






 本文介绍了电影推荐系统的原理及实现过程,包括基于内容的推荐、协同过滤等方法,并探讨了推荐系统的评估指标,如召回率、精确率等。
本文介绍了电影推荐系统的原理及实现过程,包括基于内容的推荐、协同过滤等方法,并探讨了推荐系统的评估指标,如召回率、精确率等。

一、课程介绍



二、推荐系统基本概念
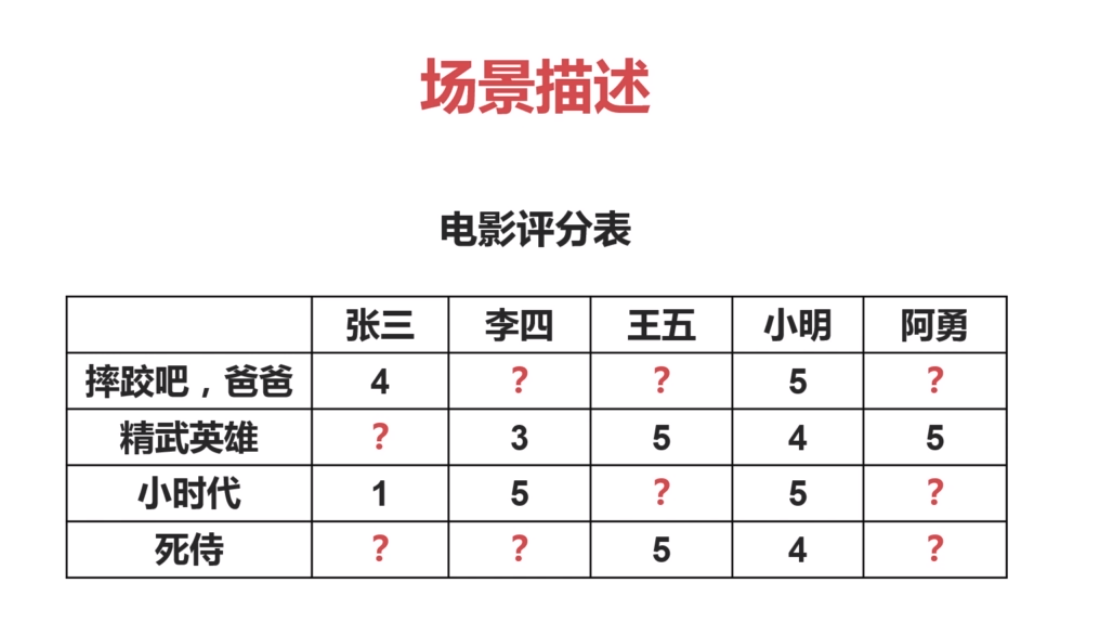
1.电影推荐系统原理
2.基于内容的推荐系统
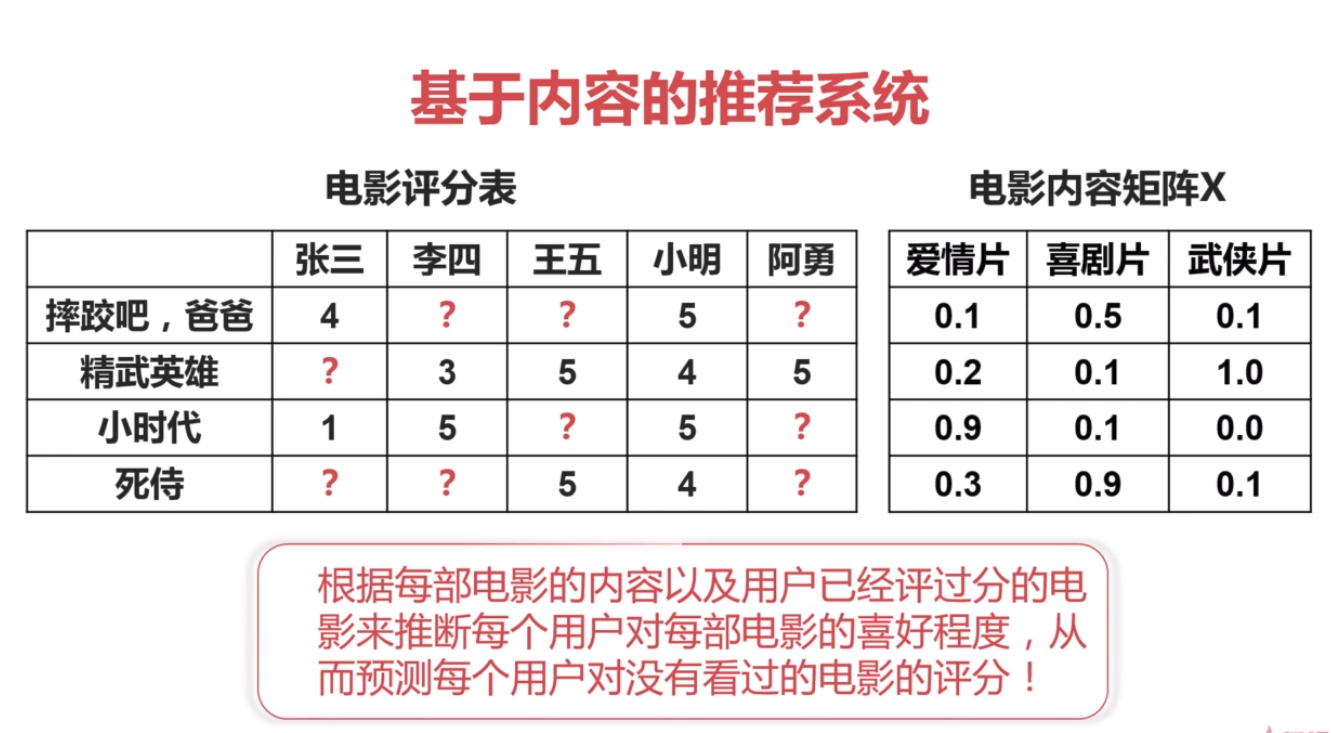

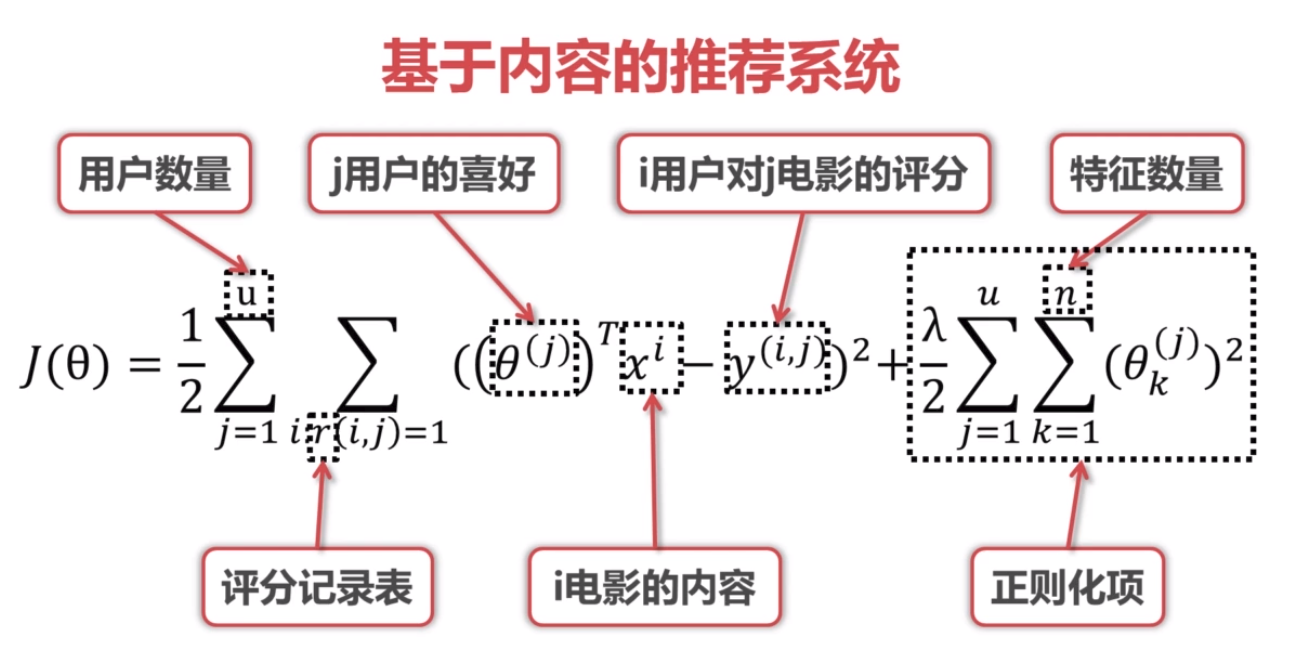
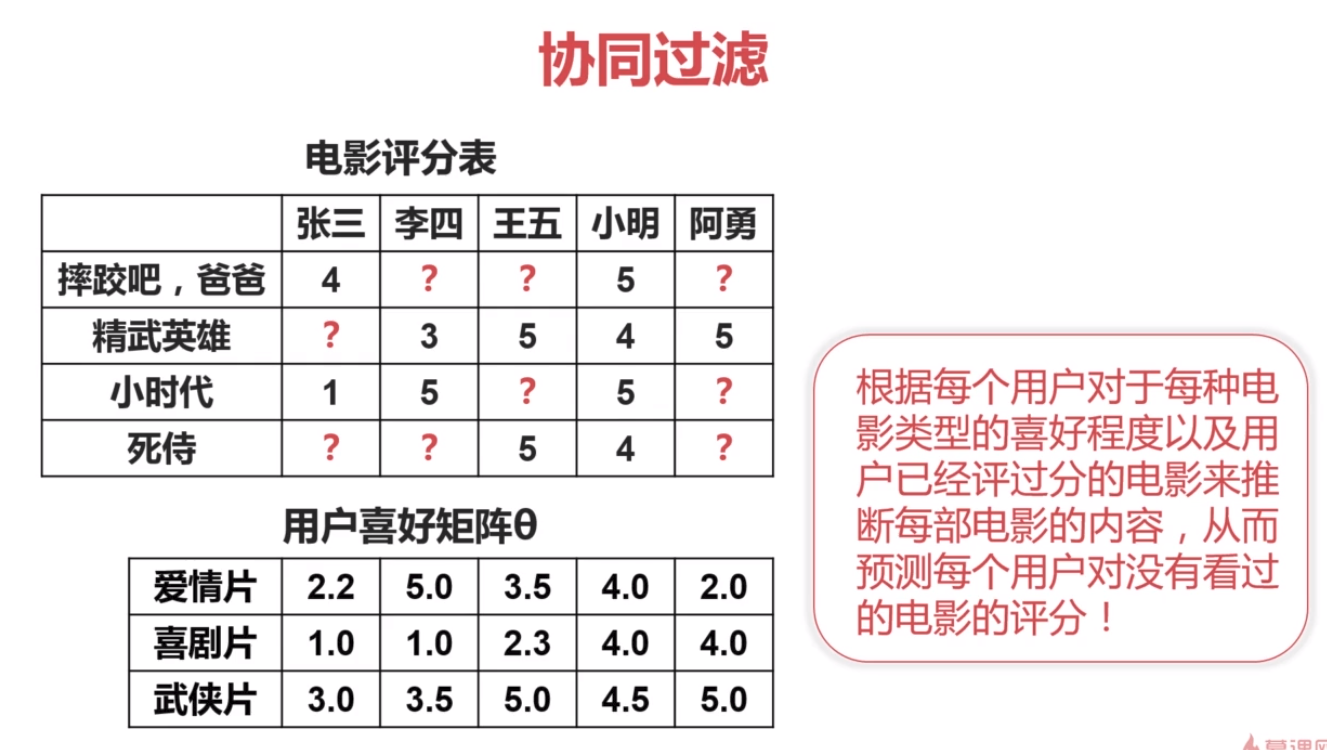
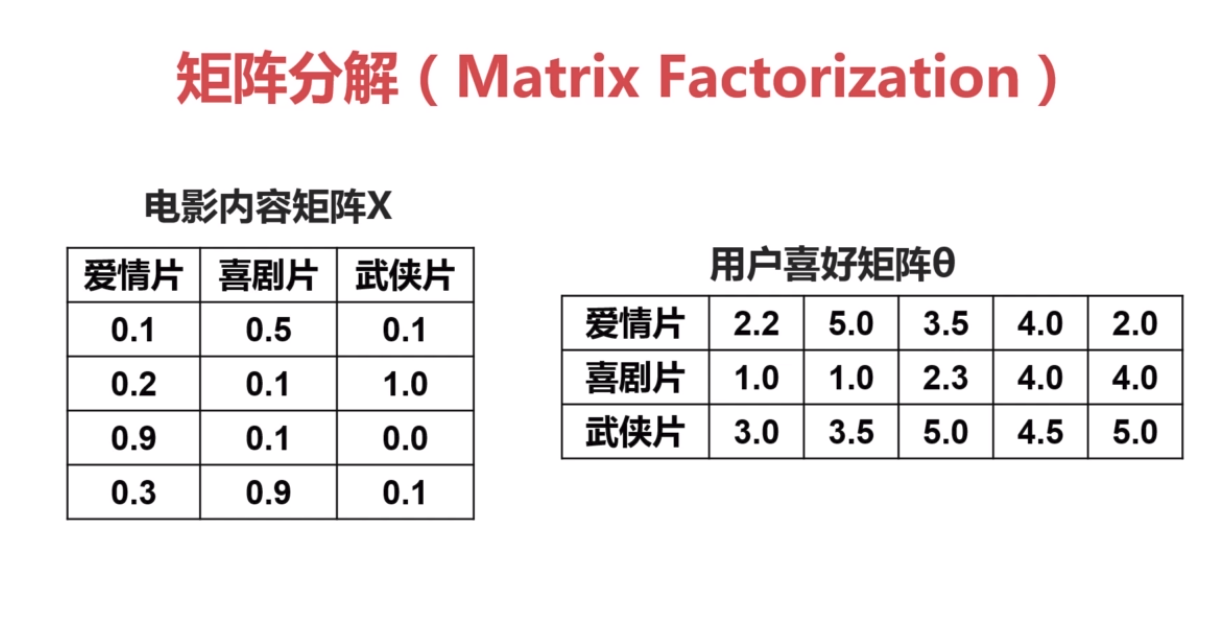
3.基于矩阵分解的协同过滤

