



 本文详细介绍使用多种回归模型预测波士顿房价的过程,包括数据预处理、模型选择及参数优化,最终确定XGBRegressor模型及其最佳参数。
本文详细介绍使用多种回归模型预测波士顿房价的过程,包括数据预处理、模型选择及参数优化,最终确定XGBRegressor模型及其最佳参数。
xgboost中文叫做极致梯度提升模型,官方文档链接:https://xgboost.readthedocs.io/en/latest/tutorials/model.html
GridSearchCV中文叫做交叉验证网格搜索,是sklearn库中用来搜索模型最优参数的常用方法。
2018年8月23日笔记
sklearn官方英文用户使用指南:https://sklearn.org/user_guide.html
sklearn翻译中文用户使用指南:http://sklearn.apachecn.org/cn/0.19.0/user_guide.html
0.打开jupyter notebook
不知道怎么打开jupyter notebook的朋友请查看我的入门指南文章:https://www.jianshu.com/p/bb0812a70246
1.准备数据
阅读此篇文章的基础是已经阅读了作者的上一篇文章《基于LinearRegression的波士顿房价预测》。
文章链接:https://www.jianshu.com/p/f828eae005a1
加载数据集中的预测目标值。
from sklearn.datasets import load_boston
y = load_boston().target
如果阅读过上一篇文章,读者应该知道特征提取后的数据处理主要是对数据进行分箱,从而产生新的字段。
将数据处理的过程封装成函数,代码如下:
def dataProcessing(df):
field_cut = {
'CRIM' : [0,10,20, 100],
'ZN' : [-1, 5, 18, 20, 40, 80, 86, 100],
'INDUS' : [-1, 7, 15, 23, 40],
'NOX' : [0, 0.51, 0.6, 0.7, 0.8, 1],
'RM' : [0, 4, 5, 6, 7, 8, 9],
'AGE' : [0, 60, 80, 100],
'DIS' : [0, 2, 6, 14],
'RAD' : [0, 5, 10, 25],
'TAX' : [0, 200, 400, 500, 800],
'PTRATIO' : [0, 14, 20, 23],
'B' : [0, 100, 350, 450],
'LSTAT' : [0, 5, 10, 20, 40]
}
df = df[load_boston().feature_names].copy()
cut_df = pd.DataFrame()
for field in field_cut.keys():
cut_series = pd.cut(df[field], field_cut[field], right=True)
onehot_df = pd.get_dummies(cut_series, prefix=field)
cut_df = pd.concat([cut_df, onehot_df], axis=1)
new_df = pd.concat([df, cut_df], axis=1)
return new_df
调用函数dataProcessing形成新的特征矩阵,代码如下:
import pandas as pd
df = pd.DataFrame(load_boston().data, columns=load_boston().feature_names)
new_df = dataProcessing(df)
print(new_df.columns)
new_df.head()
上面一段代码的运行结果如下图所示:
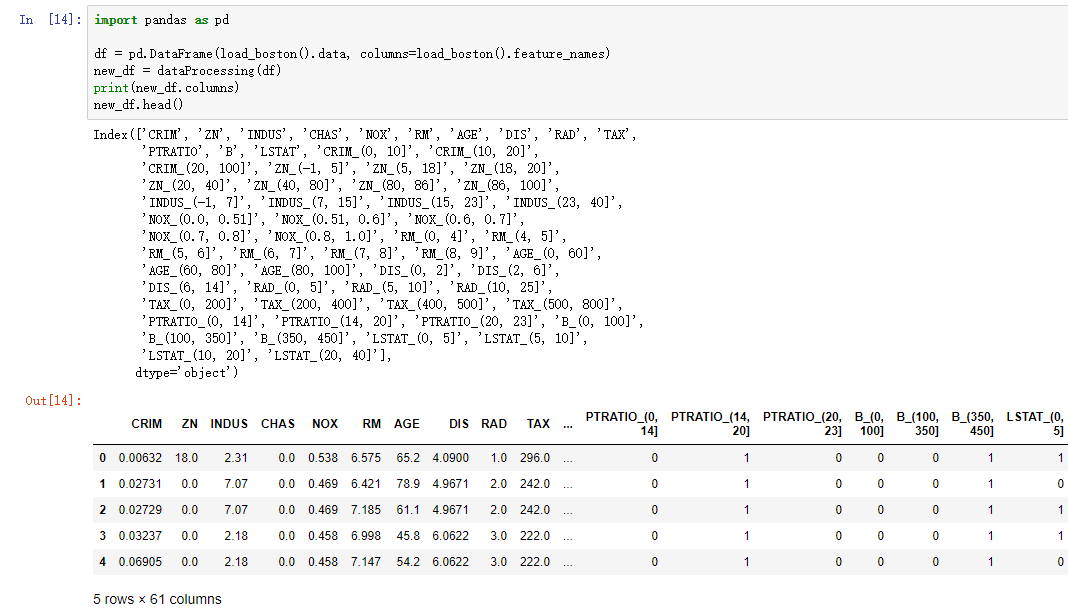
将特征处理后的特征矩阵赋值给变量X,代码如下:
X = new_df.values
2.清除异常值
波士顿房价预测是kaggle网站上2016年的比赛。
网上有资料显示有部分预测目标异常值为50,所以我们删除具有此异常值的样本。
代码如下:
