






 本文详细介绍了快速排序算法的基本原理和实现过程,包括算法的时间复杂度、空间复杂度等关键特性,并提供了三种不同的快速排序实现代码,有助于读者深入理解并掌握快速排序。
本文详细介绍了快速排序算法的基本原理和实现过程,包括算法的时间复杂度、空间复杂度等关键特性,并提供了三种不同的快速排序实现代码,有助于读者深入理解并掌握快速排序。

快速排序算法的基本特性
时间复杂度:O(n*lgn)
最坏:O(n^2)
空间复杂度:O(n*lgn)
不稳定。
快速排序是一种排序算法,对包含n个数的输入数组,平均时间为O(nlgn),最坏情况是O(n^2)。
通常是用于排序的最佳选择。因为,基于比较的排序,最快也只能达到O(nlgn)。
在平均状况下,排序 n 个项目要Ο(n log n)次比较。在最坏状况下则需要Ο(n2)次比较,但这种状况并不常见。事实上,快速排序通常明显比其他Ο(n log n) 算法更快,因为它的内部循环(inner loop)可以在大部分的架构上很有效率地被实现出来。
快速排序使用分治法(Divide and conquer)策略来把一个串行(list)分为两个子串行(sub-lists)。
算法步骤:
-
从数列中挑出一个元素,称为 “基准”(pivot),
-
重新排序数列,所有元素比基准值小的摆放在基准前面,所有元素比基准值大的摆在基准的后面(相同的数可以到任一边)。在这个分区退出之后,该基准就处于数列的中间位置。这个称为分区(partition)操作。
-
递归地(recursive)把小于基准值元素的子数列和大于基准值元素的子数列排序。
递归的最底部情形,是数列的大小是零或一,也就是永远都已经被排序好了。虽然一直递归下去,但是这个算法总会退出,因为在每次的迭代(iteration)中,它至少会把一个元素摆到它最后的位置去。
首先简单描述下快速排序的基本思路
快速排序是基于分治模式处理的,对一个典型子数组A[p…r]排序的分治过程为三个步骤:
1.分解:
A[p..r]被划分为俩个(可能空)的子数组A[p ..q-1]和A[q+1 ..r],使得
A[p ..q-1] <= A[q] <= A[q+1 ..r]
2.解决:通过递归调用快速排序,对子数组A[p ..q-1]和A[q+1 ..r]排序。
3.合并。
实现代码如下
代码一:
#include <stdio.h>
// 一趟排序过程
int partition(int *arr, int low, int high)
{
int pivot = arr[high];//选最右边元素为基准
int i = low - 1;//j为游标,i为本趟排序后位置
int j, tmp;
for (j = low; j<high; ++j)//从左向右依次检查
if (arr[j]<pivot)
{
tmp = arr[++i];
arr[i] = arr[j];
arr[j] = tmp;
}
tmp = arr[i + 1];//将基准元素归位
arr[i + 1] = arr[high];
arr[high] = tmp;
return i + 1;//返回基准元素的最终位置
}
//排序算法过程:分治思想,将左右两部分分别递归
void quick_sort(int *arr, int low, int high)
{
if (low<high){
int mid = partition(arr, low, high);
quick_sort(arr, low, mid - 1);
quick_sort(arr, mid + 1, high);
}
}
int main()
{
int arr[10] = { 1, 4, 6, 2, 5, 8, 7, 6, 9, 12 };//测试数据
int i;
quick_sort(arr, 0, 9);
for (i = 0; i<10; ++i)
printf("%d ", arr[i]);
getchar();
}排序结果:![]()
代码二:
#include <stdio.h>
int a[101], n;//定义全局变量,这两个变量需要在子函数中使用
void quicksort(int left, int right)
{
int i, j, t, temp;
if (left>right)
return;
temp = a[left]; //temp中暂存基准数
i = left;
j = right;
while (i != j)
{
//顺序很重要,要先从右边开始找,找比基准数小的数值
while (a[j] >= temp && i<j)
j--;
//再找左边的,找比基准数大的数值
while (a[i] <= temp && i<j)
i++;
//交换两个数在数组中的位置
if (i<j)
{
t = a[i];
a[i] = a[j];
a[j] = t;
}
}
//最终将基准数归位
a[left] = a[i];
a[i] = temp;
quicksort(left, i - 1);//继续处理左边的,这里是一个递归的过程
quicksort(i + 1, right);//继续处理右边的 ,这里是一个递归的过程