得到方式:1.在线问卷调查
合并公式:

目标:最小化这个公式的结果
只需要用户对电影的评分即可
两个高纬向量
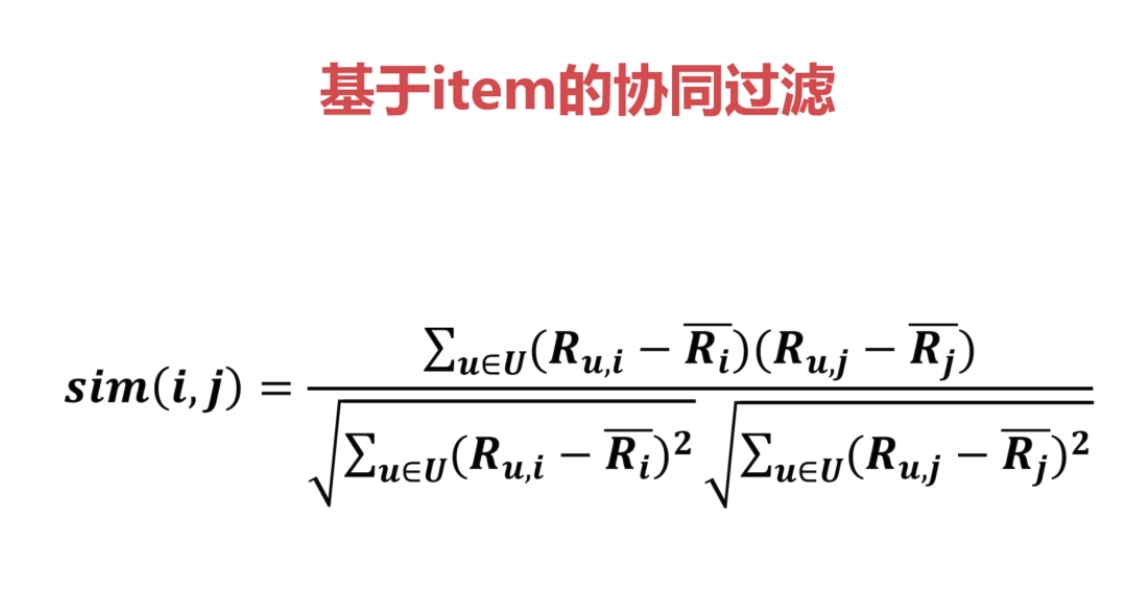
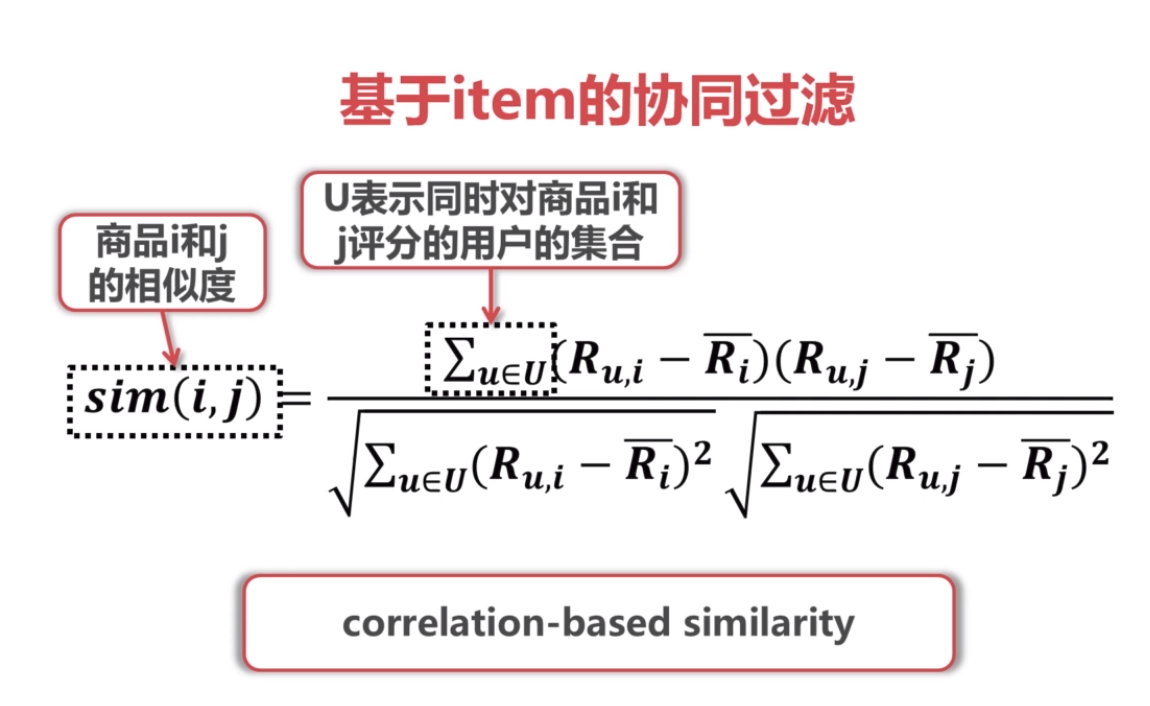
4.基于item的协同过滤和基于用户的协同过滤