X = new_df.values
y = load_boston().target
print(X.shape)
X = X[y!=50]
y = y[y!=50]
print(X.shape)
上面一段代码的运行结果如下图所示:

从上图中可以看出,特征矩阵X的行数由506变成了490。
3.决策树回归模型
使用决策树回归模型做回归预测,并使用交叉验证查看模型得分。
调用sklearn.tree库的DecisionTreeRegressor方法实例化模型对象。
调用sklearn.model_selection库的KFold方法实例化交叉验证对象。
调用sklearn.model_selection库的cross_val_score方法做交叉验证。
cross_val_score方法需要4个参数,第1个参数是模型对象,第2个参数是特征矩阵X,第3个参数是预测目标值y,第4个关键字参数cv可以为整数或者交叉验证对象,此处因为样本数只有506个,所以得指定交叉验证对象,而且实例化交叉验证对象的时候,必须设置关键字参数shuffle=True,如果不进行设置,会发生严重的错误,读者可以自己尝试一下。
从官方文档查看cross_val_score方法如何使用的链接:http://sklearn.apachecn.org/cn/0.19.0/modules/generated/sklearn.model_selection.cross_val_score.html#sklearn.model_selection.cross_val_score
决策树回归模型的代码如下:
from sklearn.tree import DecisionTreeRegressor
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
decisionTree_model = DecisionTreeRegressor()
kf = KFold(n_splits=5, shuffle=True)
score_ndarray = cross_val_score(decisionTree_model, X, y, cv=kf)
print(score_ndarray)
score_ndarray.mean()
上面一段代码的运行结果如下图所示:
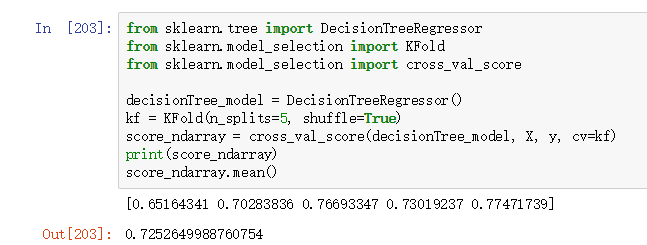
从上图的结果可以看出,5折交叉验证的均值只有0.725,不能起到优秀的预测效果。
4.梯度提升回归模型
代码逻辑和第3章相同。
调用sklearn.ensemble库的GradientBoostingRegressor方法实例化模型对象。
GradientBoostingRegressor中文叫做梯度加速回归模型,本质是一种集成回归模型。
调用sklearn.model_selection库的KFold方法实例化交叉验证对象。
调用sklearn.model_selection库的cross_val_score方法做交叉验证。
cross_val_score方法需要4个参数,第1个参数是模型对象,第2个参数是特征矩阵X,第3个参数是预测目标值y,第4个关键字参数cv可以为整数或者交叉验证对象,此处因为样本数只有506个,所以得指定交叉验证对象,而且实例化交叉验证对象的时候,必须设置关键字参数shuffle=True,如果不进行设置,会发生严重的错误,读者可以自己尝试一下。
从官方文档查看cross_val_score方法如何使用的链接:http://sklearn.apachecn.org/cn/0.19.0/modules/generated/sklearn.model_selection.cross_val_score.html#sklearn.model_selection.cross_val_score
集成回归模型的代码如下:
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
gbr_model = GradientBoostingRegressor()
kf = KFold(n_splits=5, shuffle=True)
score_ndarray = cross_val_score(gbr_model, X, y, cv=kf)
print(score_ndarray)
