







目录
1 什么是堆
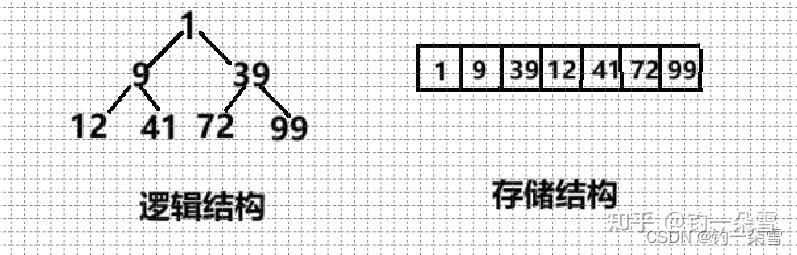
堆是一种特殊的数据结构,它是一棵完全二叉树。把所有的元素按照完全二叉树的结构,按照层序遍历的顺序储存在一维数组中,如果该二叉树满足父节点小于等于子节点,叫做最小堆(小根堆);如果该二叉树满足父节点大于等于子节点,叫做最大堆(大根堆)。
2 堆的实现
2.1 堆类型的创建
堆的物理结构本质上是顺序存储的,是线性的。但在逻辑上不是线性的,是完全二叉树的这种逻辑储存结构。
堆的这个数据结构,里面的成员包括一维数组,数组的容量,数组元素的个数。
typedef int HPDataType;
typedef struct heap
{
HPDataType *arr;
int size;
int capacity;
}Heap;2.2 堆的初始化
void HeapInit(Heap* hp)
{
assert(hp);
hp->arr = NULL;
hp->size = hp->capacity = 0;
}2.3 向下调整算法
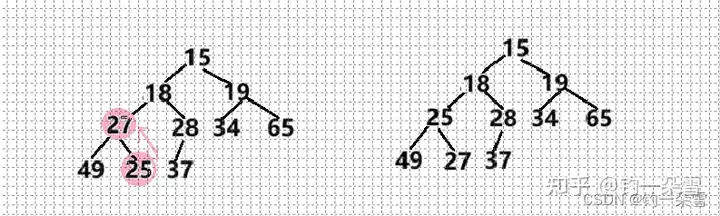
有这样一个数组int arr[]={27,15,19,18,28,34,65,49,25,37};要它调整成小根堆。
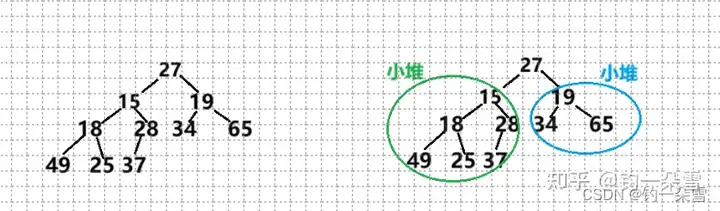
这个数组比较特殊,除了根结点,左右两颗子树都构成的小堆,所以只要将根结点调整到合适位置就可以了
首先看27的两个孩子,并找出两个孩子结点的最小值与27比较大小,27大于孩子结点的最小值15,所以不满足小根堆的条件要进行调整,将最小的孩子结点和根结点调换位置
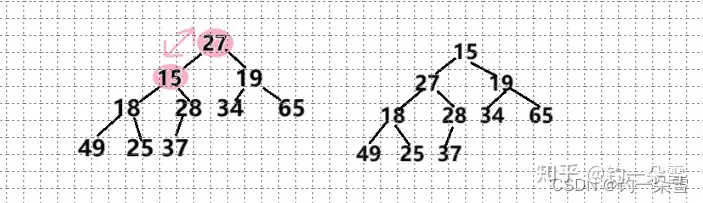
交换完之后以交换的位置为根结点,继续和其孩子结点比较
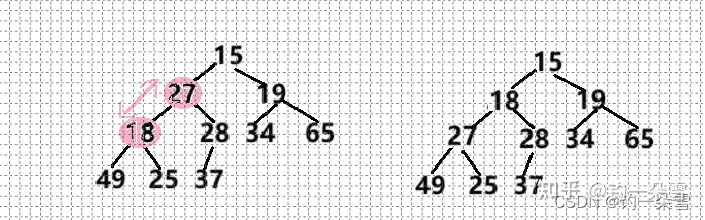
思路
- 向下调整算法的操作对象是根节点(父结点)
- 首先根据根节点求出两个孩子结点中最小值的下标
- 然后用孩子结点最小值与根结点比较:
- 如果根节点比最小值大,那么就不满足小根堆的定义,所以将子结点与根结点交换,并继续向下重复上面的程序,直到子结点的下表超过数组的大小
- 如果根结点比最小值小,因为左右子树都是小根堆所以,根结点就是数组的最小值,便不用调整,直接结束就行了。
代码
void swap(int *a, int *b)
{
int c = *a;
*a = *b;
*b = c;
}
/* 向下调整算法(小根堆):传入父节点,并与较小的子节点进行交换,递归致最后一个父节点 */
void AdjustDownLittle(int *a, int n, int parent)
{
int child = 2 * parent + 1;//默认左孩子更小
if (child + 1 < n && a[child + 1] < a[child])
child++;
if (child < n && a[child] < a[parent]) {
swap(&a[child], &a[parent]);
AdjustDownLittle(a, n, child);
}
}
/* 向下调整算法(大根堆):传入父节点,并与较大的子节点进行交换,递归致最后一个父节点 */
void AdjustDownBig(int *a, int n, int parent)
{
int child = 2 * parent + 1;//默认左孩子更大
if (child + 1 < n && a[child + 1] > a[child])
child++;
if (child < n && a[child] > a[parent]) {
swap(&a[child], &a[parent]);
AdjustDownBig(a, n, child);
}
