 深入理解Java字符串
深入理解Java字符串







 本文详细解析了Java中String、StringBuilder和StringBuffer的内部机制,包括不可变性、性能比较、对象创建、常量池行为及intern()方法的运作原理。通过源码分析,对比了不同JDK版本下字符串处理的差异。
本文详细解析了Java中String、StringBuilder和StringBuffer的内部机制,包括不可变性、性能比较、对象创建、常量池行为及intern()方法的运作原理。通过源码分析,对比了不同JDK版本下字符串处理的差异。

String类是一个不可变类,他是被final修饰的类,不可被继承,并且值不可改变。

值不可变就意味着我们在进行字符串运算的时候,将会生成新的字符串对象,之前的字符串对象的值不会被改变,比如:
String a = new String(“aa”) + new String(“bb”);//这期间会生成3个堆对象,new String(”aa”)、new String(”bb”)、new String(”aabb”),
而
String a = “aa” + “bb”;//JVM编译后会优化成 String a = “aabb”; 此处注意。
---------------------------------------------------------------------------------------------------------------------------------
字符串拼接性能:
1 String a = “aa” + “bb”;
2 String c = "c".concat("d");
3 StringBuilder a = new StringBuilder(“aa”).append(“bb”).toString();
4 String a = “aa” + new String(“bb”);
性能比较1>2>3>4,注意这只是针对上面3句单纯的表达式,实际开发中我们很少对上面那3句的性能较真,因为在程序中,我们经常面临的String操作可能是这样的:
//+
String a = “a”;
String b = a + “b”;
//concat
String a = “a”;
String b = a.concat("d");
//new String
String a = new String(“a”);
String b = new String(“a”) + new String(“b”);
//StringBuilder
StringBuilder a = new StringBuilder(“aa”);
a.append(“bb”).toString();
对于上面的几种情况我们通过实验得出效率排名,每种操作循环100000次效率如下:
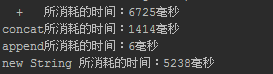
所以,对于频繁的String操作,还是乖乖的用StringBuilder吧
---------------------------------------------------------------------------------------------------------------------------------
String 与 StringBuilder:
String a = "a" + "b" + "c";
相当于
String a = "abc";
----------------------------
String a = "a";
String b = "b";
String d = a + b;
相当于
String a = "a";
String b = "b";
String d = new StringBuilder().append(a).append(b).toString();
----------------------------
String a = "a";
String b = "b";
for(int i=0;i<10000;i++){
a = a + b;/a += b;
}
相当于
String a = "a";
String b = "b";
for(int i=0;i<10000;i++){
String a = new StringBuilder(a).append(b).toString();
}
它要比
String a = a + b + b + b + b + b...省略... + b + b;
相当于
String a = new StringBuilder(a).append(b).append(b).append(b)....省略......append(b).toString();
慢好多数量级,原因是上面的+=表达式写法,中间会生成好多新的StringBuilder对象,以及好多toString()后的String对象,而下面的写法不会生成很多StringBuilder对象和String对象。
所以面对较为频繁的字符串计算操作,尽量使用StringBuilder
---------------------------------------------------------------------------------------------------------------------------------
各种字符串的定义与对象创建关系说明:
//直接在常量池生成“11”对象,s直接指向常量池中“11”对象的地址
String s = "11";
// 此时生成了四个对象 常量池中的"1"对象 + 2个堆中的"1"对象 + s3指向的堆中的”11”对象(注此时常量池不会生成"11")
String s3 = new String("1") + new String("1"); //返回新的String对象”11”
// 同时会生成堆中的"1"对象 以及常量池中的"1"对象,但是此时s1是指向堆中的"1"对象的
String s1 = new String("1");
//会在常量池生成"aabb"对象。 且此时jvm做了优化,不会同时生成"aa"对象和"bb"对象在字符串常量池中
String c = "aa" + "bb";
//不会在字符串常量池生成"aabb"对象,只会生成堆对象
String a = "aa";/String a = new String("aa");
String c = a + "bb";
对于什么时候会在常量池存储字符串对象,我想我们可以基本得出结论:
1.new String 的时候,会在堆内存中生成一个String对象,还会在常量池中生成一个String对象。
2. 显示调用String的intern方法的时候JDK1.6会判断常量池中是否有此String对象,没有将其添加到常量池,JDK1.7会检查该String对象是否在常量池中,有直接返回该String对象的引用地址,没有将该字符串对象地址保存到常量池中,并返回;
