






 本文详细介绍了K-means聚类算法的工作原理,包括选取初始中心、分配数据点、更新聚类中心以及收敛判断等步骤。通过自定义实现及使用sklearn库进行对比,深入解析了K-means算法的实现细节。
本文详细介绍了K-means聚类算法的工作原理,包括选取初始中心、分配数据点、更新聚类中心以及收敛判断等步骤。通过自定义实现及使用sklearn库进行对比,深入解析了K-means算法的实现细节。
K-means是一个反复迭代的过程,算法分为四个步骤:
1) 选取数据空间中的K个对象作为初始中心,每个对象代表一个聚类中心;
2) 对于样本中的数据对象,根据它们与这些聚类中心的欧氏距离,按距离最近的准则将它们分到距离它们最近的聚类中心(最相似)所对应的类;
3) 更新聚类中心:将每个类别中所有对象所对应的均值作为该类别的聚类中心,计算目标函数的值;
4) 判断聚类中心和目标函数的值是否发生改变,若不变,则输出结果,若改变,则返回2)
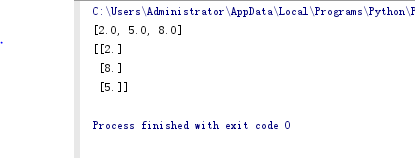
1 import numpy as np 2 import random 3 import math 4 from sklearn.cluster import KMeans 5 6 def km(dataset,k): 7 random.sample(dataset,k)#打乱顺序 8 ran = [dataset[i] for i in range(k)] 9 charge = True 10 while charge: 11 get_fen = [[] for i in range(k)] 12 for i in dataset: 13 temp = np.array([],dtype=int) 14 for j in ran: 15 temp = np.append(temp,Euclidean(i,j)) 16 get_fen[temp.argmin()].append(i) 17 temp = np.array([],dtype=int) 18 temp_ran = [round(np.median(np.array(get_fen[i]))) for i in range(len(get_fen))] 19 if ran == temp_ran: 20 charge = False 21 ran = temp_ran 22 print(ran) 23 def Euclidean(start,end): 24 #计算欧几里得距离 25 result = math.sqrt((start-end)**2) 26 return result 27 28 def sklearn_use(dataset,k): 29 est = KMeans(n_clusters=k) 30 est.fit(dataset) 31 print(est.cluster_centers_) 32 #print(est.predict(dataset)) 33 34 if __name__ == "__main__": 35 a = [i for i in range(1,10)] 36 km(a,3)#自编 假的kmeans 37 a = np.array(a).reshape(len(a),1) 38 sklearn_use(a,3)#调用sklearn

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