score_ndarray.mean()
上面一段代码的运行结果如下图所示:
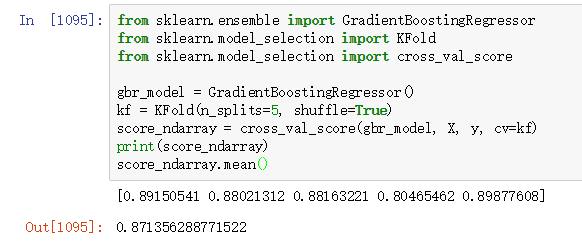
从上面的运行结果可以看出,集成回归模型取得了较好的回归效果。
5.选择最优模型
使用sklearn.model_selection库中的cross_validate方法,需要传入4个参数,第1个参数为模型对象estimator,第2个参数为特征矩阵X,第3个参数为预测目标值y,第4个关键字参数cv数据类型为交叉验证对象,函数返回结果的数据类型为字典。
如果你的sklearn版本小于0.19,则无法调用cross_validate方法。
官方文档有更新sklearn版本的指南,链接:http://sklearn.apachecn.org/cn/0.19.0/install.html
如果你使用的是conda update scikit-learn命令,可能出现长时间等待的情况,解决方案是进行conda换源。
如何进行conda换源,链接:https://jingyan.baidu.com/article/1876c8527be1c3890a137645.html
浏览官方的API,找出所有的回归模型,链接:http://sklearn.apachecn.org/cn/0.19.0/modules/classes.html
| 回归模型中文名 | sklearn库中的对应英文类 |
|---|---|
| 线性回归模型 | LinearRegression |
| 决策树回归模型 | DecisionTreeRegressor |
| 梯度提升回归模型 | GradientBoostingRegressor |
| 多层感知器回归模型 | MLPRegressor |
| 自适应提升回归模型 | AdaBoostRegressor |
| 打包回归模型 | BaggingRegressor |
| 额外树回归模型 | ExtraTreesRegressor |
| 线性支持向量机回归模型 | LinearSVR |
| 随机森林回归模型 | RandomForestRegressor |
| nu支持向量机回归模型 | NuSVR |
| 支持向量机回归模型 | SVR |
nu支持向量机回归模型中的nu的英文解释如下:
An upper bound on the fraction of training errors and a lower bound of the fraction of support vectors. Should be in the interval (0, 1]. By default 0.5 will be taken
中文翻译为:训练误差部分的上界和支持向量部分的下界。应该在(0,1)区间内。默认情况下,取0.5。
搜索最优的回归模型,代码如下:
from sklearn.model_selection import cross_validate
from sklearn.model_selection import ShuffleSplit
from sklearn.linear_model import LinearRegression
from sklearn.tree import DecisionTreeRegressor
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.neural_network import MLPRegressor
from sklearn.ensemble import AdaBoostRegressor
from sklearn.ensemble import BaggingRegressor
from sklearn.ensemble import ExtraTreesRegressor
from sklearn.ensemble import RandomForestRegressor
from sklearn.svm import LinearSVR
from sklearn.svm import NuSVR
from sklearn.svm import SVR
estimator_list = [
LinearRegression(),
