







 本文详细介绍了如何使用Spark Streaming从Kafka中读取数据,包括两种集成方式:基于Receiver的方法和没有Receiver的直接方式。针对每种方法,文章提供了相关代码示例和注意事项,讨论了它们的优缺点,如并行度、效率和数据可靠性。同时,还提到了监控和优化Spark Streaming应用程序的策略。
本文详细介绍了如何使用Spark Streaming从Kafka中读取数据,包括两种集成方式:基于Receiver的方法和没有Receiver的直接方式。针对每种方法,文章提供了相关代码示例和注意事项,讨论了它们的优缺点,如并行度、效率和数据可靠性。同时,还提到了监控和优化Spark Streaming应用程序的策略。
官网:Spark Streaming + Kafka Integration Guide
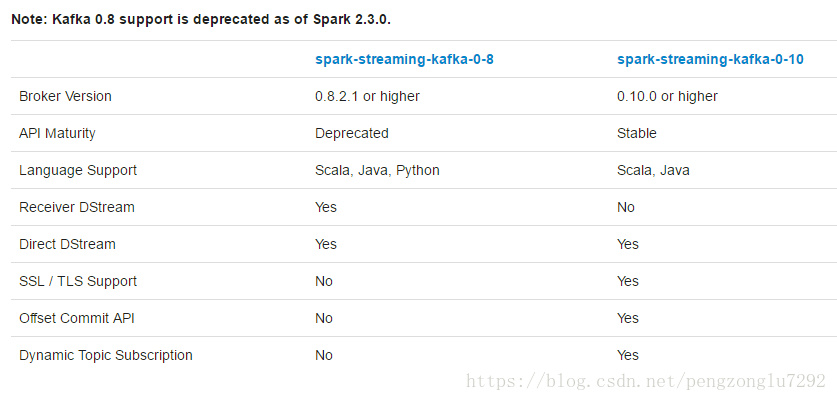
由于kafka在0.8和1.0之间引入了新版本的Consumer API,所以这儿有两个独立的集成方案。0.8版本的集成方案可以兼容0.9或1.0的kafka,而1.0版本的集成方案则不可以兼容1.0以下版本的kafka。
---------------------------------------------------------------------------------------------------------------
我们以下以spark-streaming-kafka-0-8作为演示。(spark-streaming-kafka-0-10可以参考)
--------------------------------------------------------------------------------------------------------------
1、搭建kafka环境:见本人博客 kafak介绍及部署。
2、将kafka与spark做集成,有两种方式,以下分别作介绍。
-----------------------------------------------------------------------------------------------------------------
一、基于Receiver的方法(Receiver-based Approach)
使用一个Receiver来接收数据,这个Receiver实现了kafka的高级别Consumer API,Receiver从Kafka这儿接收数据并储存在Spark的Executor中,作业运行后由Spark Streaming来处理数据。但是,在默认的配置下当任务失败时这种方式会丢失数据(可参考Receiver Reliablitily),为了保证数据的零丢失,你可以在Spark Streaming中添加Write Ahead Logs(在spark1.2引入)。这可以同步地将所有接收到的kafka数据保存在分布式文件系统的Write Ahead Logs中。接下来展示如何使用这种方法。
注意点:
A。kafka的topic中的分区与RDD中的分区没有关系。如果你增大KafkaUtils.createStream()的第四个参数的值,只是增大了Receiver的Topic使用的线程数,并没有增加Spark处理数据的并行度。
B。可以用不同的Group和Topic创建多个kafka input DStream,以便使用多个Receiver并行接收数据。
C。如果你启用了分布式文件系统的Write Ahead Logs机制,接收到的数据就以多副本的方式存在log中。则Input DStream则可以采用StorageLevel.MEMORY_AND_DISK_SER方式(that is, use KafkaUtils.createStream(..., StorageLevel.MEMORY_AND_DISK_SER))。
1、连接
添加依赖
<dependency>
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











