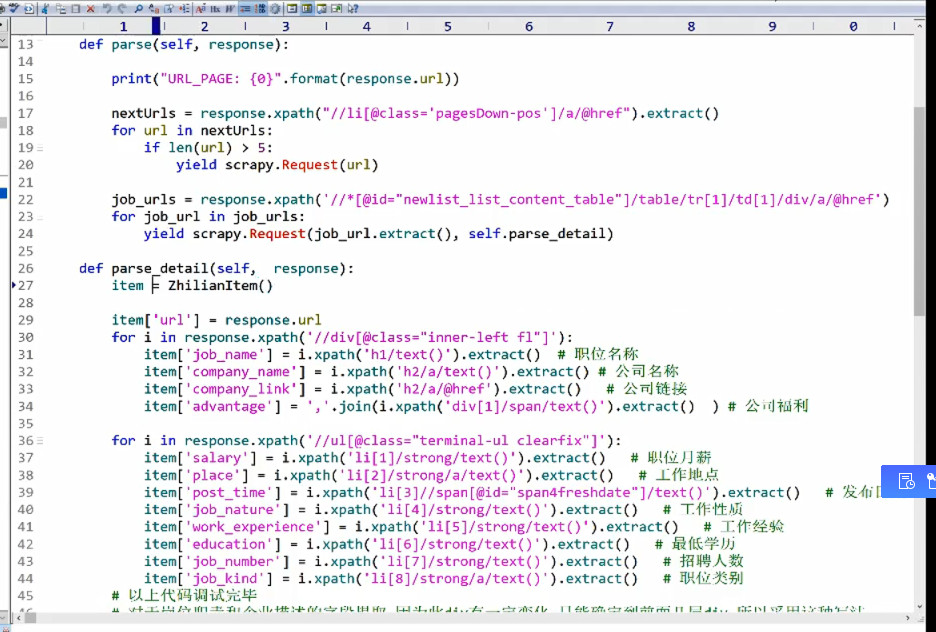
parse函数,用yield返回request/ item.
request进入到队列里面重新进行爬虫循环;
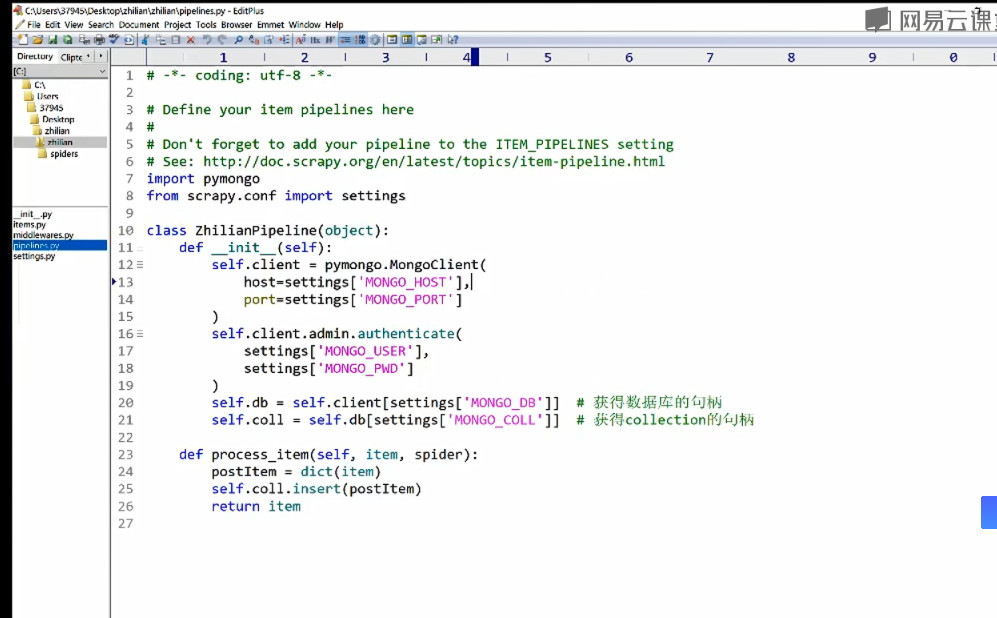
item丢到pipeline处理。

















 64万+
64万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