3. 直接声明字符串字面常量的时候,例如: String a = "aaa";JDK1.6中如果常量池中没有该字符串,直接在常量池中创建字符串对象,有则不创建。JDK1.7中如果常量池中有该字符串对象或对象地址,则不创建,否则直接在常量池中创建该字符串对象。
4. 字符串常量直接相加的时候。
例如: String c = "aa" + "bb"; 其中的aa/bb只要有任何一个不是字符串字面常量形式,都不会在常量池生成"aabb"对象. 且此时jvm做了优化,不会同时生成"aa"对象和"bb"对象在字符串常量池中。比如:String c = "aa" + "bb";会在字符串常量池生成"aabb"对象,而String a = "aa"/new String("aa");String c = a + "bb";将不会在字符串常量池生成"aabb"对象。 字符串在常量池中的操作同第3条。
总之,简单的定义都会在字符串成亮翅生成对象,而涉及字符串运算的字符串定义,就要看情况了。
---------------------------------------------------------------------------------------------------------------------------------
JDK1.6中字符串常量只存储字符串对象,JDK1.7及其以后字符串常量不仅存储对象,还存储对象地址,正常情况都是直接存储字符串对象,比如:
String s = "11";//直接在常量池生成字符串对象
String s = new String("11");//不仅生成字符串堆对象,同时还在字符串常量池中生成一个字符串对象
String s = "11"+"22";//直接在常量池生成"1122"字符串对象
一下情况不会在常量池生成字符串对象,只在堆内存生成一个字符串堆对象。只能通过再次调用intern()方法将字符串堆对象的引用地址保存到常量池中。
String a = "aa";
String c = a + "bb";//此处常量池不会生成字符串对象
String a = new String("aa");
String c = a + "bb";//此处常量池不会生成字符串对象
String a = new String("aa") + new String("bb");//此处常量池不会生成字符串对象
String a = new String("aa") +"bb";//此处常量池不会生成字符串对象
---------------------------------------------------------------------------------------------------------------------------------
intern()方法
在JDK1.6中,intern()方法会把首次遇到的字符串实例复制到永久代中,返回的也是永久代中这个字符串的实例的引用,所以调用String的intern()方法返回的引用与字符串对象(注意是对象,不是字符串常量)必然不是同一个引用,将返回false。
在JDK1.7中,字符串常量池从永久代迁移到Java的Heap堆内存当中,intern()的实现不会在复制实例,只是在常量池中记录首次出现的字符串实例引用,因此如果字符串对象首次出现,intern()方法返回的引用和创建的字符串对象实例的引用将会是是同一个引用,否则返回的是首次出现的字符串对象的引用。
---------------------------------------------------------------------------------------------------------------------------------
了解了以上的知识点,我们来举例巩固分析下:
String s = new String("1"); // 1
s.intern();// 2
String s2 = "1";// 3
System.out.println(s == s2);// 4
--------------------
JDK1.6以及以下:false
JDK1.7以及以上:false
解析:
1.在堆内存创建一个String("1")对象,在常量池创建String("1")一个对象,共两个对象。但此时 s 指向堆内存中String("1")对象的地址。
2.不论JDK1.6还是JDK1.7,此时常量池中已经存在String("1")对象,因此intern()在此处失去了作用。
3.由于常量池中已经存在String("1")对象,s2此时赋予常量池中String("1")对象的地址。
4.由于s和s2的值分别是堆对象和常量池对象的对象地址,是两个对象,因此不论JDK1.6还是JDK1.7他们都不相等。返回false。
代码示例
String s3 = new String("1") + new String("1"); // 1
s3.intern();// 2
String s4 = "11";// 3
System.out.println(s3 == s4);// 4
--------------------
JDK1.6以及以下:false
JDK1.7以及以上:true
解析:
1.这里涉及了字符串运算,所以此处将生成4个对象:堆内存中2个String("1")对象,1个String("11")对象,常量池中1个String("1")对象,注意常量池中不会生成String("11")对象。
2.此处调用intern()方法,由于常量池中没有String("11")对象,JDK1.6中将会在常量池生成String("11")对象,JDK1.7中将会在常量池中保存堆内存String("11")对象的引用地址(JDK1.7中将常量池从永久区迁移到堆内存)。
3.此处JDK1.6中将永久代中常量池的String("11")对象的引用地址返回给 s4 ,JDK1.7中将堆内存中保存的堆内存String("11")对象的引用地址返回给 s4。
4.JDK1.6中由于 s3 为堆内存中String("11")对象的地址,s4 为永久代常量池中String("11")对象的地址,两个不同的对象地址肯你定不同,返回false。JDK1.7中 s3 为堆内存中String("11")对象的地址,s4 为堆内存常量池中保存的堆内存中String("11")对象的地址(它两就是一个地址)因此返回true。
-----------------------------------------------
String s = new String("1"); // 1
String s2 = "1"; // 2
s.intern(); // 3
System.out.println(s == s2); // 4