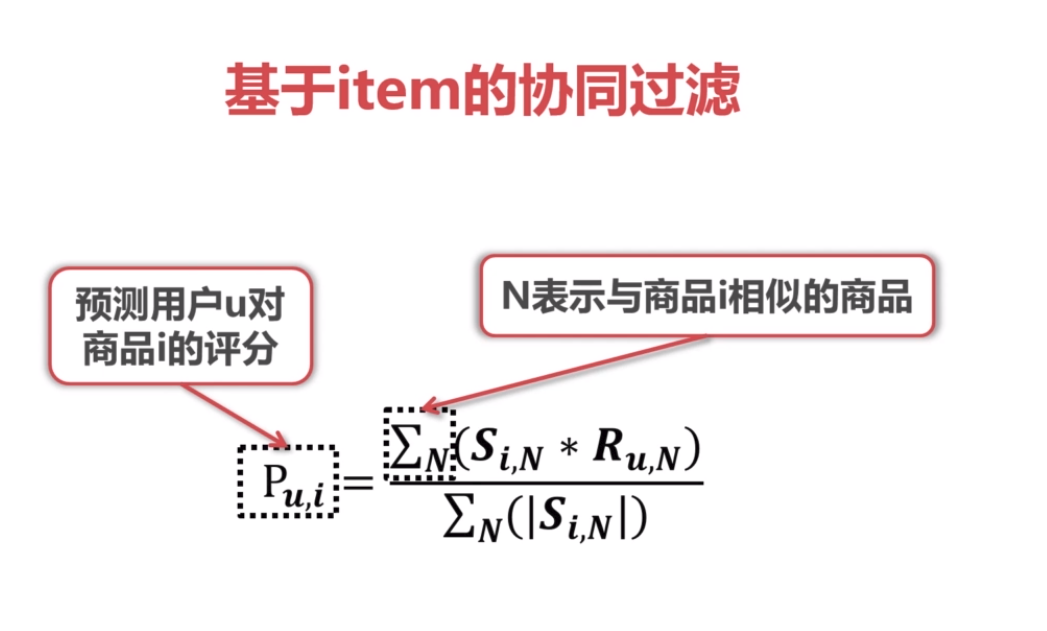
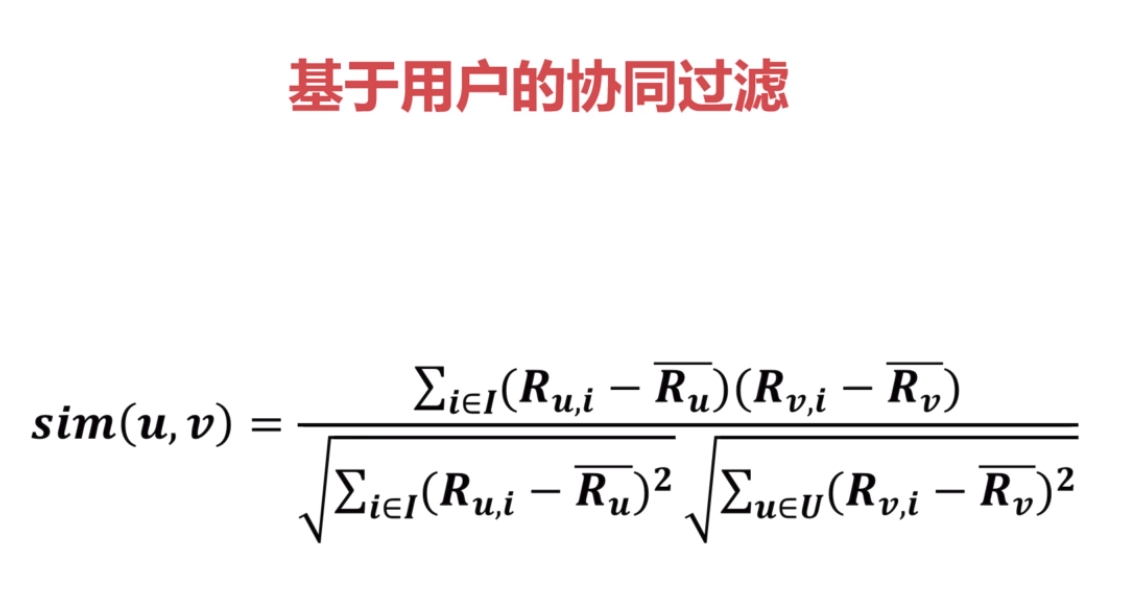
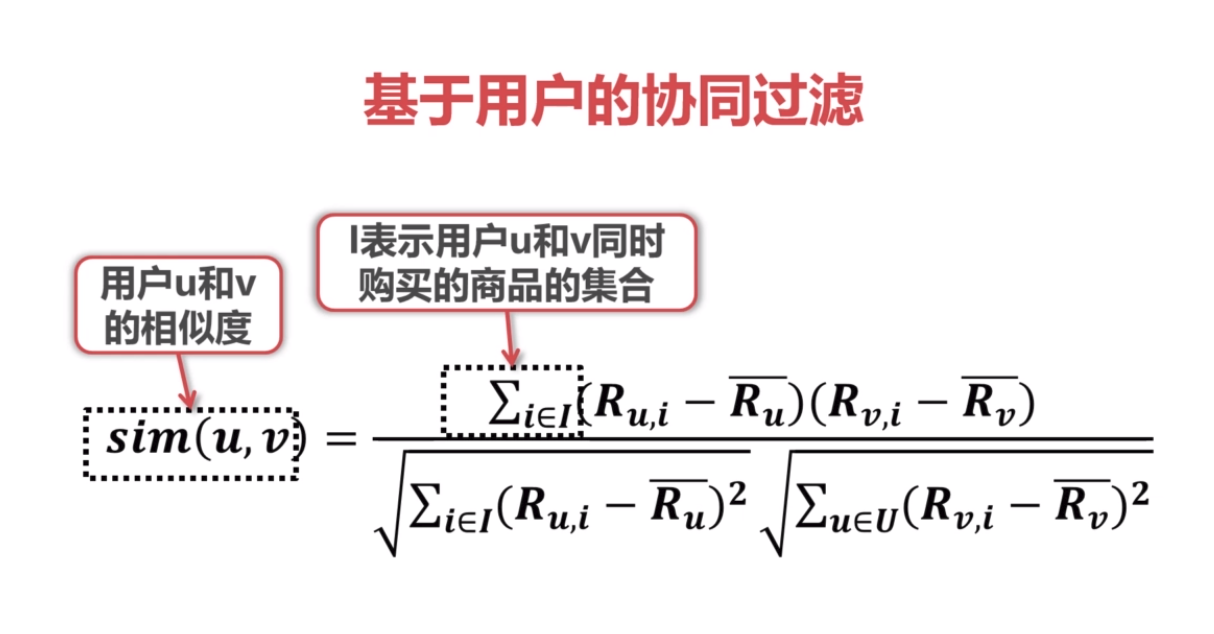
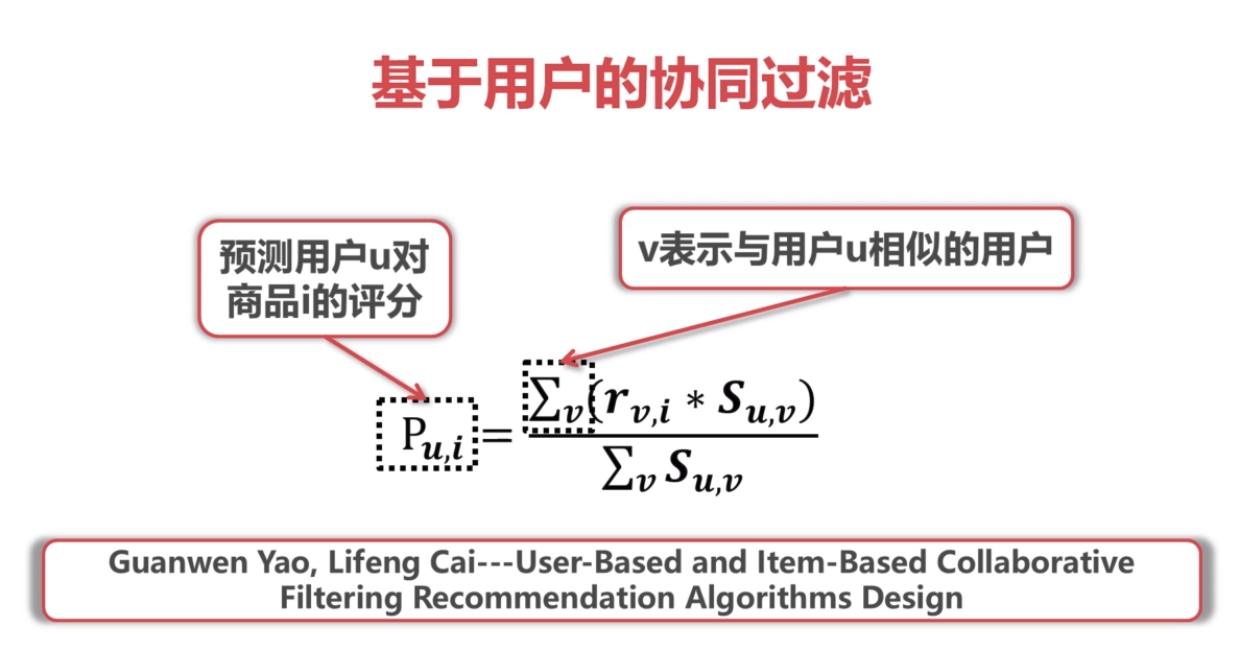
根据与用户u相似的其他用户对商品i的评分,来推测用户u对商品i的评分
5.冷启动问题
之前的方法是基于用户已经看过一些电影,买过一些商品并且进行了评分,因此具备该用户信息,以便推荐
但是新用户并没有,这就是冷启动

6.基于内容的推荐的优缺点


7.基于协同过滤的推荐的优缺点


gray sheep 当没有相似的时候,无法推荐

shiling attack:被刷分影响
8.混合算法
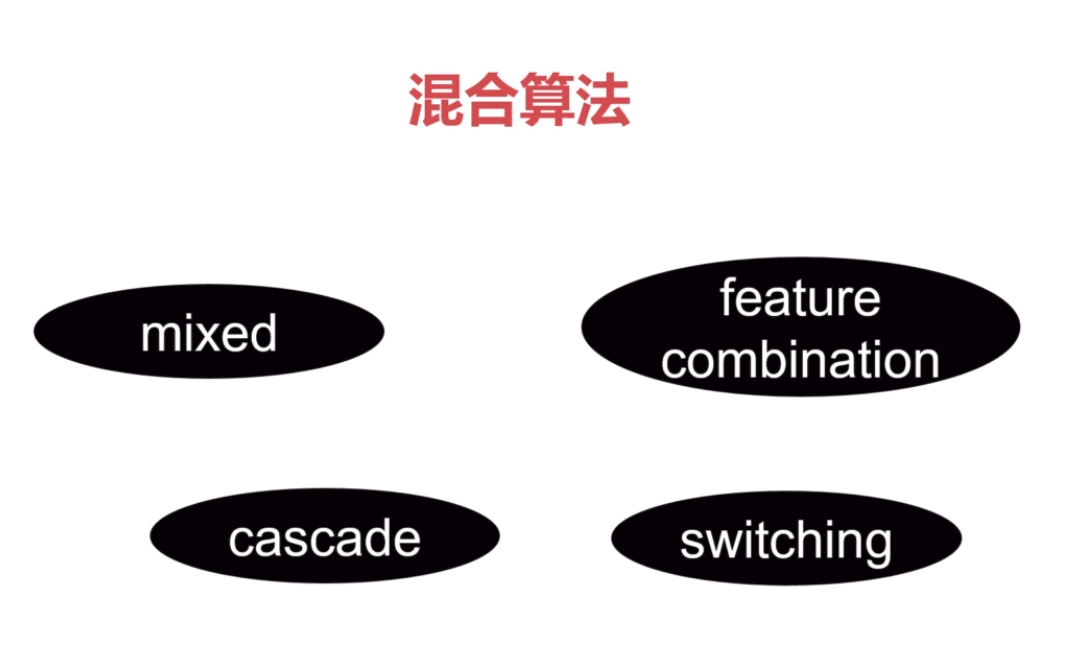
mixed:使用多个推荐系统同时进行推荐,将推荐结果同时推送给用户
feature combination:将多个推荐系统使用的特征组合起来,提供给另外一个推荐系统
cascade:一个推荐系统产生推荐结果之后,用另一个推荐系统进一步筛选,将筛选的结果推荐给用户
switching:根据当前的状态,在不同的推荐系统之间进行切换
9.推荐系统性能评估