DecisionTreeRegressor(),
GradientBoostingRegressor(),
MLPRegressor(solver='lbfgs'),
AdaBoostRegressor(),
BaggingRegressor(),
ExtraTreesRegressor(),
RandomForestRegressor(),
LinearSVR(),
NuSVR(),
SVR()
]
cv_split = ShuffleSplit(n_splits=6, train_size=0.7, test_size=0.2, random_state=168)
df_columns = ['Name', 'Parameters', 'Train Accuracy Mean', 'Test Accuracy Mean', 'Test Accuracy Std', 'Comsumed Time']
df = pd.DataFrame(columns=df_columns)
row_index = 0
for estimator in estimator_list:
df.loc[row_index, 'Name'] = estimator.__class__.__name__
df.loc[row_index, 'Parameters'] = str(estimator.get_params())
cv_results = cross_validate(estimator, X, y, cv=cv_split)
df.loc[row_index, 'Train Accuracy Mean'] = cv_results['train_score'].mean()
df.loc[row_index, 'Test Accuracy Mean'] = cv_results['test_score'].mean()
df.loc[row_index, 'Test Accuracy Std'] = cv_results['test_score'].std()
df.loc[row_index, 'Comsumed Time'] = cv_results['fit_time'].mean()
print(row_index, estimator.__class__.__name__)
print(cv_results['test_score'])
row_index += 1
df = df.sort_values(by='Test Accuracy Mean', ascending=False)
df
上面一段代码的运行结果如下图所示:
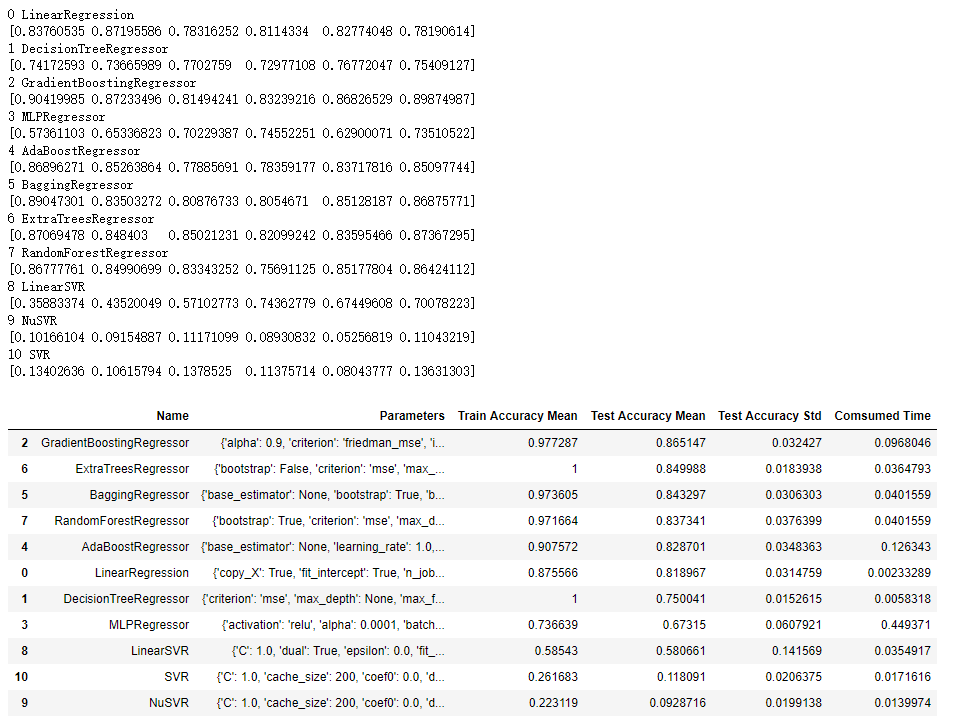
从上图中可以看出,几个集成回归模型都在测试集上取得0.8以上的得分。
决策树回归模型和额外树回归模型在训练集上取得了满分,与测试集结果差距大,说明这2种模型容易过拟合。
6.极致梯度提升回归模型
xgboost中文叫做极致梯度提升模型,官方文档链接:https://xgboost.readthedocs.io/en/latest/tutorials/model.html
打开官方文档网页,使用chrome浏览器的翻译,效果如下图所示:
安装xgboost库,首先下载相关的whl文件,下载地址: https://www.lfd.uci.edu/~gohlke/pythonlibs/#xgboost
打开网址如下图,作者的python版本为3.6,则选择红色箭头标注文件下载。请读者选择自己python版本对应的文件下载。

下载完成后, 打开下载文件所在目录,在此目录下打开cmd。
在cmd中运行命令: pip install xgboost-0.80-cp36-cp36m-win_amd64.whl
请读者保证自己在文件下载目录下打开cmd,运行命令即可成功安装xgboost库。
因为加入了kaggle大赛神器xgboost,重新进行第5步,选择最优的模型。
代码如下:
from sklearn.model_selection import cross_validate
from sklearn.model_selection import ShuffleSplit
from sklearn.linear_model import LinearRegression