}2.4 向上调整算法
思路和向下调整算法差不多

/* 向上调整算法(小根堆):传入子节点,并与父节点进行交换,递归致堆顶部一个子节点 */
void AdjustUpLittle(int* a, int child)
{
int father = (child - 1) / 2;
if (child > 0 && a[father] > a[child]) {
swap(&a[child], &a[father]);
AdjustUpLittle(a, father);
}
}
/* 向上调整算法(大根堆):传入子节点,并与父节点进行交换,递归致堆顶部一个子节点 */
void AdjustUpBig(int* a, int child)
{
int father = (child - 1) / 2;
if (child > 0 && a[father] < a[child]) {
swap(&a[child], &a[father]);
AdjustUpBig(a, father);
}
}2.5 堆的插入
- 在堆尾插入并保持堆的结构不变
- 对堆尾插入的那个元素进行向上调整

void HeapPush(Heap* hp, HPDataType x)
{
assert(hp);
//判断是否需要扩容
if (hp->size == hp->capacity)
{
int newcapcity = hp->capacity == 0 ? 4 : hp->capacity * 2;
HPDataType* newarr = (HPDataType*)realloc(hp->arr, newcapcity * sizeof(HPDateType));
if (newarr == NULL)
exit(-1);
hp->arr = newarr;
hp->capacity = newcapcity;
}
hp->arr[hp->size] = x;
hp->size++;
//向上调整
AdjustUpLittle(hp, hp->size - 1);
}2.6 堆的删除
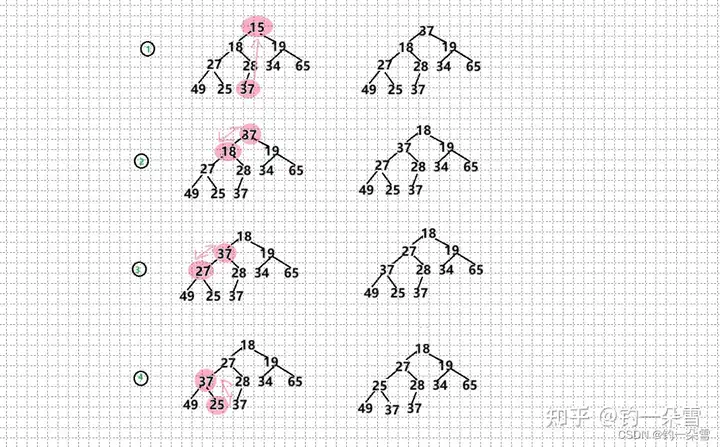
删除堆顶的数据,同时保持堆的结构不变
如果直接删除堆顶的元素的话,堆的结构就会被破坏,就必须要重新建堆,所以这里采取的方法是:
将堆的最后一个元素和堆顶的元素交换,删除堆最后一个元素(size–),并对整个堆进行一次向下调整
void HeapPop(Heap* hp)
{
assert(hp);
assert(hp->size);
swap(&(hp->arr[0]), &(hp->arr[hp->size - 1]));
hp->size--;
//向下调整
adjustdown(hp, 0);
}2.7 堆的销毁
void HeapDestrop(Heap* hp)
{
assert(hp);
free(hp->arr);
hp->size = hp->capacity = 0;
}2.8 打印堆
void HeapPrint(Heap* hp)
{
assert(hp);
for (int i = 0; i < hp->size; i++)
{
printf("%d ", hp->arr[i]);
}
printf("\n");
}
void HeapPrint2(Heap* hp)
{
assert(hp);
int i = 0; j = 1;
for (int i = 0; i < hp->size; i++)
{
printf("%d ", hp->arr[i]);
if (i == 0) {
printf("\n");
}
if (2 << (j) == i + 2) {
j++;
printf("\n");
}
}
printf("\n");
}3 创建堆
上述举例中,只有一个数是不满足堆的条件,通过一次调整完成了堆的实现。那么如果给一个无序的数组该如何通过向上/向下调整算法实现堆?