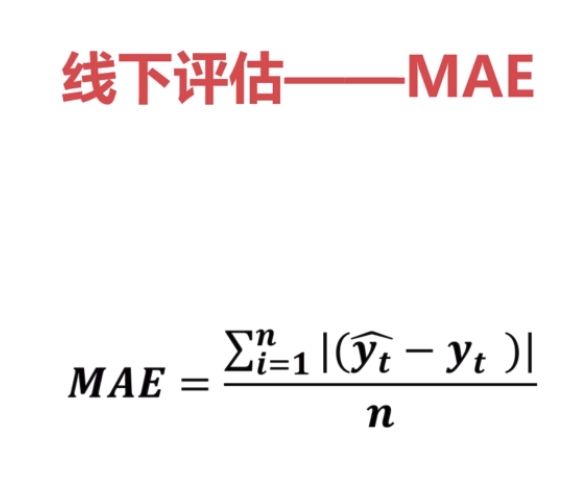
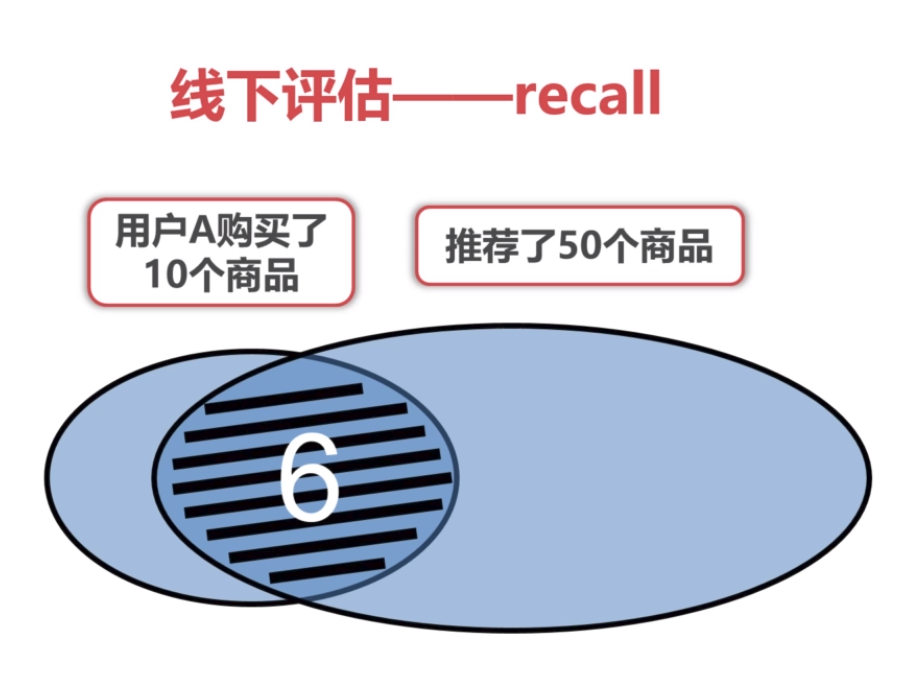
recall=6/10=0.6
单单使用recall评估是不行的
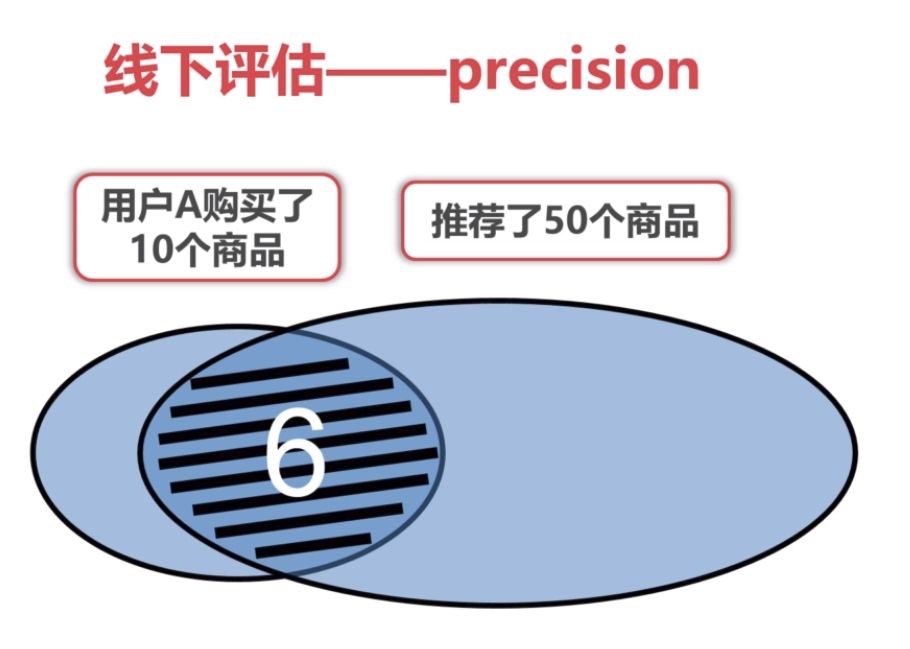
precision=6/50=0.12
可以将recall和precision结合起来,都比较大的时候是比较好的


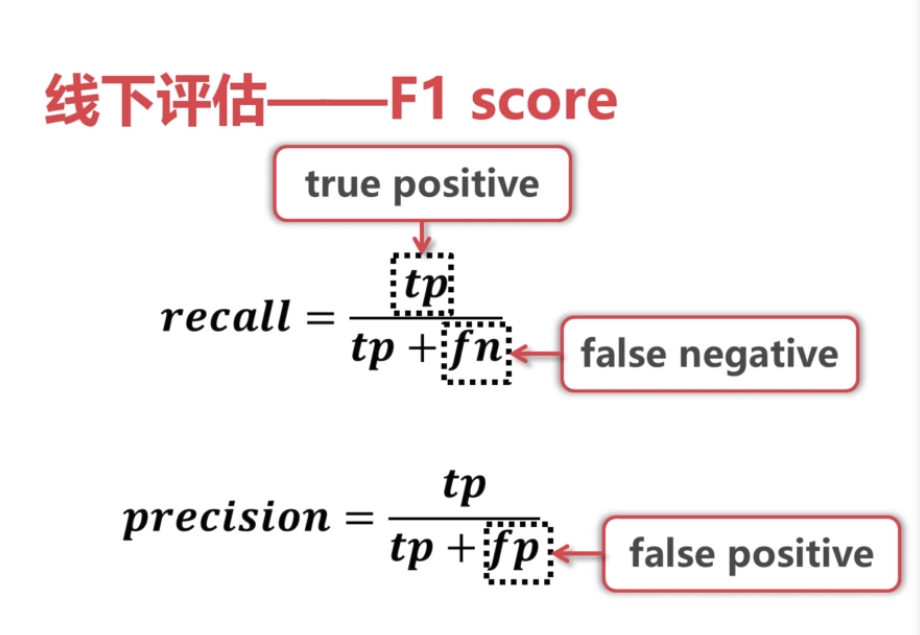
tp:如果推荐系统预测用户A会买商品i,而实际也如此
fp:如果推荐系统预测用户A会买商品i,而实际并没有
tn:如果推荐系统预测用户A不会买商品i,而实际也没有买
fn:如果推荐系统预测用户A不会买商品i,而实际买了

F的值越大说明推荐系统性能越好
并不是说推荐系统性能越好,推荐系统越好,对于商业化的推荐系统来说,获得更大的利润的推荐系统才是最好的
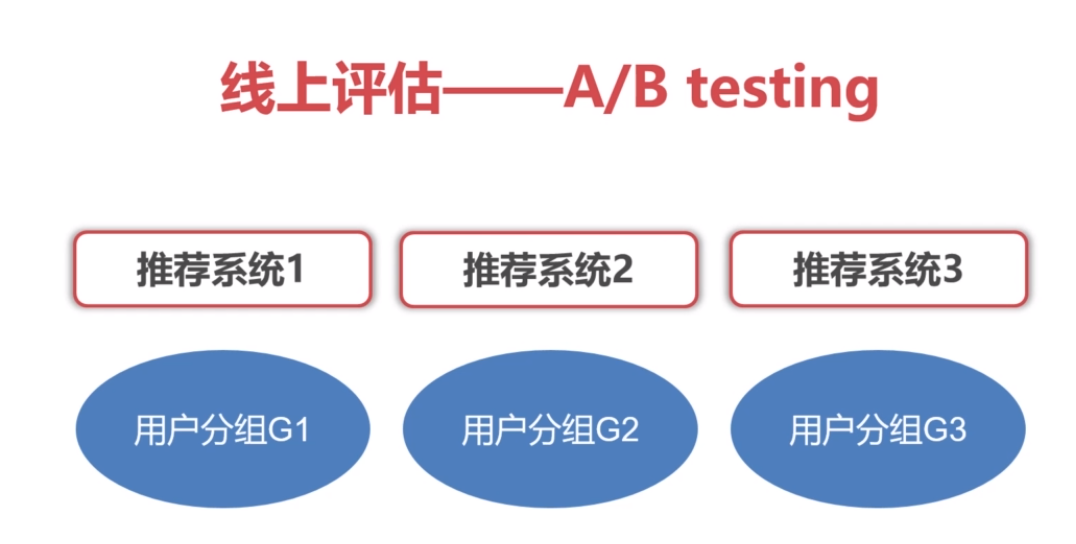
A/B testing:将用户分组,对不同组的用户用不同的推荐系统进行推荐,最后看看哪个分组的推荐系统的性能较号。小号计算资源

假设一个推荐系统向用户A推荐了10次,用户A点击了3次
CTR=3/10=0.3
CTR越高说明用对商品越感兴趣
如果还想知道用户不但点击了商品,是否还听完了歌曲,看完了文章,就要看CR(转换率)
CR越高,说明用户的体验越好,推荐系统性能越好

用来度量不同投资对应的回报,推荐系统中ROI越大性能越好
可以将回报定义为:利润增加,收听量增加,阅读量增加等
将代价定义为计算资源成本
关键在于:定义合理的回报和投资
有时候仅凭算法来度量推荐系统的性能会出现奇怪的地方,最好成立QA小组来测试推荐系统,根据个人经验来评断
10.评估总结