--------------------
JDK1.6以及以下:false
JDK1.7以及以上:false
解析:
1.在堆内存创建一个String("1")对象,在常量池创建String("1")一个对象,共两个对象。但此时 s 指向堆内存中String("1")对象的地址。
2.由于常量池中已经存在String("1")对象,s2 此时赋予常量池中String("1")对象的地址。
3.不论JDK1.6还是JDK1.7,此时常量池中已经存在String("1")对象,因此intern()在此处失去了作用。
4.由于 s 和 s2 的值分别是堆对象和常量池对象的对象地址,是两个对象,因此不论JDK1.6还是JDK1.7他们都不相等。返回false
代码示例
String s3 = new String("1") + new String("1"); // 1
String s4 = "11";// 2
s3.intern();// 3
System.out.println(s3 == s4);// 4
--------------------
JDK1.6以及以下:false
JDK1.7以及以上:false
解析:
1.这里涉及了字符串运算,所以此处将生成4个对象:堆内存中2个String("1")对象,1个String("11")对象,常量池中1个String("1")对象,注意常量池中不会生成String("11")对象。
2.此处在常量池中生成一个String("11")对象,并将 s4 赋予常量池String("11")对象的地址。
3.不论JDK1.6还是JDK1.7,此时常量池中已经存在String("11")对象,因此intern()在此处失去了作用。
4.由于 s3 为堆内存String("11")对象的地址,s4 为常量池String("11")对象的地址,s3 和 s4 是两个对象,所以不论JDK1.6还是JDK1.7他们都不相等。返回false---------------------------------------------------------------------------------------------------------------------------------
String、StringBuilder、StringBuffer源码分析
String类的关键源码分析如下:
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence {
/** The value is used for character storage. */
private final char value[];//final类型char数组
//省略其他代码……
……
}从上述的代码片段中我们可以看到,String类在类开始处就定义了一个final 类型的char数组value。也就是说通过 String类定义的字符串中的所有字符都是存储在这个final 类型的char数组中的。
下面我们来看一下String类对字符串的截取操作,关键源码如下:
public String substring(int beginIndex) {
if (beginIndex < 0) {
throw new StringIndexOutOfBoundsException(beginIndex);
}
int subLen = value.length - beginIndex;
if (subLen < 0) {
throw new StringIndexOutOfBoundsException(subLen);
}
//当对原来的字符串进行截取的时候(beginIndex >0),返回的结果是新建的对象
return (beginIndex == 0) ? this : new String(value, beginIndex, subLen);
}当我们对字符串从第beginIndex(beginIndex >0) 个字符开始进行截取时,返回的结果是重新new出来的对象。所以,在对String类型的字符串进行大量“插入”和“删除”操作时会产生大量的临时变量。
StringBuffer和StringBuilder类关键源码分析:
在进行这两个类的源码分析前,我们先来分析下一个抽象类AbstractStringBuilder,因为,StringBuffer和StringBuilder都继承自这个抽象类,即AbstractStringBuilder类是StringBuffer和StringBuilder的共同父类。AbstractStringBuilder类的关键代码片段如下:
abstract class AbstractStringBuilder implements Appendable, CharSequence {
/**
* The value is used for character storage.
*/
char[] value;//一个char类型的数组,非final类型,这一点与String类不同
/**
* This no-arg constructor is necessary for serialization of subclasses.
*/
AbstractStringBuilder() {
}
/**
* Creates an AbstractStringBuilder of the specified capacity.
*/
AbstractStringBuilder(int capacity) {
value = new char[capacity];//构建了长度为capacity大小的数组
}
//其他代码省略……
……
}
StringBuffer类的关键代码如下:
public final class StringBuffer
extends AbstractStringBuilder
implements java.io.Serializable, CharSequence
{
/**
* Constructs a string buffer with no characters in it and an
* initial capacity of 16 characters.
*/
public StringBuffer() {
super(16);//创建一个默认大小为16的char型数组
}
/**
* Constructs a string buffer with no characters in it and
* the specified initial capacity.
*
* @param capacity the initial capacity.
* @exception NegativeArraySizeException if the {@code capacity}
* argument is less than {@code 0}.