3.1 向下调整建堆
由于向下调整算法实现堆需要满足:给定的父节点的左子树和右子树必须是大根堆或小根堆
所以对于一个无序的数组可以从最后一棵子树开始调整,到根节点为止。这样每个的父节点下面的左子树和右子树都是大根堆或小根堆。
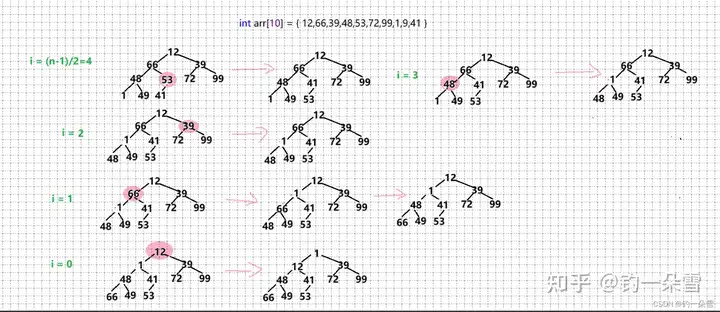
时间复杂度:O(N)

代码
/* 向下调整建堆:从堆的最后一个父节点开始,从下往上(倒序)对每个父节点进行向下调整 */
void HeapCreate_AdjustDown(Heap *h, int a[], int n)
{
for (int i = n/2 - 1; i >= 0; i--)
AdjustDownLittle(a, n, i);
memcpy(h->root, a, sizeof(int) * n);
h->size = n;
}
3.2 向上调整建堆
向上调整算法的操作对象是子节点,那么可以从堆顶部的第1个子结点开始调整,直到最后一个子节点结束。这样每次调整都能保证被调整的结点以上的树都是堆结构,通过n-1次调整即可完成堆的构建。
时间复杂度:O(NlogN)

代码
/* 向上调整建堆:从堆的第一个子节点开始,从上到下(顺序)对每个子节点进行向上调整 */
void HeapCreate_AdjustUp(Heap *h,int a[], int n)
{
for (int i = 1; i < n; i++)
AdjustUpLittle(a, n, i);
memcpy(h->root, a, sizeof(int) * n);
h->size = n;
}4 堆排序
给我一组数据,如果对他进行堆排序,那么前提就需要把它变成一个堆的形式。
时间复杂度:O(NlogN)
升序
建大根堆。堆顶一定是最大的,通过不断地将当前最大的元素与末尾元素进行交换,并重新调整剩余元素形成新的堆(调整时不包含交换后最后一个元素),这样依次可以得到次大的,通过循环n - 1次,最终得到一个升序的数组。
void HeapSort(Heap *hp)
{
int i = 0, n = hp->size, *a = hp->arr;
assert(hp);
assert(a);
//向下调整算法构建大根堆
for (i = n/2 - 1; i >= 0; i--) {
AdjustDownBig(a, n, i);
}
//排序O(N * logN)
for (i = n - 1; i > 0; i--) {
swap(&a[0], &a[n - 1 - i]);
AdjustDownBig(a, i, 0);
}
}降序
建小根堆。堆顶一定是最小的,通过不断地将当前最小的元素与末尾元素进行交换,并重新调整剩余元素形成新的堆(调整时不包含交换后最后一个元素),这样依次可以得到次小的,通过循环n - 1次,最终得到一个降序的数组。
void HeapSort2(Heap *hp)
{
int i = 0, n = hp->size, *a = hp->arr;
assert(hp);
assert(a);
//向下调整算法构建小根堆
for (i = n/2 - 1; i >= 0; i--) {
AdjustDownLittle(a, n, i);
}
//排序O(N * logN)
for (i = n - 1; i > 0; i--) {
swap(&a[0], &a[n - 1 - i]);
AdjustDownLittle(a, i, 0);
}
}5 TOP-K问题
对于求数据中前K个最大的元素或者最小的元素的问题,堆的应用可以有效地解决。通过构建一个最大堆(或最小堆),然后不断地删除堆顶元素,直到找到K个元素为止。这个过程的时间复杂度主要取决于构建堆的时间和删除堆顶元素的时间,通常这些操作的时间复杂度都是O(NlogN)
6 时间复杂度对比
| 向下调整建堆 | O(N) |
| 向上调整建堆 | O(NlogN) |
| 堆排序 | O(NlogN) |
| TOP-K问题 | O(NlogN) |
-
