






 本文精选了24个涵盖不同难度级别的数据科学项目,包括初级的Iris数据集、中级的BlackFriday数据集和高级的ImageNet数据集等。所有项目均提供免费数据集与教程,有助于学习者提升技能。
本文精选了24个涵盖不同难度级别的数据科学项目,包括初级的Iris数据集、中级的BlackFriday数据集和高级的ImageNet数据集等。所有项目均提供免费数据集与教程,有助于学习者提升技能。
数据科学项目为你在这个领域的深入研究提供了一个基础。通过实际应用,你不仅可以学习数据科学,也能够写在简历中提升你的资历。在这上边花费的时间越多,你学到的知识就越多。
本文精选了24个数据科学项目,并囊括了各个领域和各种不同大小的数据集。另外,所有的数据集都是开源、可免费获取的。

初级——这部分的数据集很容易处理,使用基础的回归/分类算法就可以处理这些数据集。并且,这些数据集有足够的教程供你学习。
中级——略微有点难度。包含了需要使用有点难度的模式识别技能来处理的大中型数据集。另外,特征工程在这里可以发挥作用了。
高级——包括神经网络、深度学习、推荐系统及高维数据等。
初级
1.Iris Data数据集(花的类别识别)

Iris Data Set可能是模式识别领域学习分类技术最基本入门级的数据集,适合初学者。该数据集里面包含了150行4列个数据。
2.Loan Prediction 数据集(贷款预测)

它是保险领域最常引用的一个数据集。利用这个数据集,你可以充分体验到如何处理保险公司的数据,包括会遇到哪些挑战、需要什么策略、哪些变量会影响结果等。这是一个分类问题,数据集包含615行13列个数据。
3. Bigmart Sales 数据集(零售业销售)

零售业是另一个充分利用数据分析优化商业流程的行业。我们可以利用数据科学对商品的放置、库存管理、定制供应、商品捆绑等任务进行巧妙的处理。该数据集包含了商店的交易数据,是一个回归问题,共包含8523行12列个数据。
问题:预测销量。
4.Boston Housing 数据集(波士顿房屋)

这是另一个模式识别领域较为常见的数据集,来自于波士顿的房地产业,是一个回归问题,数据集有506行14列个数据。这个数据集并不大,你可以尝试使用任何技术,而不用担心笔记本的内存不够。
问题:预测业主拥有房屋数量的中间值。
5. Time Series Analysis数据集(时间序列分析)
时间序列是数据科学中最常用的技术之一,具有广泛的应用:预测天气预报、预测销售额、分析逐年趋势等。该数据集特定于时间序列,这里面临的挑战是预测交通方式。
问题:预测新的交通工具的交通。
6. Wine Quality数据集(酒质量)

这是初学者最常用的数据集之一,分成了2个数据集。在这个数据集上可以同时执行回归和分类任务——异常值检测、特征选择和不平衡数据。该数据集有4898行和12列个数据。
问题:预测酒的质量。
7.Turkiye Student Evaluation 数据集(学生课程评估)

该数据集基于学生填写不同课程的评估表,拥有不同的属性,包括出勤率、难度、分数等,是一个无监督学习问题。该数据集有5820行33列个数据。
问题:使用分类和聚类解决问题。
8.Heights and Weights 数据集(身高体重预测)
这是一个相当直接的回归问题,非常适合新手。该数据集有25,000行3列(索引、高度和权重)个数据。
问题:预测一个人的身高或体重。
中级
1. Black Friday数据集(黑色星期五)

这是一个包含零售商店记录的销售交易的经典数据集,可以扩展特征工程的技能,并从每天的购物经验中对其进行理解,是一个回归问题。该数据集有550,069行12列个数据。
问题:预测购买力。
2. Human Activity Recognition 数据集(人类活动识别)

该数据集通过带有嵌入式惯性传感器的智能手收集了30个实验者的记录,可用于分类问题。数据集有10,299行561列个数据。
问题:预测人类活动的类别。
3. Text Mining数据集(文本挖掘)

该数据集最初来自于2007年Siam文本挖掘竞赛,包括描述某些发生故障的航班的航空安全报告,是一个多分类和高维度问题。该数据集有21,519行30,438列个数据。
问题:根据文本标签对文本进行分类。
4. Trip History数据集(旅行历史)
此数据集来自美国的共享自行车服务。该数据集需要使用专业的数据处理技术,该数据集种的数据是从2010年第四季度开始按季度记录的。每个文件有7列是一个分类问题。
问题:预测用户的类别。
5. Million Song数据集(预测歌曲发行时间)

