







 本文介绍了SparkStreaming的编程步骤,包括创建StreamingContext、设置InputDStream、应用transformation和output操作,以及启动和停止程序的注意事项。重点强调了Receiver线程与处理线程的数量配置以及在不同环境中的使用要求。
本文介绍了SparkStreaming的编程步骤,包括创建StreamingContext、设置InputDStream、应用transformation和output操作,以及启动和停止程序的注意事项。重点强调了Receiver线程与处理线程的数量配置以及在不同环境中的使用要求。
(1)StreamingContext
与spark core的编程类似,在编写SparkStreaming的程序时,也需要一个通用的编程入口----StreamingContext。
StreamingContext的创建:
object StreamingContextTest {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setAppName("SCTest").setMaster("local[4]")
val streamingContext = new StreamingContext(sparkConf, Seconds(2))
}
}注意: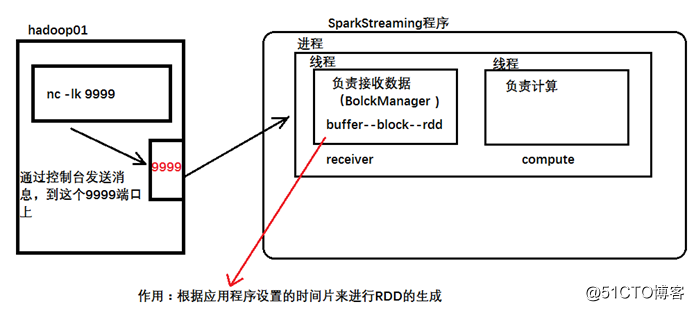
如果在计算的时候,指定--master时 使用的是local 并且只指定了一个线程,那么只有receiver线程工作,计算的线程不会工作,所以在指定线程数的时候,最少指定2个。
(2)通过输入源创建InputDStream:
在构建好StreamingContext之后,首先我们要读取数据源的数据进行实时处理:
InputDStreams指的是从数据流的源头接收的输入数据流,每个 InputDStream 都关联一个 Receiver 对象,该 Receiver 对象接收数据源传来的数据并将其保存在内存中以便后期 Spark 处理。
Spark Streaming 提供两种原生支持的流数据源和自定义的数据源:
- 直接通过 StreamingContext API 创建,例如文件系统(本地文件系统及分布式文件系统)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 968
968

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









