






 本文探讨了机器学习中L1正则化与L2正则化的不同之处,通过引入不同的先验分布(高斯分布与拉普拉斯分布),解释了这两种正则化方法如何影响权重系数,指出L1正则化倾向于产生稀疏解并能用于特征选择,而L2正则化则使权重更加均匀。
本文探讨了机器学习中L1正则化与L2正则化的不同之处,通过引入不同的先验分布(高斯分布与拉普拉斯分布),解释了这两种正则化方法如何影响权重系数,指出L1正则化倾向于产生稀疏解并能用于特征选择,而L2正则化则使权重更加均匀。
这里讨论机器学习中L1正则和L2正则的区别。
在线性回归中我们最终的loss function如下:
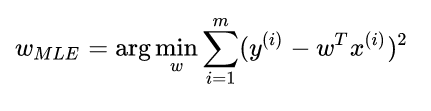
那么如果我们为w增加一个高斯先验,假设这个先验分布是协方差为  的零均值高斯先验。我们在进行最大似然:
的零均值高斯先验。我们在进行最大似然:
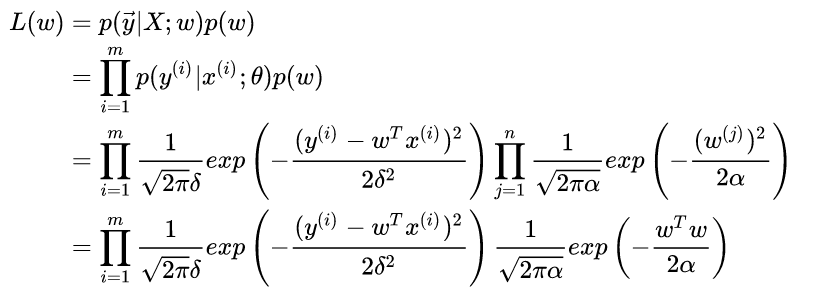
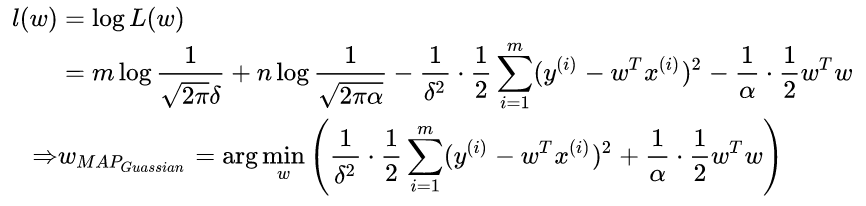
这个东西不就是我们说的加了L2正则的loss function吗?
同理我们如果为w加上拉普拉斯先验,就可以求出最后的loss function也就是我们平时说的加了L1正则:
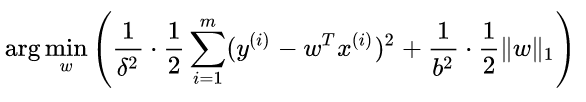
因为拉普拉斯的分布相比高斯要更陡峭,它们的分布类似下图,红色表示拉普拉斯,黑色表示高斯
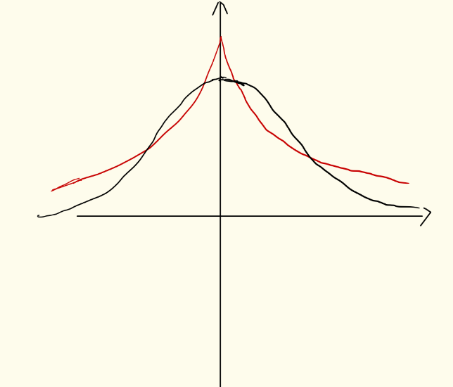
可以看出拉普拉斯的小w的数目要比高斯的多,w的分布陡峭,而高斯的w分布较为均匀。也就是说,l1正则化更容易获得稀疏解,还可以挑选重要特征。l2正则有均匀化w的作用。

















 3080
3080

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