快速构建多个合适的推荐系统=》制定评估推荐系统的标准=》进行线下评估=》将选择得到的模型进行线上评估
选择A/Btesing的方式来选择推荐系统
评估方式结合CTR,CR,ROI,QA来进行综合评估
最后的到可靠的推荐系统
三、电影推荐系统实践(线下评估方式)
1.基于矩阵分解的电影推荐系统
(1)收集数据
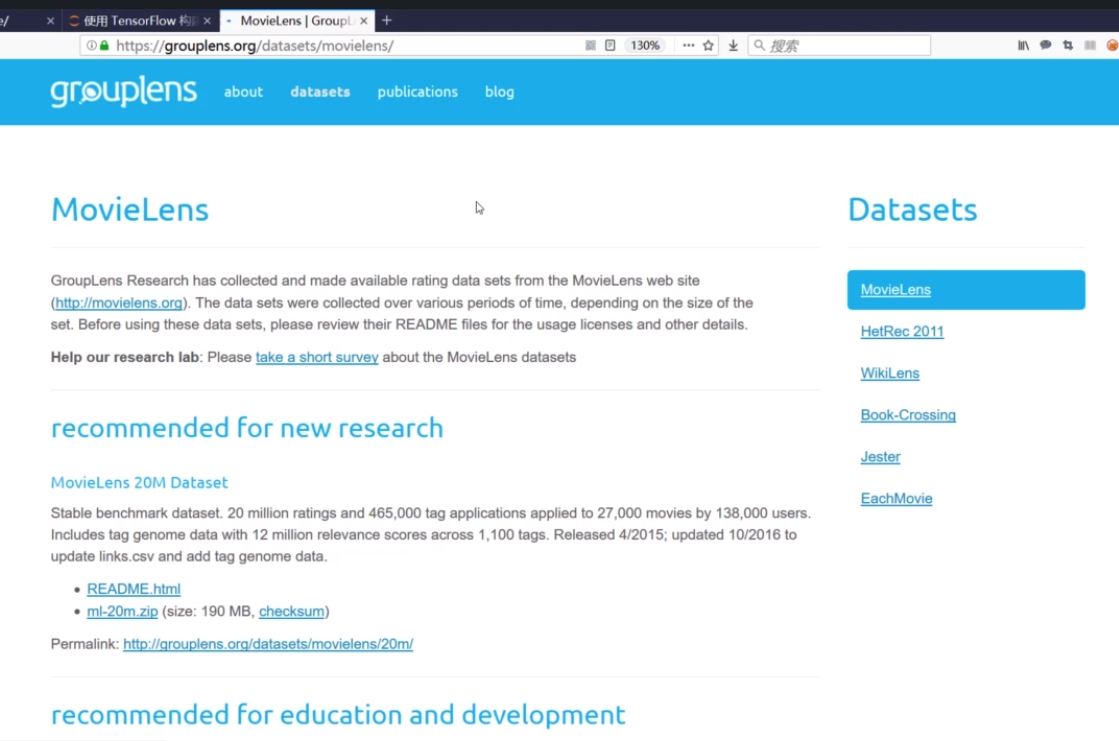

数据集下载(需要翻墙):https://grouplens.org/datasets/movielens/
(2)准备数据
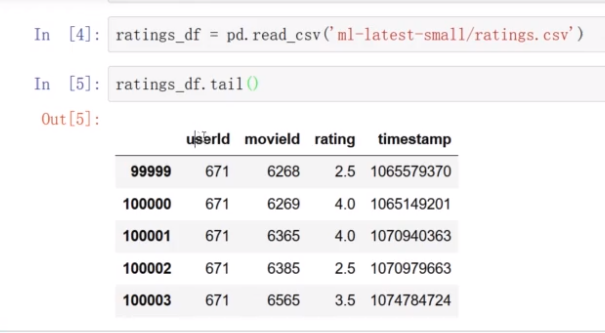

movield并不是行号,远远大于行号,矩阵过大,计算占用过大
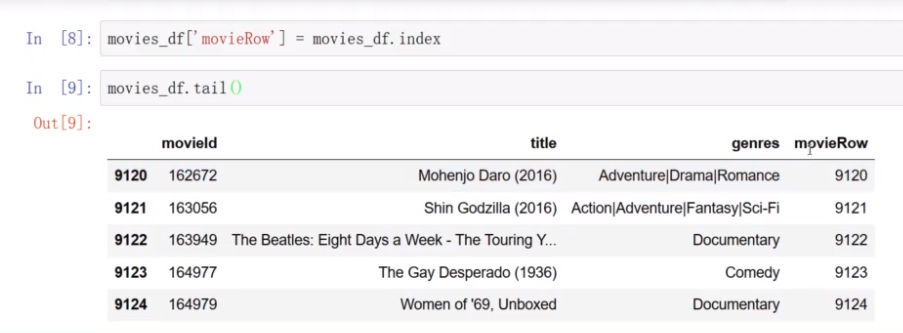
增加movieRow行号,以便计算

把处理好的数据保存到文件中
、
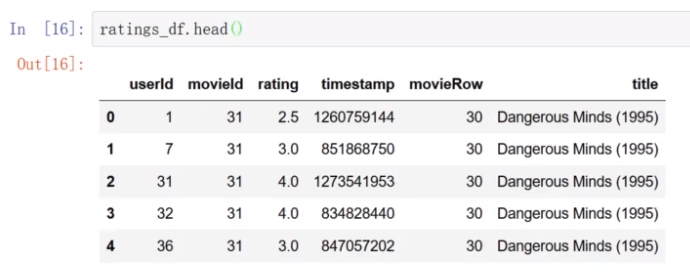
合并后的信息

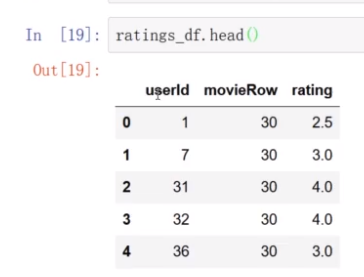
用户编号,电影编号,评分
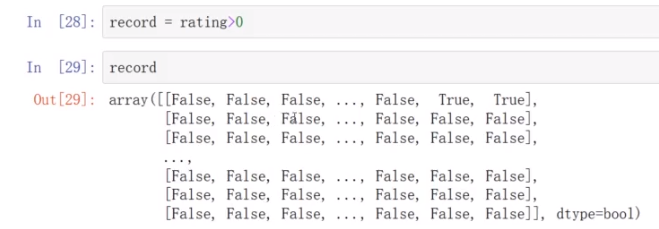
rating为0表示没有评分,为1表示评分了

将布尔值转化为0,1
(3)模型构建

数据集中有的行全部是0,![]() 计算结果是nan
计算结果是nan
必须进行处理
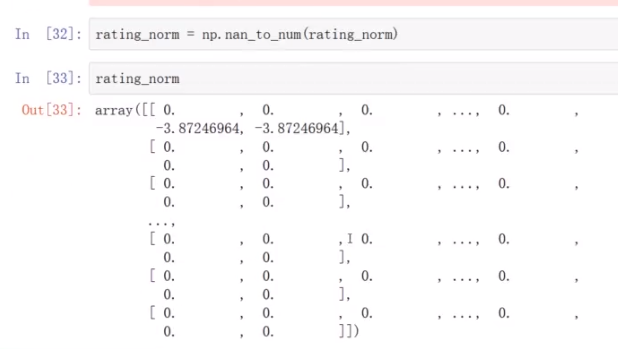
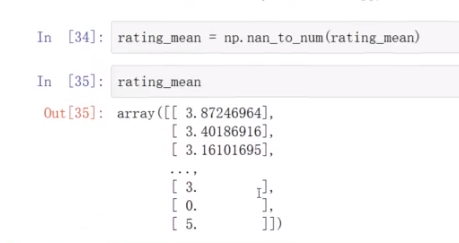
处理是0的部分
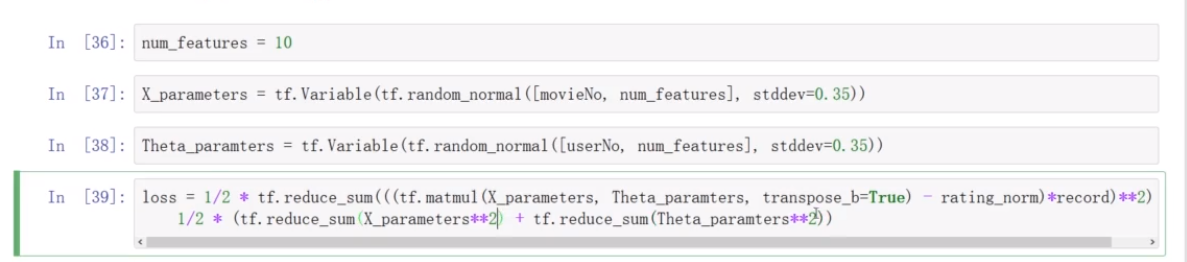
两个矩阵初始化,对两个矩阵相乘,transpose_b=True对第二个矩阵转置。行1和行2相加

