






 本文介绍使用Python进行数据处理的方法,包括CSV文件读取、日期时间操作、NumPy基础使用、Pandas系列及DataFrame操作等核心内容。通过实例展示了数据处理的各种技巧。
本文介绍使用Python进行数据处理的方法,包括CSV文件读取、日期时间操作、NumPy基础使用、Pandas系列及DataFrame操作等核心内容。通过实例展示了数据处理的各种技巧。
1. Reading csv File
import csv #%precision 2 with open("mpg.csv") as csvfile: mpg = list(csv.DictReader(csvfile)) mpg[:3]
2. Dates and times demo
1 import datetime 2 import time 3 4 5 dtnow = datetime.datetime.fromtimestamp(time.time()) 6 print dtnow 7 8 # The use of datetime delta 9 delta = datetime.timedelta(days=1) 10 today = datetime.datetime.today() 11 print today - delta 12 print today > today-delta 13 14 #Output 15 #2017-06-04 11:09:29.497000 16 #2017-06-03 11:09:29.497000 17 #True
# Numpy introduction
1 import numpy as np 2 mylist = [1, 2, 3] 3 print np.array(mylist) 4 5 m = np.array([[1,2,3], [4,5,6]]) 6 print m.shape 7 8 print "\nThe use of arange:" 9 n = np.arange(0, 30, 2) 10 print n 11 12 print "\nThe use of reshape:" 13 print n.reshape(3, 5) 14 15 16 print "\nThe use of linspace(tell how many numbers we want:" 17 o = np.linspace(0, 4, 9) 18 print o 19 o.resize(3,3) 20 print o 21 22 print "\nRepeat function:" 23 print np.array([1, 2, 3]*3) 24 print np.repeat([1, 2, 3], 3) 25 26 print "\nCreate new array using stack:" 27 p = np.ones([2, 3], int) 28 print np.vstack([p, 2*p]) 29 print np.hstack([p, 2*p]) 30 31 print "\nArray transpose:" 32 print p.T 33 34 print "\ndtype:" 35 print p.dtype 36 37 print "\nastype:" 38 p = p.astype('f') 39 print p.dtype 40 41 print "\nArray operations: max min mean std argmax:" 42 a = np.array([-4, -2, 1, 3, 5]) 43 print a.sum(), a.max(), a.min(), a.std(), a.argmax(). argmin() 44 45 print "\nArray slice:" 46 r = np.arange(36) 47 r.resize(6,6) 48 print r 49 print r[:2, :-1] 50 print r[-1, ::2] 51 r[r>30] = 30 52 print r
Output