from sklearn.tree import DecisionTreeRegressor
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.neural_network import MLPRegressor
from sklearn.ensemble import AdaBoostRegressor
from sklearn.ensemble import BaggingRegressor
from sklearn.ensemble import ExtraTreesRegressor
from sklearn.ensemble import RandomForestRegressor
from sklearn.svm import LinearSVR
from sklearn.svm import NuSVR
from sklearn.svm import SVR
from xgboost import XGBRegressor
estimator_list = [
LinearRegression(),
DecisionTreeRegressor(),
GradientBoostingRegressor(),
MLPRegressor(solver='lbfgs'),
AdaBoostRegressor(),
BaggingRegressor(),
ExtraTreesRegressor(),
RandomForestRegressor(),
LinearSVR(),
NuSVR(),
SVR(),
XGBRegressor()
]
cv_split = ShuffleSplit(n_splits=6, train_size=0.7, test_size=0.2, random_state=168)
df_columns = ['Name', 'Parameters', 'Train Accuracy Mean', 'Test Accuracy Mean', 'Test Accuracy Std', 'Comsumed Time']
df = pd.DataFrame(columns=df_columns)
row_index = 0
for estimator in estimator_list:
df.loc[row_index, 'Name'] = estimator.__class__.__name__
df.loc[row_index, 'Parameters'] = str(estimator.get_params())
cv_results = cross_validate(estimator, X, y, cv=cv_split)
df.loc[row_index, 'Train Accuracy Mean'] = cv_results['train_score'].mean()
df.loc[row_index, 'Test Accuracy Mean'] = cv_results['test_score'].mean()
df.loc[row_index, 'Test Accuracy Std'] = cv_results['test_score'].std()
df.loc[row_index, 'Comsumed Time'] = cv_results['fit_time'].mean()
print(row_index, estimator.__class__.__name__)
print(cv_results['test_score'])
row_index += 1
df = df.sort_values(by='Test Accuracy Mean', ascending=False)
df
上面一段代码的运行结果如下图所示:
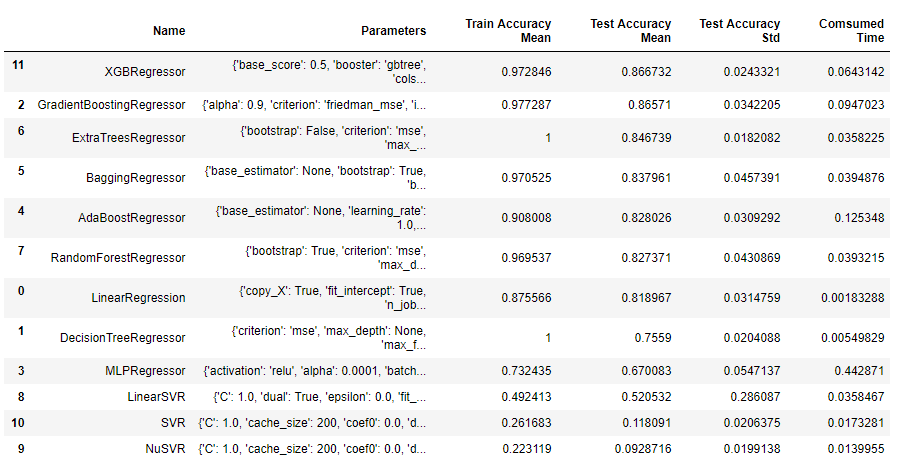
从上面的运行结果可以看出,XGBRegressor模型比GradientBoostingRegressor模型略优,测试集预测结果标准差更小,花费时间也减少1/3。
7.搜索模型最优参数
Grid中文含义是网格,Search中文含义是搜索,CV是cross validation的简写,中文含义为交叉验证。