这里将正则化项拉姆达设置为1,可以通过调整拉姆达来看模型性能的变化

le-4是10的-4次方
(4)训练模型

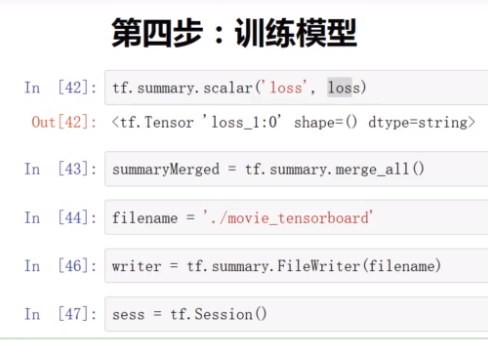
第一个参数loss是对要可视化变量起名,第二个loss是要保存可视化变量

只对loss汇总

定义路径名

把信息保存到文件中

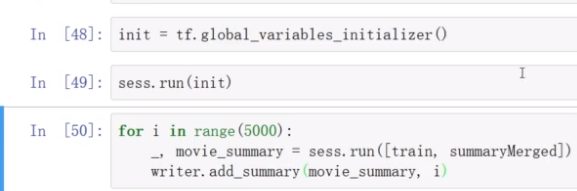
开始训练模型。
不重要的变量可以用_表示,每次训练的train都会保存到_里面,summaryMerged都会保存到movie_summary里面
打开cmd操作界面,切换到保存数据的路径当中
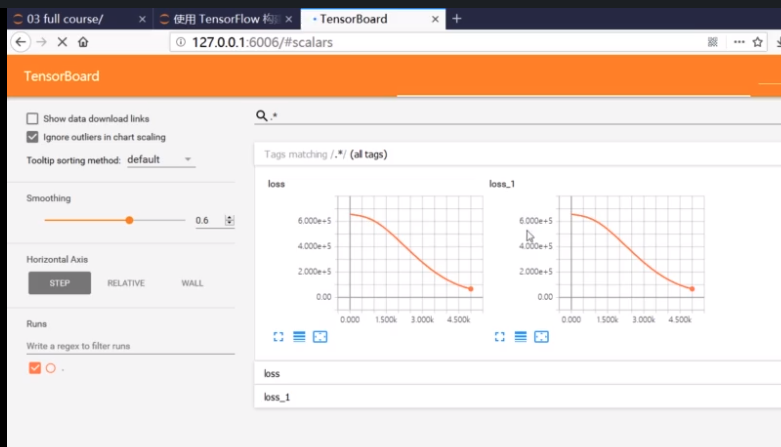
在浏览器中打开http://127.0.0.1:6006
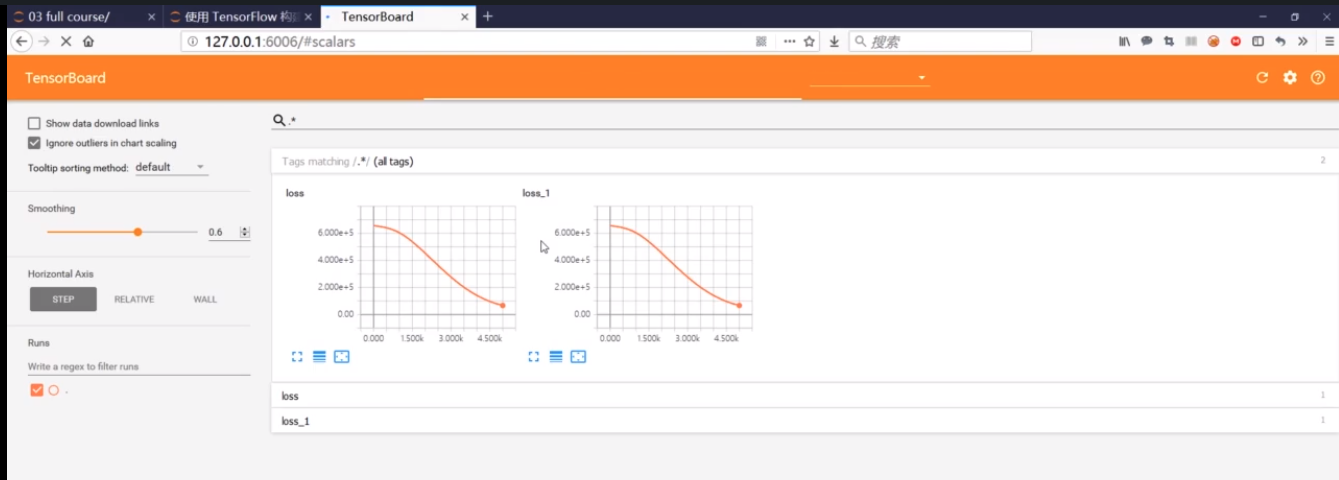
![]()
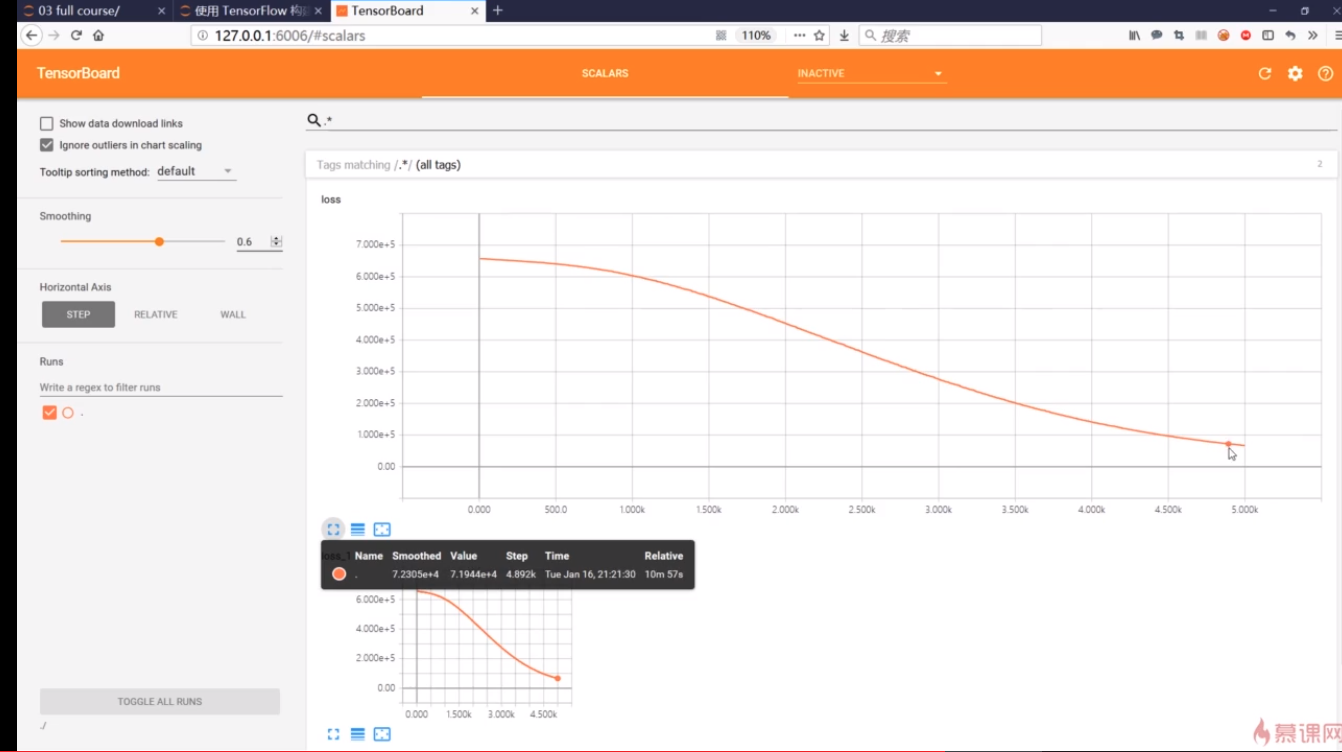
看到代价值随着迭代次数增加不断减少的
(5)评估模型
直接使用设定的

电影内容矩阵和用户喜好矩阵相乘,再加上每一行的均值,得到完整的电影评分表
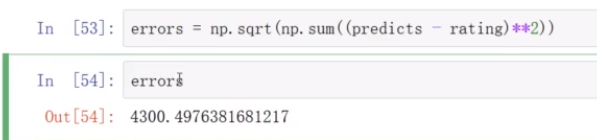
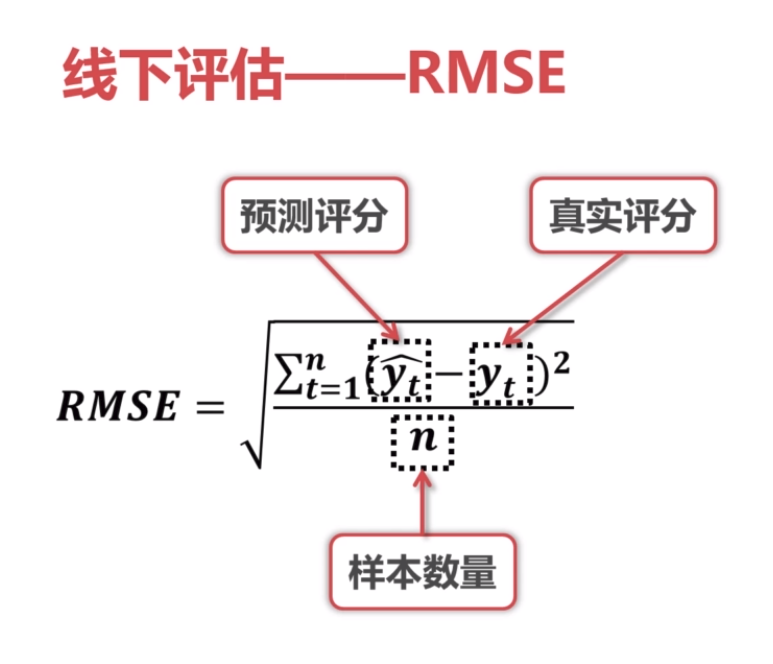
计算预测值与真实值之间的惨差值的算数平方根
2.线性回归原理与实战
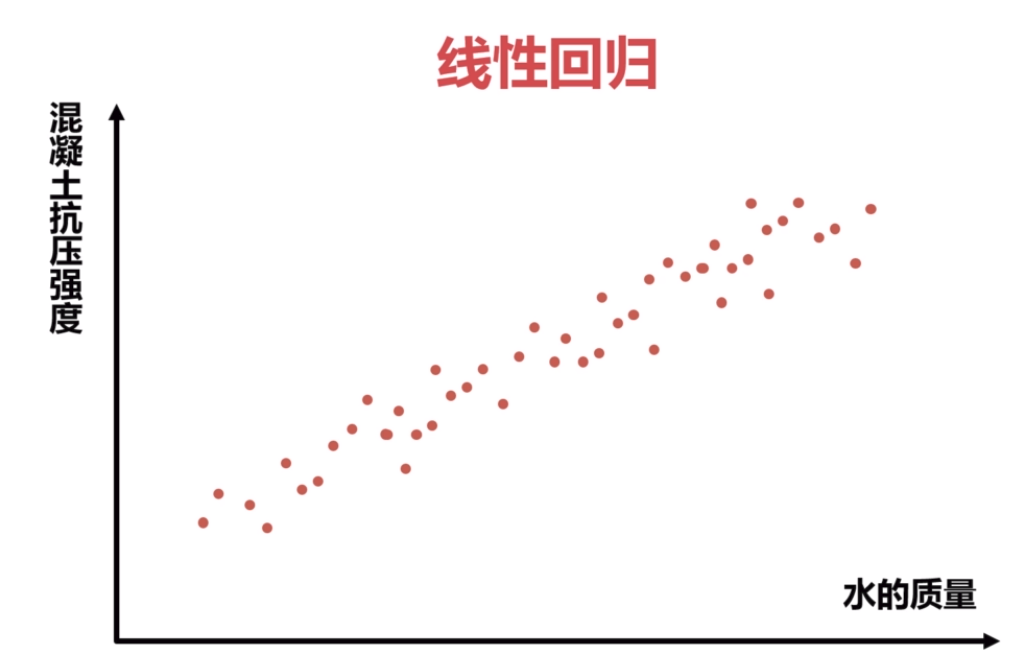



代价函数。目标:最小化代价函数的值,使用梯度下降算法
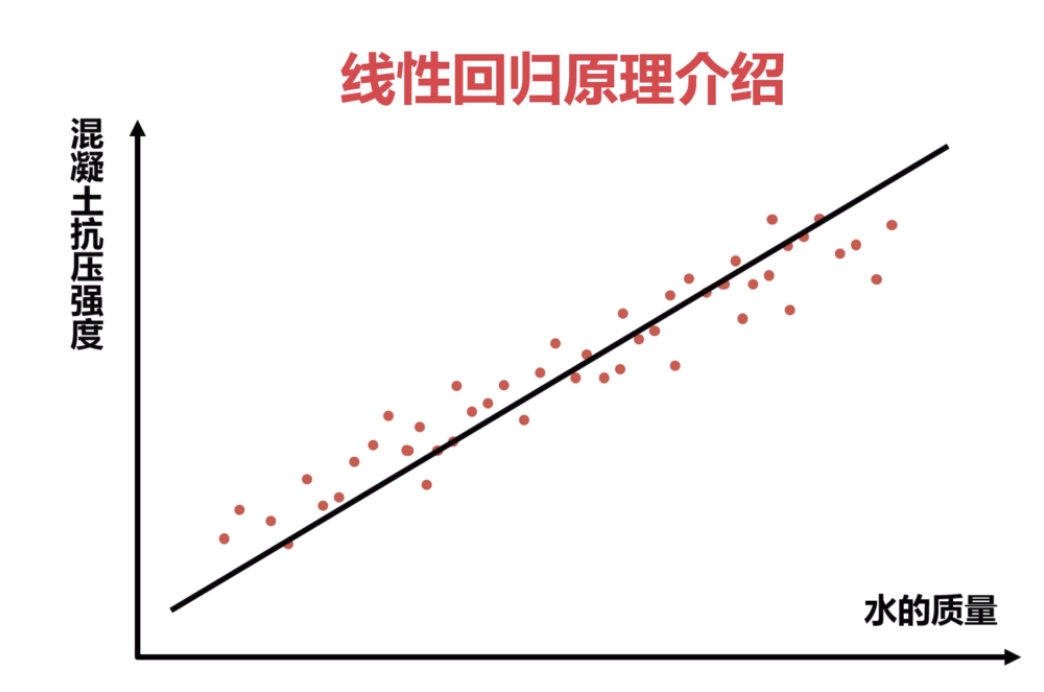
线性回归函数直线
(1)收集数据