1 [1 2 3] 2 (2L, 3L) 3 4 The use of arange: 5 [ 0 2 4 6 8 10 12 14 16 18 20 22 24 26 28] 6 7 The use of reshape: 8 [[ 0 2 4 6 8] 9 [10 12 14 16 18] 10 [20 22 24 26 28]] 11 12 The use of linspace(tell how many numbers we want: 13 [ 0. 0.5 1. 1.5 2. 2.5 3. 3.5 4. ] 14 [[ 0. 0.5 1. ] 15 [ 1.5 2. 2.5] 16 [ 3. 3.5 4. ]] 17 18 Repeat function: 19 [1 2 3 1 2 3 1 2 3] 20 [1 1 1 2 2 2 3 3 3] 21 22 Create new array using stack: 23 [[1 1 1] 24 [1 1 1] 25 [2 2 2] 26 [2 2 2]] 27 [[1 1 1 2 2 2] 28 [1 1 1 2 2 2]] 29 30 Array transpose: 31 [[1 1] 32 [1 1] 33 [1 1]] 34 35 dtype: 36 int32 37 38 astype: 39 float32 40 41 Array operations: max min mean std argmax: 42 3 5 -4 3.26190128606 0 43 44 Array slice: 45 [[ 0 1 2 3 4 5] 46 [ 6 7 8 9 10 11] 47 [12 13 14 15 16 17] 48 [18 19 20 21 22 23] 49 [24 25 26 27 28 29] 50 [30 31 32 33 34 35]] 51 [[ 0 1 2 3 4] 52 [ 6 7 8 9 10]] 53 [30 32 34] 54 [[ 0 1 2 3 4 5] 55 [ 6 7 8 9 10 11] 56 [12 13 14 15 16 17] 57 [18 19 20 21 22 23] 58 [24 25 26 27 28 29] 59 [30 30 30 30 30 30]]
3. Pandas Series
1 import pandas 2 3 animals = ['Tiger', 'Bear', 'Moose'] 4 pandas.Series(animals) 5 6 numbers = [1, 2, None] 7 pandas.Series(numbers) 8 9 sports = { 10 "Archery": "Bhut", 11 "Golf": "Scotland" } 12 print pandas.Series(sports) 13 print pandas.Series(animals , index=['India', 'America', 'Canada'])
Output:
1 0 Tiger 2 1 Bear 3 2 Moose 4 dtype: object 5 6 0 1.0 7 1 2.0 8 2 NaN 9 dtype: float64 10 11 Archery Bhut 12 Golf Scotland 13 dtype: object 14 India Tiger 15 America Bear 16 Canada Moose 17 dtype: object
4. Pandas Dataframe
Basic
1 import pandas as pd 2 purchase_1 = pd.Series({'Name': 'Chris', 3 'Item Purchased': 'Dog Food', 4 'Cost': 22.50}) 5 purchase_2 = pd.Series({'Name': 'Kevyn', 6 'Item Purchased': 'Kitty Litter', 7 'Cost': 2.50}) 8 purchase_3 = pd.Series({'Name': 'Vinod', 9 'Item Purchased': 'Bird Seed', 10 'Cost': 5.00}) 11 df = pandas.DataFrame([purchase_1, purchase_2, purchase_3], index = ['Store 1', 'Store 1', 'Store 2']) 12 print df.loc['Store 2'] 13 print df.loc['Store 1', 'Cost'] 14 print 15 16 print df.T 17 print 18 19 df.drop('Cost', axis=1) 20 print df 21 print 22 23 df.drop('Cost', axis=1, inplace=True) #del df['Cost'] 24 print df 25 print 26 27 df["Location"] = None 28 print df 29 print
Output:
1 Cost 5 2 Item Purchased Bird Seed 3 Name Vinod 4 Name: Store 2, dtype: object 5 Store 1 22.5 6 Store 1 2.5 7 Name: Cost, dtype: float64 8 9 Store 1 Store 1 Store 2 10 Cost 22.5 2.5 5 11 Item Purchased Dog Food Kitty Litter Bird Seed 12 Name Chris Kevyn Vinod 13 14 Cost Item Purchased Name 15 Store 1 22.5 Dog Food Chris 16 Store 1 2.5 Kitty Litter Kevyn 17 Store 2 5.0 Bird Seed Vinod 18 19 Item Purchased Name 20 Store 1 Dog Food Chris 21 Store 1 Kitty Litter Kevyn 22 Store 2 Bird Seed Vinod 23 24 Item Purchased Name Location 25 Store 1 Dog Food Chris None 26 Store 1 Kitty Litter Kevyn None 27 Store 2 Bird Seed Vinod None
Loading
1 import pandas as pd 2 df = pd.read_csv('olympics.csv') 3 df.head() 4 5 #Skiprows and assign index column 6 df = pd.read_csv('olympics.csv', index_col=0, skiprows=1) 7 df.head() 8 9 # rename columns 10 df.columns 11 for col in df.columns: 12 if col[:2]=='03': 13 df.rename(columns={col:'Bronze' + col[4:]}, inplace=True)
Boolean mask
1 only_gold = df[df['Gold'] > 0] 2 only_gold.head() 3 #only_gold = df.where(df['Gold'] > 0) 4 #only_gold.head() 5 print len(df[(df['Gold'] > 0) | (df['Gold.1'] > 0)]) 6 df[(df['Gold.1'] > 0) & (df['Gold'] == 0)]

Indexing
1 df = pd.read_csv('census.csv') 2 df['SUMLEV'].unique() 3 columns_to_keep = ['STNAME', 4 'CTYNAME', 5 'BIRTHS2010', 6 'BIRTHS2011', 7 'BIRTHS2012', 8 'BIRTHS2013', 9 'BIRTHS2014', 10 'BIRTHS2015', 11 'POPESTIMATE2010', 12 'POPESTIMATE2011', 13 'POPESTIMATE2012', 14 'POPESTIMATE2013', 15 'POPESTIMATE2014', 16 'POPESTIMATE2015'] 17 df = df[columns_to_keep] 18 df = df.set_index(['STNAME', 'CTYNAME']) 19 df.loc['Michigan', 'Washtenaw County']
Output:

Missing value
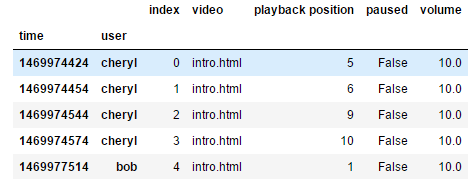
1 df = pd.read_csv('log.csv') 2 df = df.reset_index() 3 df = df.set_index(['time', 'user']) 4 df = df.fillna(method='ffill') 5 df.head()
Output:

















 469
469

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









