






 本文详细介绍了搜索引擎的基本组成部分及其工作原理,包括网络爬虫、索引系统和搜索系统等关键组件。此外,还探讨了网络爬虫的具体实现策略,如遵循robots协议、多线程技术以及前后向队列的工作机制。
本文详细介绍了搜索引擎的基本组成部分及其工作原理,包括网络爬虫、索引系统和搜索系统等关键组件。此外,还探讨了网络爬虫的具体实现策略,如遵循robots协议、多线程技术以及前后向队列的工作机制。
一. 搜索引擎
组成部分:
1. 网络爬虫(web crawler) 2. 索引系统(indexing system) 3. 搜索系统 (searching system)
consideration:
1.Economics 2.Scalability 3. Legal issue
二. 网络爬虫(web crawler)
web crawler 需要考虑两个问题:
politeness (遵守robots协议以及不要频繁访问同一个主机)
performance (多线程)
工作过程: 首先我们给爬虫一个初始的种子url集,然后爬虫下载这些url指向的页面,把内容提取出来交给索引系统,把页面中包含的url提取出来加入url池。
一个简易的爬虫算法
UrlsTodo = {‘‘yahoo.com/index.html’’}
Repeat:
url = UrlsTodo.getNext()
html = Download( url )
UrlsDone.insert( url )
newUrls = parseForLinks( html )
For each newUrl not in UrlsDone:
UrlsTodo.insert( newUrl )
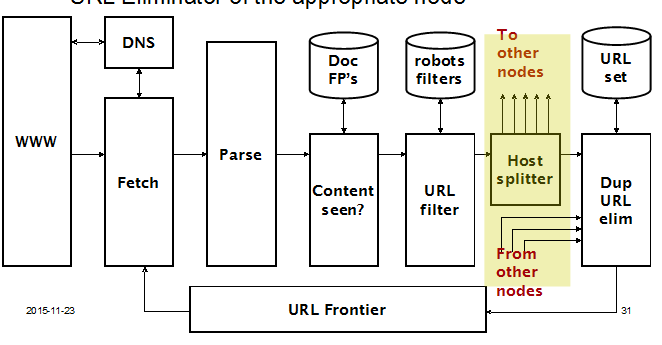
front queue 和 back queue 的工作过程:
前向队列: 爬虫从html文件中抽取出url, 如果这个url没有被访问过的话,那么就将它加入队列。将前向队列分成优先级1-N的不同的队列,当有一个url进入时,根据不同的策略,给这个url分配不同的优先级,并加入到对应的队列中。通常,我们将容易变化的网页赋予更高的优先级,如新闻。
后向队列:后向队列的分队方式,同一个主机为一个队列。每一个对列需要存储主机名和上次访问这个主机的时间。当爬虫要爬取一个网页时,从后向队列中以一定的策略抽取url,若访问这个url所在的主机的时间间隔小于最小时间间隔,那么,就暂时不爬取这个网页。
当后向队列有队列为空时,从前向队列中抽取一个url(按照优先级的策略),若这个url所在的主机没有在当前后向队列中,那么就把这个url加入到空的队列中。若这个url的主机已经存在在后向队列中,那么将这个url加入到那个主机的队列。再从前向队列中抽取一个url...

















 1224
1224

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