数据集:http://http:archive.ics.uci.edu/ml/machine-learning-databases/concrete/compressive
(2)加载数据集

加载数据集
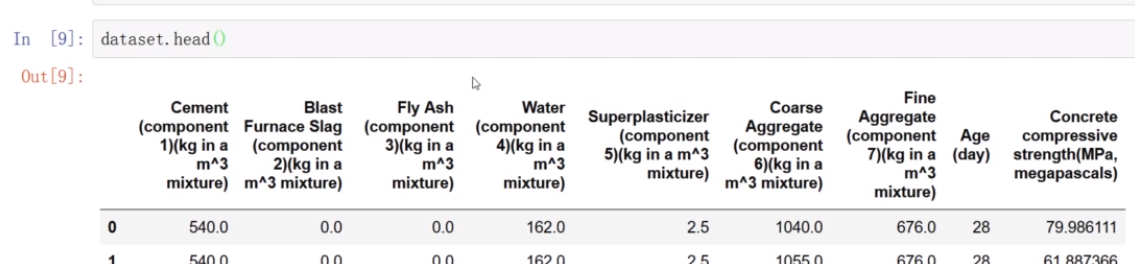
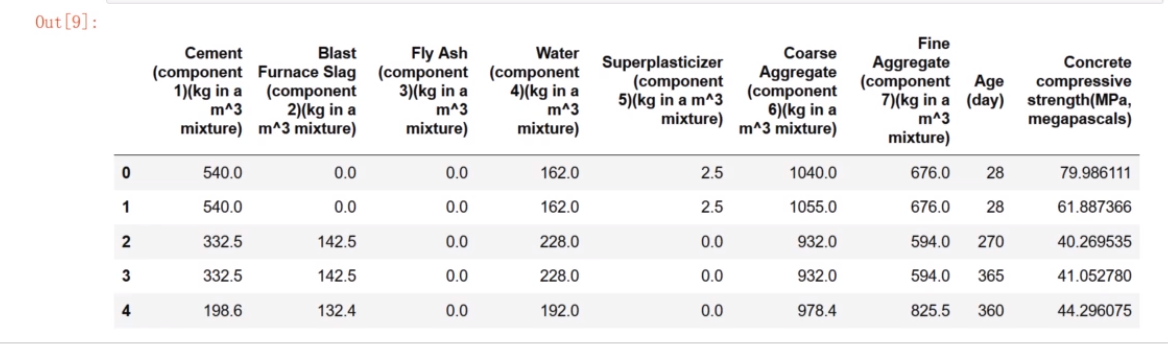
查看数据集
原始数据集名称太长

特征名字很长
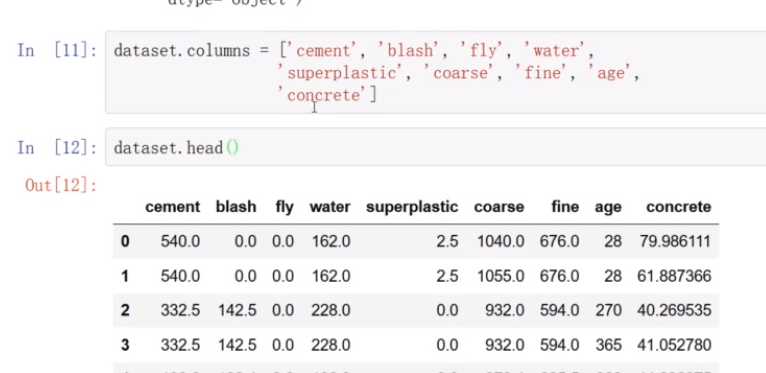
重新命名特征名
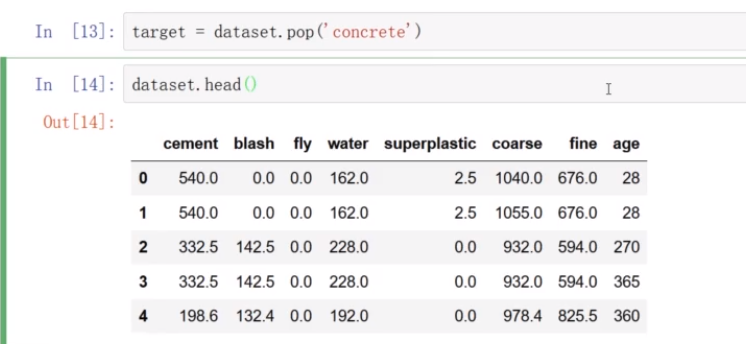
将目标变量和数据相分离
(3)选择模型
使用交叉验证来评估模型的性能:
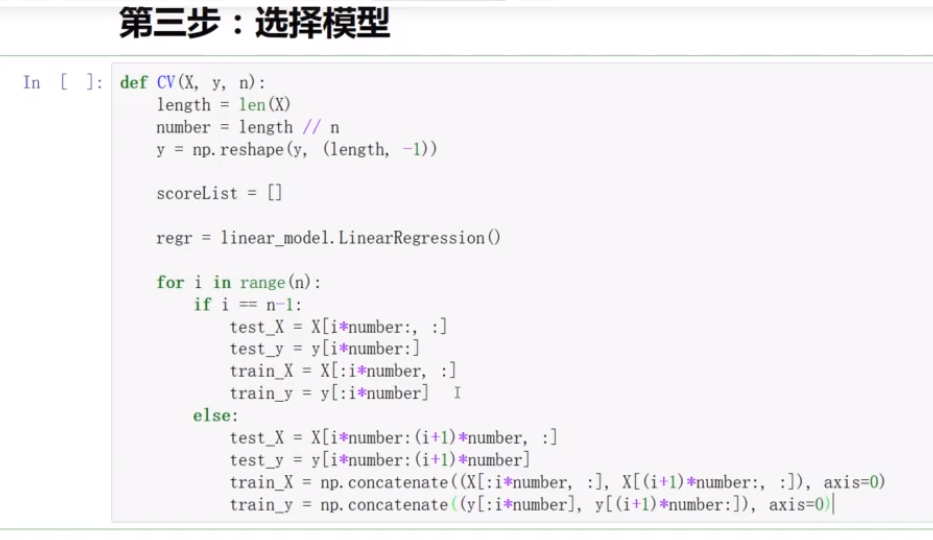
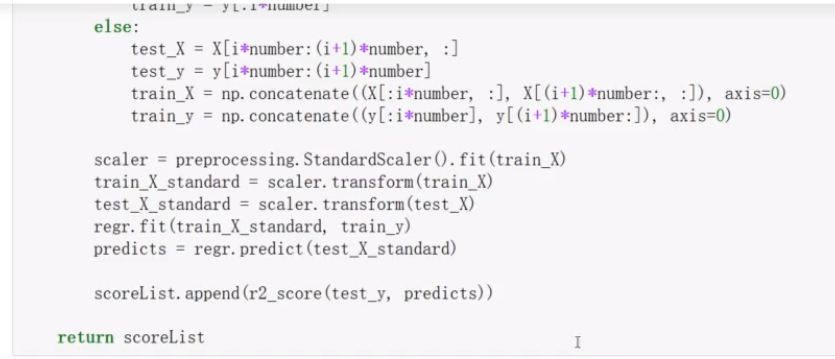
评估线性回归在原始数据集上的性能:
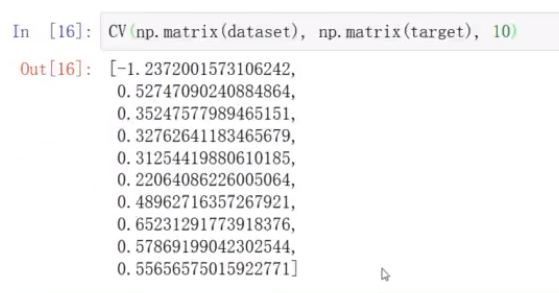
得到列表

对列表求平均值,这个就是最终得分
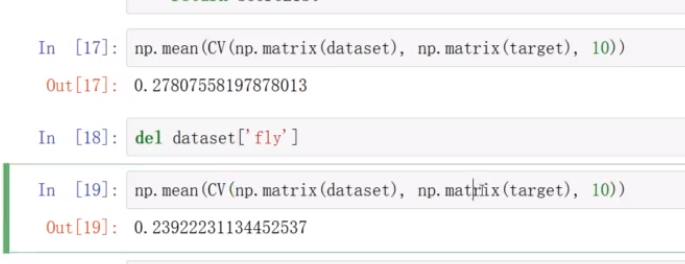
有的数据集中的数据没什么用,删除这样的特征,看看性能有没有变化
越接近1越好,删除的fly特征下降,说明fly特征有用
(4)保存模型
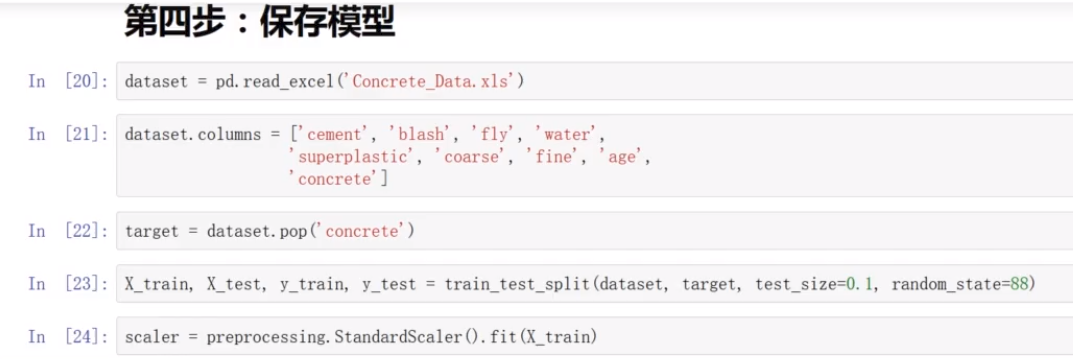
创建缩放器