sklearn.model_selection库中有GridSearchCV方法,作用是搜索模型的最优参数。
官方文档查看GridSearchCV方法如何使用链接:http://sklearn.apachecn.org/cn/0.19.0/modules/generated/sklearn.model_selection.GridSearchCV.html#sklearn.model_selection.GridSearchCV
调用sklearn.model_selection库中的GridSearchCV对象时,需要传入4个参数,第1个参数是模型对象,第2个参数是参数表格,数据类型为字典,第3个关键字参数cv的数据类型是交叉验证对象,第4个关键字参数scoring是字符串str或评分函数对象。
xgboost模型可以并行运算,第7行代码设置并行线程数为15,因为本文作者的CPU是8核16线程,所以设置为15。建议读者根据自己CPU的线程数量设置该参数的值。
代码如下:
from sklearn.model_selection import ShuffleSplit
from sklearn.model_selection import GridSearchCV
from xgboost import XGBRegressor
import numpy as np
import time
xgb_model = XGBRegressor(nthread = 15)
cv_split = ShuffleSplit(n_splits=6, train_size=0.7, test_size=0.2)
param_grid = dict(
max_depth = [4, 5, 6, 7],
learning_rate = np.linspace(0.03, 0.3, 10),
n_estimators = [100, 200]
)
start = time.time()
grid = GridSearchCV(xgb_model, param_grid, cv=cv_split, scoring='neg_mean_squared_error')
grid.fit(X, y)
print('GridSearchCV process use %.2f seconds'%(time.time()-start))
上面一段代码的运行结果如下:
GridSearchCV process use 27.64 seconds
查看以mse指标为评估标准的模型最优参数,以及设置此参数的模型mse指标。
因为上面实例化GridSeachCV对象时,关键字参数scoring为neg_mean_squared_error,neg是negativa的简写,中文叫做负数。
mse指标越小则模型回归效果越好,设置它为负数。
在选择最优参数的时候选择值最大的得分,负数值越大,则绝对值越小,即mse指标越小。
代码如下:
print(grid.best_params_)
print(grid.best_score_)
上面一段代码的运行结果如下图所示:

查看参数迭代器的长度,代码如下:
len(grid._get_param_iterator())
上面一段代码的运行结果如下:
80
模型参数max_depth有4个可能取值,参数learing_rate有10个可能取值,参数n_estimators有2个可能取值。 则这3个参数的组合有4*10*2=80种,与上面查看参数迭代器的长度的结果一致。
8.结论
通过模型的对比,我们在波士顿房价预测项目后面阶段确定使用xgboost库中的XGBRegressor模型。
通过使用GridSearchCV方法做网格搜索,确定XGBRegressor模型使用{'learning_rate': 0.12, 'max_depth': 4, 'n_estimators': 200}的参数组合。
本文是波士顿房价预测项目的第2篇文章,第3篇文章《基于xgboost的波士顿房价预测kaggle实战》将讲解如何提交结果到kaggle网站。
文章链接:https://www.jianshu.com/p/0536182dbb4d

















 946
946

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