*/
public StringBuffer(int capacity) {
super(capacity);//自定义创建大小为capacity的char型数组
}
//省略其他代码……
……StringBuilder类的构造函数与StringBuffer类的构造函数实现方式相同,此处就不贴代码了。
下面来看看StringBuilder类的append方法和insert方法的代码,因StringBuilder和StringBuffer的方法实现基本上一致,不同的是StringBuffer类的方法前多了个synchronized关键字,即StringBuffer是线程安全的。所以接下来我们就只分析StringBuilder类的代码了。StringBuilder类的append方法,insert方法都是Override 父类AbstractStringBuilder的方法,所以我们直接来分析AbstractStringBuilder类的相关方法。
public AbstractStringBuilder append(String str) {
if (str == null)
return appendNull();
int len = str.length();
//调用下面的ensureCapacityInternal方法
ensureCapacityInternal(count + len);
str.getChars(0, len, value, count);
count += len;
return this;
}
private void ensureCapacityInternal(int minimumCapacity) {
// overflow-conscious code
if (minimumCapacity - value.length > 0)
//调用下面的expandCapacity方法实现“扩容”特性
expandCapacity(minimumCapacity);
}
/**
* This implements the expansion semantics of ensureCapacity with no
* size check or synchronization.
*/
void expandCapacity(int minimumCapacity) {
//“扩展”的数组长度是按“扩展”前数组长度的2倍再加上2 byte的规则来扩展
int newCapacity = value.length * 2 + 2;
if (newCapacity - minimumCapacity < 0)
newCapacity = minimumCapacity;
if (newCapacity < 0) {
if (minimumCapacity < 0) // overflow
throw new OutOfMemoryError();
newCapacity = Integer.MAX_VALUE;
}
//将value变量指向Arrays返回的新的char[]对象,从而达到“扩容”的特性
value = Arrays.copyOf(value, newCapacity);
}从上述代码分析得出,StringBuilder和StringBuffer的append方法“扩容”特性本质上是通过调用Arrays类的copyOf方法来实现的。接下来我们顺藤摸瓜,再分析下Arrays.copyOf(value, newCapacity)这个方法吧。代码如下:
public static char[] copyOf(char[] original, int newLength) {
//创建长度为newLength的char数组,也就是“扩容”后的char 数组,并作为返回值
char[] copy = new char[newLength];
System.arraycopy(original, 0, copy, 0,
Math.min(original.length, newLength));
return copy;//返回“扩容”后的数组变量
}其中,insert方法也是调用了expandCapacity方法来实现“扩容”特性的,此处就不在赘述了。
接下来,分析下delete(int start, int end)方法,代码如下:
public AbstractStringBuilder delete(int start, int end) {
if (start < 0)
throw new StringIndexOutOfBoundsException(start);
if (end > count)
end = count;
if (start > end)
throw new StringIndexOutOfBoundsException();
int len = end - start;
if (len > 0) {
//调用native方法arraycopy对value数组进行复制操作,然后重新赋值count变量达到“删除”特性
System.arraycopy(value, start+len, value, start, count-end);
count -= len;
}
return this;
}从源码可以看出delete方法的“删除”特性是调用native方法arraycopy对value数组进行复制操作,然后重新赋值count变量实现的
最后,来看下substring方法,源码如下 :
public String substring(int start, int end) {
if (start < 0)
throw new StringIndexOutOfBoundsException(start);
if (end > count)
throw new StringIndexOutOfBoundsException(end);
if (start > end)
throw new StringIndexOutOfBoundsException(end - start);
//根据start,end参数创建String对象并返回
return new String(value, start, end - start);
}四、总结:
1、String类型的字符串对象是不可变的,一旦String对象创建后,包含在这个对象中的字符系列是不可以改变的,直到这个对象被销毁。
2、StringBuilder和StringBuffer类型的字符串是可变的,不同的是StringBuffer类型的是线程安全的,而StringBuilder不是线程安全的
3、如果是多线程环境下涉及到共享变量的插入和删除操作,StringBuffer则是首选。如果是非多线程操作并且有大量的字符串拼接,插入,删除操作则StringBuilder是首选。毕竟String类是通过创建临时变量来实现字符串拼接的,耗内存还效率不高,怎么说StringBuilder是通过JNI方式实现终极操作的。
4、StringBuilder和StringBuffer的“可变”特性总结如下:
(1)append,insert,delete方法最根本上都是调用System.arraycopy()这个方法来达到目的
(2)substring(int, int)方法是通过重新new String(value, start, end - start)的方式来达到目的。因此,在执行substring操作时,StringBuilder和String基本上没什么区别。

















 886
886

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









