



 本文详细分析了一起由SQL*Netvectordatafromclient事件导致的性能抖动问题,通过使用orabbix进行实时监控、ASH报告和数据库日志分析,最终定位到scheduler job作为问题源头。文章还提供了排查方法和解决方案,帮助读者理解并解决类似问题。
本文详细分析了一起由SQL*Netvectordatafromclient事件导致的性能抖动问题,通过使用orabbix进行实时监控、ASH报告和数据库日志分析,最终定位到scheduler job作为问题源头。文章还提供了排查方法和解决方案,帮助读者理解并解决类似问题。
可以看到在早上的七点左右的时候还是有一些明显的性能抖动,DB time会瞬间提高。
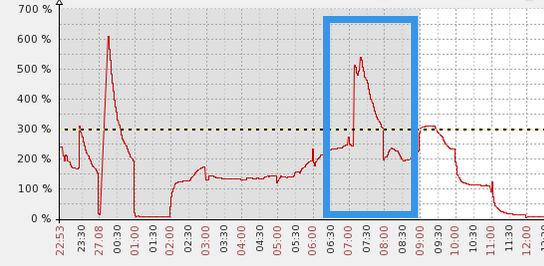
这对于一个OLAP的系统来说还是有些不正常的。
并行session的情况如下,可以看到在问题发生的时间段里,产生了大量的并行session.
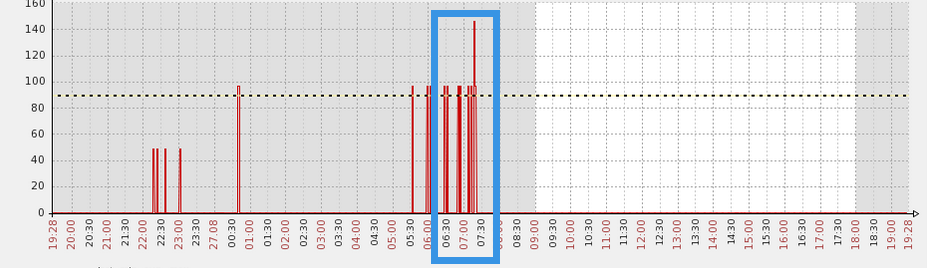
而且同时我也收到了orabbix的告警邮件。
监控项目: Session Active:153
*UNKNOWN*:*UNKNOWN*
------------------------------------
故障时间:2015.08.27-07:22:04
所以这个问题还是需要关注一下,这种情况就犹如给一个静坐的人用针突然扎一下,会出现很明显的性能抖动。
首先为了进一步验证,得到了在快照时间内的负载信息,可以看到在问题发生的时间内DB time还是蛮高的。
BEGIN_SNAP END_SNAP SNAPDATE DURATION_MINS DBTIME
---------- ---------- --------------------------------- ----------
36343 36344 27 Aug 2015 04:00 60 85
36344 36345 27 Aug 2015 05:00 60 118
36345 36346 27 Aug 2015 06:00 60 150
36346 36347 27 Aug 2015 07:00 60 180
36347 36348 27 Aug 2015 08:00 60 137
36348 36349 27 Aug 2015 09:00 60 140
36349 36350 27 Aug 2015 10:00 60 67
36350 36351 27 Aug 2015 11:00 60 8
所以说得到了上面的信息,能够让我们更加清楚问题的背景和基本情况。
查看alert日志,在问题发生的时间段里,没有看到其它异常的信息。
Thu Aug 27 00:07:08 2015
Archived Log entry 63315 added for thread 1 sequence 688962 ID 0xa4527950 dest 1:
Thu Aug 27 00:07:23 2015
LNS: Standby redo logfile selected for thread 1 sequence 688964 for destination LOG_ARCHIVE_DEST_3
Thu Aug 27 00:07:32 2015
Archived Log entry 63317 added for thread 1 sequence 688963 ID 0xa4527950 dest 1:
Thu Aug 27 00:07:38 2015
Thread 1 advanced to log sequence 688965 (LGWR switch)
所以从数据库层面来说,可能没有什么明显的活动。
但是问题不可能无中生有,我们怎么去找到问题的根源呢,为了更加精确的定位问题,我们需要借助于ASH来还原那个时间段的问题情况。
为了排除Orabbix监控的延迟,我抓取的时间范围略大了些,是7分钟内的ash.
得到的报告如下,可以看到在问题发生的时间段内,取样数也确实蛮高的。
| Sample Time | Data Source | |
|---|---|---|
| Analysis Begin Time: | 27-Aug-15 07:15:00 | V$ACTIVE_SESSION_HISTORY |
| Analysis End Time: | 27-Aug-15 07:22:05 | V$ACTIVE_SESSION_HISTORY |
| Elapsed Time: | 7.1 (mins) | |
| Sample Count: | 177 | |
| Average Active Sessions: | 0.42 | |
| Avg. Active Session per CPU: | 0.05 |
top user event为:
| Event | Event Class | % Event | Avg Active Sessions |
|---|---|---|---|
| SQL*Net vector data from client | Network | 39.55 | 0.16 |
| Standby redo I/O | System I/O | 2.26 | 0.01 |
| RFS write | System I/O | 1.13 | 0.00 |
对于等待事件SQL*Net vector data from client可以参考 Doc ID 1311281.1
说法是可以忽略。我们可以先把这个问题放一放,来通过其他的思路来分析一下。
首先数据库的负载突然提高,如果单纯是因为备库的原因,为什么不是其它时间段内,白天的时候没有任何报警。白天的负载更高,更应该出现问题才对。
所以这种情况应该还是有一定的触发条件,但是查看了crontab也没有什么发现,那么很可能就是scheduler相关的。
我们怎么来推论呢。
首先的考虑就是后台的scheduler,结果查看还是默认的晚上10点左右,所以到早上的那个时间段应该不会有直接的影响。
那么scheduler狠可能就是用户自定义的。
限定在问题时间段内,得到的信息如下
select owner,job_name,last_start_date,end_date,NEXT_RUN_DATE from dba_scheduler_jobs where last_start_date between to_timestamp('2015-08-27 05:00:00','yyyy-mm-dd hh24:mi:ss') and to_timestamp('2015-08-27 08:00:00','yyyy-mm-dd hh24:mi:ss')
OWNER JOB_NAME LAST_START_DATE
------- -------------- ---------------------------------------------
APP_TEST SYN_D 27-AUG-15 07.11.00.002185 AM ASIA/SHANGHAI
APP_TEST SYN_E 27-AUG-15 06.15.00.809059 AM ASIA/SHANGHAI
APP_TEST SYN_F 27-AUG-15 06.12.05.312974 AM +08:00
APP_TEST SYN_G 27-AUG-15 05.00.40.797679 AM ASIA/SHANGHAI
可以看到确实还是有scheduler job在运行,而且时间也基本是相符的。
LOG_ID LOG_DATE OWNER JOB_NAME STATUS
---------- ---------------------------------------- ---------- -----------------------------------
241839 27-AUG-15 07.30.00.140947 AM +08:00 TEST_APP SYN_D SUCCEEDED
241836 27-AUG-15 07.05.46.398691 AM +08:00 TEST_APP SYN_E SUCCEEDED
241840 27-AUG-15 07.30.01.319849 AM +08:00 TEST_APP SYN_F SUCCEEDED
241841 27-AUG-15 07.35.00.912152 AM +08:00 TEST_APP SYN_G SUCCEEDED
从以上的信息可以猜想可能是scheduler job引发的大量并行session的情况,我们后续继续进行跟踪,揭开问题的真实面纱。

















 14
14

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