数据集标准化

训练

将模型和缩放器保存
3.构建混凝土抗压强度预测系统
(1)加载模型
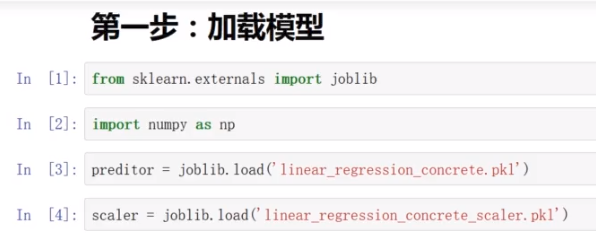
(2)构建预测系统
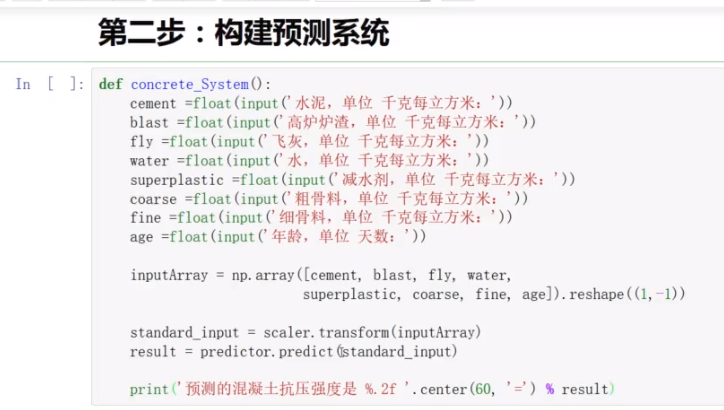
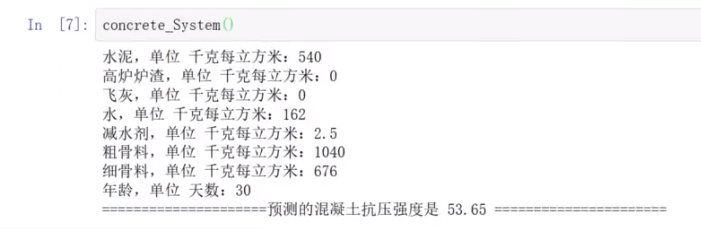
4.电影推荐系统
(1)收集数据

数据集:https://grouplens.org/datasets/movielens/

(2)准备数据
加载
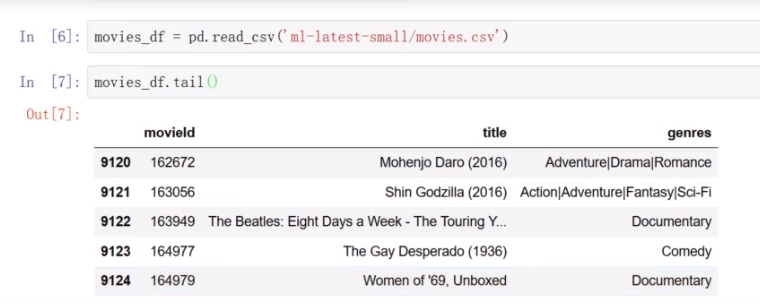
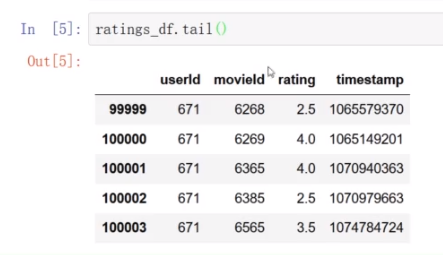
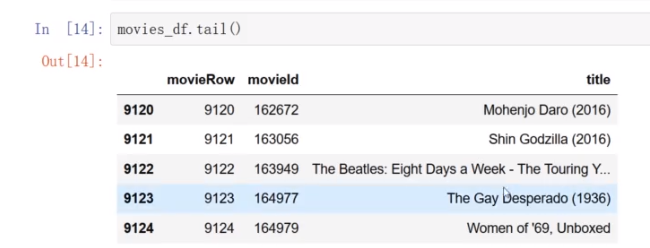
加载movies.csv文件,序号太大不适合行号
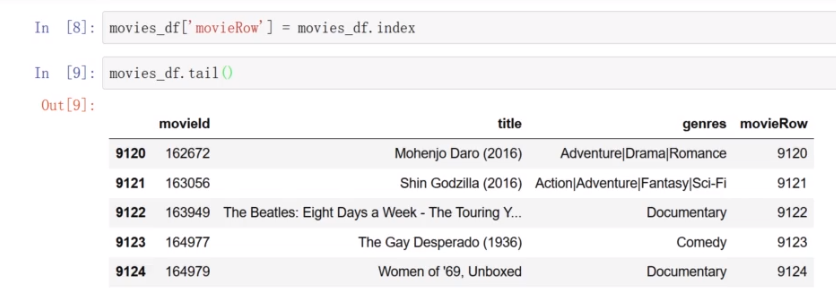
新增行号movieRow
*筛选movies_df中的特征

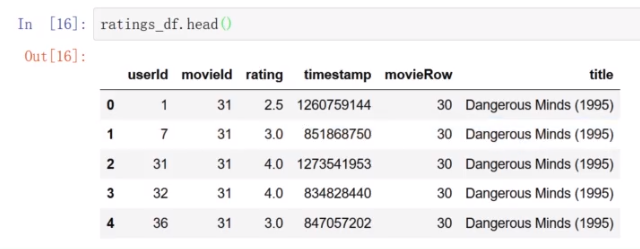
*将ratings_df中的movieid替换为行号


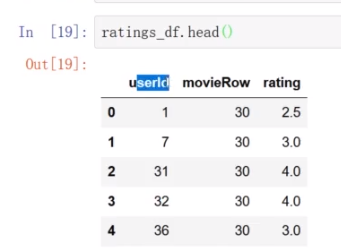
筛选之后的信息
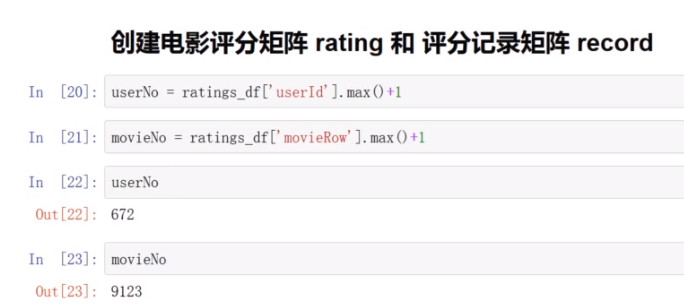
*创建电影评分矩阵rating和评分记录矩阵record

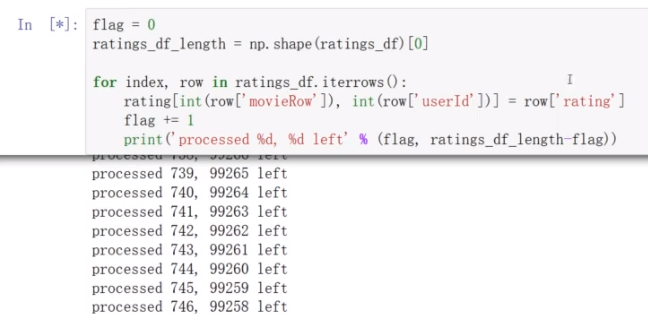
将rating_df中的数据填写到rating当中
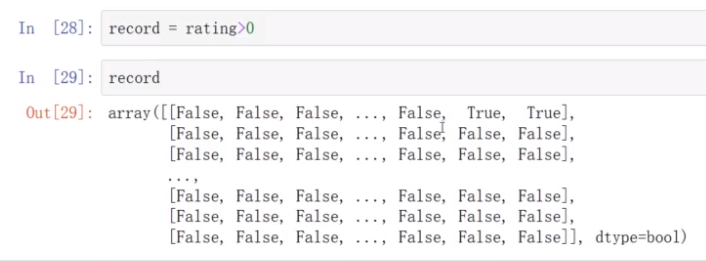
电影评分系统中,所有0的地方表示没有评分,>0表示凭过分
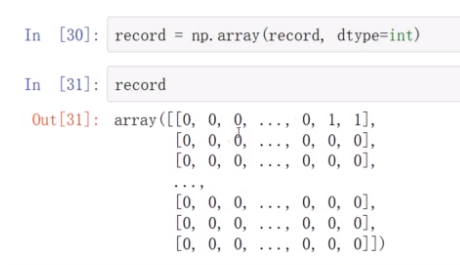
布尔值转化成0,1
电影评分表和评分记录表构建完成
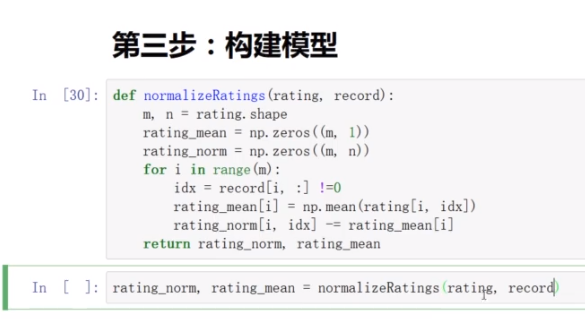
(3)构建模型


数据集中有的是0,要处理
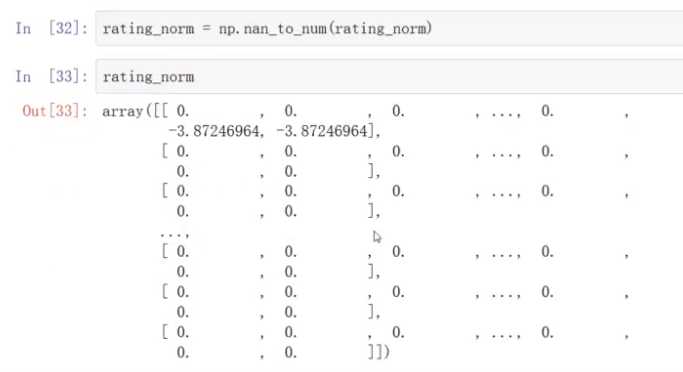
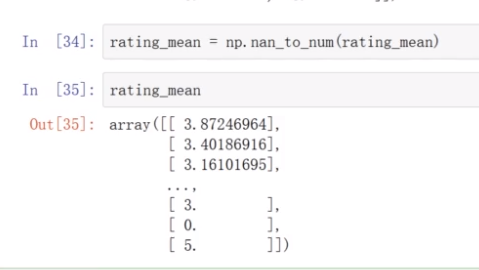
处理2个矩阵

X_parameters电影内容矩阵,Thetga_paramters用户喜好矩阵
正太随机分布


(4)训练模型
(5)评估模型
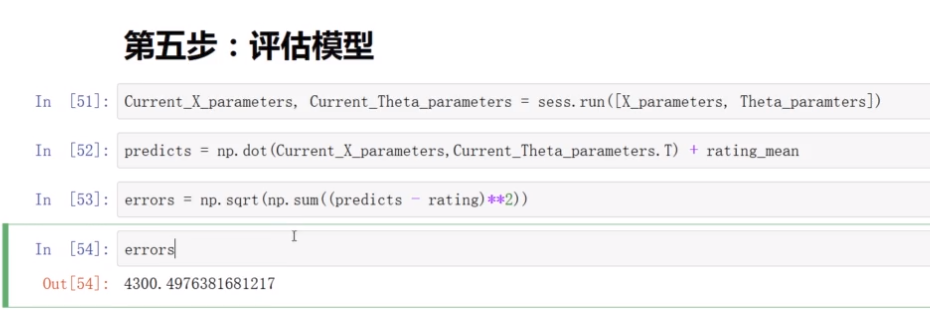
(6)构建完整的电影推荐系统


优化:如果用户看了电影,就要将该系统中电影去掉

















 2354
2354

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









