






 本文介绍了Netflix的大数据处理生态系统及Spark在其平台上的作用。详细探讨了Netflix采用的数据流和数据管道架构,以及Spark如何提高数据处理效率。此外,还包括使用Spark进行数据仓库和分析的实际案例。
本文介绍了Netflix的大数据处理生态系统及Spark在其平台上的作用。详细探讨了Netflix采用的数据流和数据管道架构,以及Spark如何提高数据处理效率。此外,还包括使用Spark进行数据仓库和分析的实际案例。
更多精彩内容参见云栖社区大数据频道https://yq.aliyun.com/big-data;此外,通过Maxcompute及其配套产品,低廉的大数据分析仅需几步,详情访问https://www.aliyun.com/product/odps。
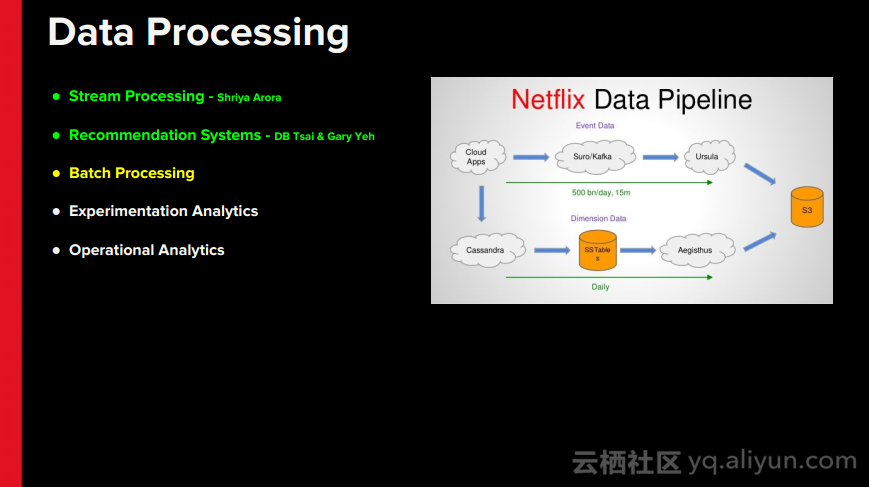
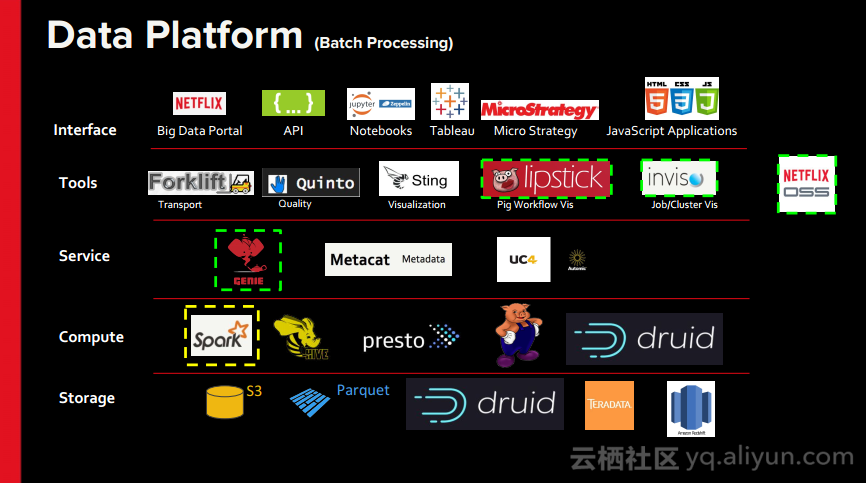
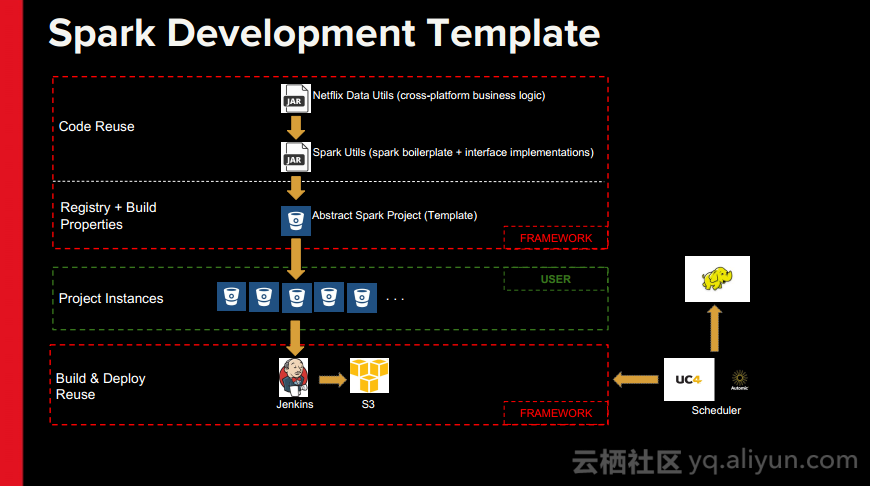
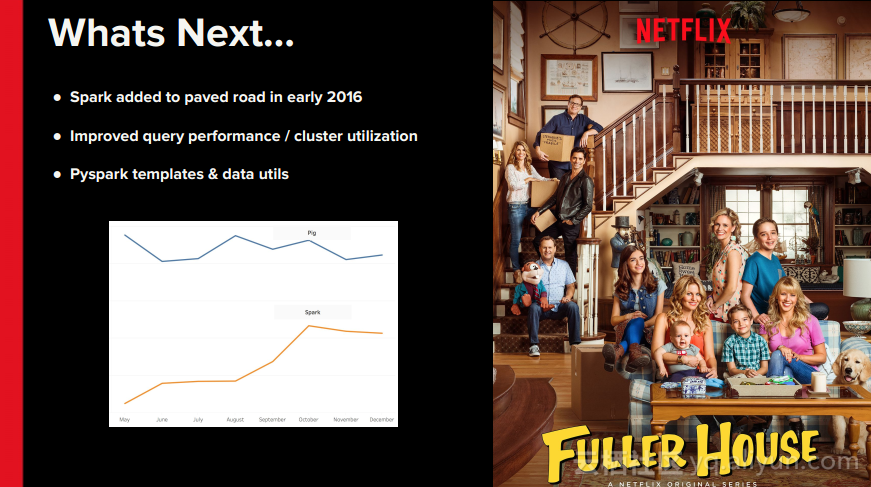
本讲义出自Rohan Sharma在Spark Summit East 2017上的演讲,主要介绍了Netflix的大数据处理生态系统以及Spark在该平台发挥的作用,并讨论了Netflix使用的数据流以及数据管道架构以及Spark如何帮助Netflix在数据处理过程中提升效率,最后还分享了一些关于使用Spark的数据仓库以及分析案例。






























 2325
2325

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