}
int main()
{
int i;
//读入数据
printf("please input the length of array sorted:");
scanf_s("%d", &n);
printf("please input the number of array element sorted:\n");
for (i = 1; i <= n; i++)
scanf_s("%d", &a[i]);
//快速排序调用
quicksort(1, n);
//输出排序后的结果
for (i = 1; i <= n; i++)
printf("%d ", a[i]);
getchar();//消除回车符
getchar();//等待输入
return 0;
}排序结果: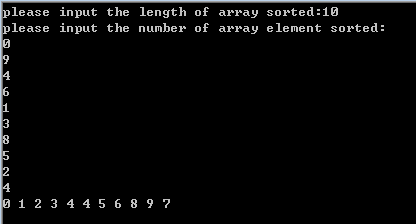
代码三:本改进算法中,只对长度大于k的子序列递归调用快速排序,让原序列基本有序,然后再对整个基本有序序列用插入排序算法排序
#include<stdio.h>
void print(int a[], int n){
for (int j = 0; j<n; j++){
printf("%d ",a[j]);
}
printf("\n");
return;
}
void swap(int *a, int *b)
{
int tmp = *a;
*a = *b;
*b = tmp;
}
// 一次排序过程
int partitions(int a[], int low, int high)
{
int privotKey = a[low]; //基准元素
while (low < high) //从表的两端交替地向中间扫描
{
while (low < high && a[high] >= privotKey) //从high 所指位置向前搜索,至多到low+1 位置。将比基准元素小的交换到低端
--high;
swap(&a[low], &a[high]);
while (low < high && a[low] <= privotKey)
++low;
swap(&a[low], &a[high]);
}
print(a, 10); //输出每次排序结果
return low;
}
// 改进算法:仅当每段长度大于k时,进行一次快速排序
void qsort_improve(int r[], int low, int high, int k){
if (high - low > k) //长度大于k时递归, k为指定的数
{
int pivot = partitions(r, low, high); // 调用的Partition算法保持不变
qsort_improve(r, low, pivot - 1, k);
qsort_improve(r, pivot + 1, high, k);
}
}
//递归进行地快速排序
void quickSort(int r[], int n, int k)
{
//先调用改进算法Qsort使之基本有序
qsort_improve(r, 0, n, k);
//再用插入排序对基本有序序列排序
int i, j,temp;
for (i = 1; i <= n; i++)//因为当i=0时,无意义,故从下标1开始
{
temp = r[i];
j = i - 1;
while (temp<r[j])//升序
{
r[j + 1] = r[j];
j--;
r[j + 1] = temp;
}
}
}
void main()
{
int a[10] = { 3, 1, 5, 7, 2, 4, 9, 6, 10, 8 };
printf("初始值:");
print(a, 10);
quickSort(a, 9, 4);
printf("排序后:");
print(a, 10);
getchar();
}排序结果: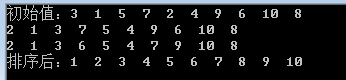
算法复杂度
最坏情况下的快排时间复杂度:
最坏情况发生在划分过程产生的俩个区域分别包含n-1个元素和一个0元素的时候,
即假设算法每一次递归调用过程中都出现了,这种划分不对称。那么划分的代价为O(n),
因为对一个大小为0的数组递归调用后,返回T(0)=O(1)。
估算法的运行时间可以递归的表示为:
T(n)=T(n-1)+T(0)+O(n)=T(n-1)+O(n).可以证明为T(n)=O(n^2)。
因此,如果在算法的每一层递归上,划分都是最大程度不对称的,那么算法的运行时间就是O(n^2)。
最快情况下快排时间复杂度:
最快情况下,即PARTITION可能做的最平衡的划分中,得到的每个子问题都不能大于n/2.
因为其中一个子问题的大小为|n/2|。另一个子问题的大小为|-n/2-|-1.
在这种情况下,快速排序的速度要快得多:
T(n)<=2T(n/2)+O(n).可以证得,T(n)=O(nlgn)。

















 1460
1460

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









