




例
使用基础包中state.x77的数据集,想研究犯罪率与其他的关系
states <- as.data.frame(state.x77[,c("Murder", "Population",
"Illiteracy", "Income", "Frost")]) #矩阵转化为数据框检查变量间的相关性
> cor(states)
Murder Population Illiteracy Income Frost
Murder 1.0000000 0.3436428 0.7029752 -0.2300776 -0.5388834
Population 0.3436428 1.0000000 0.1076224 0.2082276 -0.3321525
Illiteracy 0.7029752 0.1076224 1.0000000 -0.4370752 -0.6719470
Income -0.2300776 0.2082276 -0.4370752 1.0000000 0.2262822
Frost -0.5388834 -0.3321525 -0.6719470 0.2262822 1.0000000绘制散点图矩阵,注意使用的是scatterplotMatrix(),观察相关性
#如下图
library(car)
#scatterplot(states,spread=FALSE,smoother.args=list(lyt=2),main="Scatter Plot Matrix")
#scatterplot是绘制二维变量的时候使用scatterplot(x~y,spread=F,smoother.args=list[lyt=2],main="xx")
scatterplotMatrix(states,spread=FALSE,smoother.args=list(lyt=2),main="Scatter Plot Matrix")
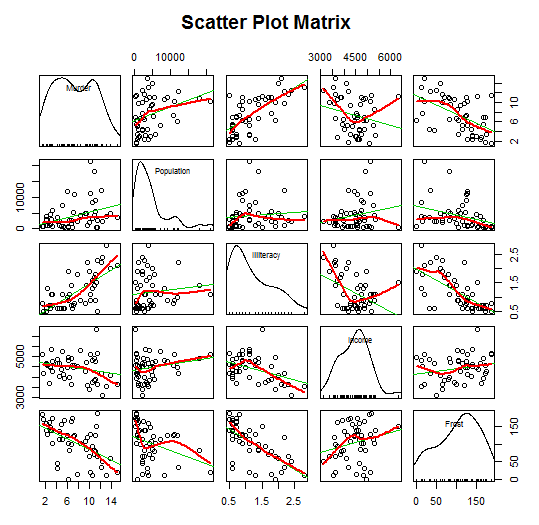
拟合多元线性回归模型
> fit <- lm(Murder ~ Population + Illiteracy + Income + Frost, data=states)
> summary(fit)
Call:
lm(formula = Murder ~ Population + Illiteracy + Income + Frost,
data = states)
Residuals: #残差的统计量,中位数接近0,表示接近标准正态分布,因为标准正态分布的中位数为0
Min 1Q Median 3Q Max
-4.7960 -1.6495 -0.0811 1.4815 7.6210
Coefficients: #coefficents为:系数的意思
Estimate Std. Error t value Pr(>|t|) # estimate 意思为:估计量(值) std.error表示标准误 ,t value :表示系数的t值,Pr(>|t|系数的p值
(Intercept) 1.235e+00 3.866e+00 0.319 0.7510 #Intercept 为 截距
Population 2.237e-04 9.052e-05 2.471 0.0173 *
Illiteracy 4.143e+00 8.744e-01 4.738 2.19e-05 *** #“*”号越多表示越显著 2.19e-05表示科学计数法, 2.19*10的负5次方即0.0000219
Income 6.442e-05 6.837e-04 0.094 0.9253
Frost 5.813e-04 1.005e-02 0.058 0.9541
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 2.535 on 45 degrees of freedom #Residual standard error 意思为:标准差,残差标准误,剩余标准差
Multiple R-squared: 0.567, Adjusted R-squared: 0.5285 #Multiple R-squared 意思为判定系数
F-statistic: 14.73 on 4 and 45 DF, p-value: 9.133e-08 #整句话为模型的整体检验,就是F检验,F-statistic为F-统计量,p-value为 p值,
#在统计学上 回归系数需要进行检验,回归系数是通过样本计算的,因而带有一定的随机性
#对r进行检验 ,如 y = β1 + β2X
# H0: β2 = 0,回归系数在统计上不显著,解释变量 X 对 Y 无显著影响
# H1: β2 ≠ 0,回归系数在统计上显著,解释变量 X 对 Y 有显著影响
#构建统计量:t检验
#决策:如果 |t| >= ta/2,落入拒绝域,拒绝 H0,接受H1,证明 系数在统计上是显著的,如果 |t| <= ta/2,则接受 H0,表明系数在统计上是不显著的
#利用 p值决策,如果 p <= a,表示比小概率事件否发生了,所以要拒绝 H0,解释变量X 对解释变量 Y 有显著影响,相反 p <= a,接受H0,解释变量 X 对被解释变量 Y 无显著影响
#更多参考链接:简单线性相关系数r及检验,p值决策当预测变量不止一个时,回归系数的含义为:一个预测变量增加一个单位,其他预测变量保持不变时,因变量将要增加的数量
本例中,文盲率的回归系数为4.14,表示控制人口、收入和温度不变时,文盲率上升1%,谋杀率将会上升4.14%,它的系数在 p < 0.001的水平下显著不为 0。
相反,Frost的系数没有显著不为 0 (p=0.945),表明当控制其他变量不变时,Frost 与 Murder不呈线性相关。
总体来说,所有的预测变量解释了各州谋杀率57%的方差
参考
简单线性相关系数 r 及检验
p值决策
R语言如何直接提取回归中的t值和P值 - R语言论坛 - 经管之家(原人大经济论坛)

















 821
821

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