堆的建立:堆的建立包括向上调整建堆和向下调整建堆两种操作。向上调整建堆的时间复杂度为O(NlogN),而向下调整建堆的时间复杂度为O(N)。这表明向下调整建堆在效率上更高。
-
堆排序:堆排序是通过构建堆后,通过一系列的交换操作来实现排序。在构建堆的过程中,主要涉及到的是向下调整建堆的操作,其时间复杂度为O(N)。在排序阶段,通过不断地将当前最大的元素(或最小的元素)与末尾元素进行交换,并重新调整剩余元素形成新的堆,这个过程的时间复杂度也是O(N)。因此,堆排序的总时间复杂度为O(NlogN),这是因为构建堆的时间复杂度O(logN)与排序阶段的时间复杂度O(N)相乘得到的。
-
TOP-K问题:对于求数据中前K个最大的元素或者最小的元素的问题,堆的应用可以有效地解决。通过构建一个最大堆(或最小堆),然后不断地删除堆顶元素,直到找到K个元素为止。这个过程的时间复杂度主要取决于构建堆的时间和删除堆顶元素的时间,通常这些操作的时间复杂度都是O(NlogN)。
7 堆的应用场景
堆的应用场景主要包括堆排序、构建优先队列、求Top K值问题、求中位数、合并有序文件、流数据中的第K大元素等。
7.1 堆排序
升序
建大根堆。堆顶一定是最大的,通过不断地将当前最大的元素与末尾元素进行交换,并重新调整剩余元素形成新的堆(调整时不包含交换后最后一个元素),这样依次可以得到次大的,通过循环n - 1次,最终得到一个升序的数组。
降序
建小根堆。堆顶一定是最小的,通过不断地将当前最小的元素与末尾元素进行交换,并重新调整剩余元素形成新的堆(调整时不包含交换后最后一个元素),这样依次可以得到次小的,通过循环n - 1次,最终得到一个降序的数组。
7.2 构建优先队列
构建优先队列:堆可以用来实现优先队列,其中优先级高的元素位于队列的前面。在Java中,PriorityQueue就是一个典型的优先级队列实现,它通常使用堆来实现。优先队列在许多应用中都非常有用,例如任务调度、事件通知等。
7.2.1 定时任务轮训
定时任务或者分布式定时任务的场景我们都开发过,用户(开发或者运营)可以在页面操作,添加或修改定时任务的执行时间,当然一般会使用cron表达式进行配置【我们可以解析成具体的时间】。或者自己之前做商品系统时,里面有一个打标的开始和结束时间,怎么才能让开始时间去做一些事,结束时间到了再触发做一些事呢?
没错,我们使用的就是轮训的方式,两个定时任务专门扫描开始和结束时间,按照时间倒排序,找到需要触发的数据。轮训扫描需要有执行的间隔机制,如果扫描太频繁会影响性能,如果扫描时间间隔太大,扫描时发现本来应该是5分钟之前触发执行的数据,只有到了扫描间隔才知道。 所以两个弊病就是 浪费资源(可能1天后执行的任务,被扫描多次)、执行不及时(本来上次扫描完过几秒钟就该执行的)。
这样的场景其实就可以使用一个小顶堆进行处理,先扫描一次将所有数据都添加到小顶堆中,堆顶元素就是最先会被执行的任务。那么在堆顶任务执行之前其他任务肯定不可能执行。获取堆顶任务,到点执行的同时,【可以并行】再来获取下一个堆顶元素,数据结构 - 堆中我们知道,当获取了堆顶元素后,堆内部会再执行从上往下的堆化操作,获取次小元素放在堆顶。
7.2.2 合并有序文件
当有多个有序的小文件需要合并成一个大的有序文件时,可以使用堆来处理。通过将每个小文件的第一行数据添加到小顶堆中,然后依次从堆顶取出数据并合并到一个大文件中,最终得到一个整体有序的大文件。
举例
有1000个小文件中存储了有序的字符串信息,我们需要将所有的有序小文件合并成一个大文件。比如 文件3.txt存储了【123,...555】 ,文件 8.txt 存储了 【556,... ,888】,最终需要将所有文件合并成整体有序文件。
此时我们就可以创建一个堆,遍历所有小文件,都获取第一行数据添加到小顶堆中。比如Java的PriorityQueue<E>,泛型存储的就是第一行字符串和小文件的文件名,实现Comparator接口,回调函数比较的就是字符串的大小,那么我们最后只需要依次从堆顶获取元素,依次将所有小文件添加到大文件中,得到的就是合并之后的整体有序大文件。
7.2 求Top K值问题