你知道数据科学现在也用于娱乐行业吗?这个数据集提出了一个回归任务,由515,345个观察值和90个变量组成。但是,这仅仅是原始数据库(约一百万首歌曲)中的一小部分。
问题:预测歌曲的发行时间。
6.Census Income数据集(预测人口收入)
这是一个经典的不平衡分类机器学习问题。现在,机器学习广泛应用于正被广泛用于解决不平衡问题,如癌症检测、欺诈检测等。该数据集有48,842行14列个数据。
问题:预测美国人的收入水平。
7. Movie Lens数据集(电影推荐系统)

用于构建推荐系统,该数据集是数据科学行业中最受欢迎的“数据集”之一,有不同大小的数据集。这里有一个较小的数据集,包含4,000部电影,6000个用户的100万个收视率。
问题:为用户推荐电影。
8. Twitter Classification数据集(预测推文)

Twitter数据已成为情感分析不可分割的一部分。该数据集大小为3MB,包含31,962条推文。
问题:预测哪些推文是令人讨厌的,哪些不是。
高级
1.识别数字的数据集

用于研究、分析和识别图像中的元素,这就是使用相机识别面部的技术,属于数字识别问题。该数据集有28,000个28*28大小的图像,总计31MB。
问题:从图像中识别数字。
2.城市声音分类

该项目旨在介绍常用的音频分类问题。该数据集由10个类别(包含来自8,732个城市声音的记录)组成。
问题:对音频进行分类。
3. Vox名人数据集
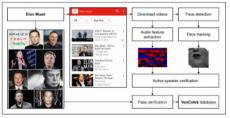
音频处理正迅速成为深度学习的重要领域,因此这是另一个具有挑战性的问题。此数据集收集了大型演讲者的演讲,并从YouTube中提取的名人的讲话。对于语音识别来说,这是一个很有趣的项目。该数据集包含1,251位名人发表的100,000条言论。
问题:找出声音属于哪个名人。
4. ImageNet数据集
ImageNet提供了各种各样的问题,包括对象检测、定位、分类和屏幕分析。 所有的图像都是免费的,你可以搜索任何类型的图像来构建项目。截至目前,该数据集拥有超过1500万张图片,大小超过140GB。
问题:要解决的问题会受下载图像的类型影响。
5.芝加哥犯罪数据集

现在,每个数据科学家都希望能够处理大型数据集,是一个多分类问题。该数据集在本地提供了处理大型数据集所需的实践经验。问题很简单,但数据管理是关键!这个数据集有6,000,000个观测值。
问题:预测犯罪类型。
6.印度演员年龄检测

对于任何深度学习爱好者来说,这是一个令人着迷的挑战。该数据集包含数千个印度演员的图像,用来预测其年龄。所有图像都是人工手动从视频帧中选取的,这就导致了尺度、姿势、表情、照明、年龄、分辨率、遮挡和化妆等的高度可变性。训练集中有19,906幅图像,测试集中有6,636幅图像。
问题:预测演员的年龄。
7.推荐引擎数据集

这是一项高级推荐系统挑战赛。在这个项目中,你会得到以前解决的程序和数据,以及解决特定问题的时间。作为一名数据科学家,你构建的模型将协助在线评委决定向用户推荐的下一级问题。
问题:根据用户的当前状态,预测解决问题所需要的时间。
资源:数据库
8. VisualQA数据集

VisualQA是一个包含图像的开放式问题数据集。这些问题需要理解计算机视觉和语言,这些问题有一个自动评估指标。数据集包含265,016张图片,每张图片3个问题,且每个问题有10个标记好的答案。
问题:使用深度学习回答有关图像的开放式问题。
总结
在上面列出的24个数据集中,你应该首先找到与自身技能相匹配的数据集进行实践和练习。比如说,假如你是一位初学者,请先从初级数据集开始实践,而不是直接从高级数据集开始练习。
以上为译文。
本文由北邮@爱可可-爱生活 老师推荐,阿里云云栖社区组织翻译。
文章原标题《24 Ultimate Data Science Projects To Boost Your Knowledge and Skills (& can be accessed freely)》,译者:Mags,审校:袁虎。
文章为简译,更为详细的内容,请查看原文。

















 2046
2046

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