堆也常用于找出数组中的最大的前K个数或最小的前K个数。通过维护一个大小为K的堆,可以高效地找到Top K的元素。
例如,如果需要找出出现次数最多的5种字符串,可以使用一个小顶堆来维护这5个元素,当新的元素出现次数超过堆顶元素时,就替换堆顶元素并进行堆调整,最后堆顶的元素就是出现次数第5多的字符串。
例如,如果求数组中最小的K个数。可以使用一个大顶堆来维护这K个元素,当大顶堆数量不足K个时,新产生的元素直接插入大顶堆。当大顶堆元素梳理超出K时,则将堆顶部最大元素进行出队删除并进行堆调整。最终形成的由最小的K个元素组成的大顶堆。将大堆依次出队,按照倒序方式放入数组中,即可得到最小的K个数。
示例代码
public int[] smallestK(int[] arr, int k) {
PriorityQueue<Integer> queue = new PriorityQueue<>((o1, o2) -> o2 - o1);
for (int i = 0; i < arr.length; i++) {
//插入大顶堆并调整堆
queue.add(arr[i]);
if (queue.size() > k) {
//删除堆顶元素并调整堆
queue.poll();
}
}
int[] ans = new int[queue.size()];
int i = k - 1;
while (i>=0) {
ans[i--] = queue.poll(); //依次获取大顶堆的堆顶元素,并重新调整堆
}
return ans;
}
流数据中的第K大元素
在处理流数据时,如果需要快速找到第K大的元素,可以使用堆来维护一个大小为K的集合,并保持其有序性。这种方法在处理大量数据时非常有效。
7.3 求中位数、百分位数
使用两个堆(一个大顶堆和一个小顶堆)可以高效地求出一组数据的中位数。这种方法适用于需要频繁更新数据并计算中位数的场景。
求中位数就是求一连串数据排序后的中间数,如果数据个数是奇数,那么中位数就是N/2(下标从0开始),如果数据个数是偶数,那么中位数就是(N/2-1+N/2)/2。
用堆实现的方式就是维护两个堆,一个大顶堆和一个小顶堆。如果数据是奇数个,大顶堆就存储N/2+1个数据,小顶堆则存在N/2个数据,如果是偶数,大顶堆和小顶堆就分别存储N/2个数据,
最后我们要求,小顶堆中的数据都要大于大顶堆中的数据。
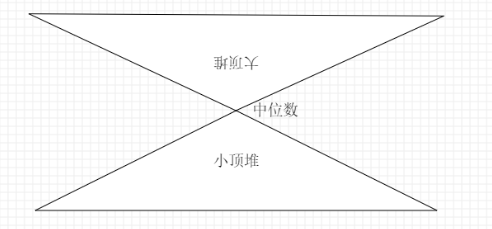
如果新添加的数据小于等于大顶堆的堆顶元素,那么就直接添加到大顶堆,否则就将数据添加到小顶堆,此时可能两个堆的数量不平衡了,如果大顶堆的数据多,那我们就把大顶堆的第一个元素添加到小顶堆,我们小顶堆多,我们就把小顶堆的第一个元素添加到大顶堆,最后我们取中位数时,如果是奇数个,只需要从大顶堆中取出第一个元素即可,如果是偶数个,就分别从大顶堆和小顶堆各取第一个,然后除以2即可。
百分位数:计算方式同上。例如百分80位置,则小顶堆个数永远维护为 N*80%个
综上所述,堆作为一种数据结构,由于其高效的排序和维护特性,在计算机科学中有着广泛的应用场景。
7.4 统计搜索排行榜
有10亿(或者50G)的大数据量的查询关键词,需要进行排序求Top K,类似在搜索引擎框中提示。分为两种情况,看能否一次性加载到内存中:
可以一次性加载到内存中:
可以基于散列表读写的时间复杂度近似O(1),统计每个搜索词出现的次数,再使用堆或者优先级队列 处理类似上面 TopK的思路(也是堆化的过程),最后再进行堆排序就是想要的排序结果。
不能一次性加载到内存中:
使用Hash算法将大文件散列到多个(根据预计算得出,比如10亿条数据,平均每条多大,总共多大数据,每次可以加载多少道内存中处理)文件中, 为了防止TopK的数据都退化到一个子文件中,所以每个子文件都要获取前TopK的值,最后将所有值进行合并,就得到了最后的 TopK。

















 995
995

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









