






 本文介绍了Pandas的基础操作,包括Series和DataFrame的创建、属性、数据获取与保存,以及数据筛选方法如loc和iloc的使用。通过实例展示了如何读取CSV和Excel数据,以及如何进行数据筛选和删除。
本文介绍了Pandas的基础操作,包括Series和DataFrame的创建、属性、数据获取与保存,以及数据筛选方法如loc和iloc的使用。通过实例展示了如何读取CSV和Excel数据,以及如何进行数据筛选和删除。

- pandas常用数据结构
- 数据获取与保存
- 数据筛选
一、常用数据结构(pandas是基于numpy的)
Series(序列)
- 由一组数据以及一组与之对应的数据标签(即索引)组成
- 可以通过pandas.Series来创建Series,每个Series可以看成式DataFrame的一个列
a、创建一个序列
import numpy as np
import pandas as pd
#创建序列既可以用列表,字典,也可以用np的数组结构 其中index是每个序列的索引,name是该对象的名字
series1 = pd.Series([2.7,3.01,8.99,8.59,5.18],index=['a','b','c','d','e'],name='This is a series')
series2 = pd.Series(np.array([2.7,3.01,8.99,8.59,5.18]),index=['a','b','c','d','e'],name='This is a series2')
print(series1)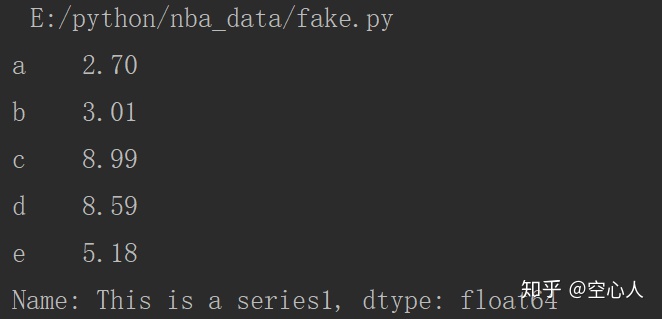
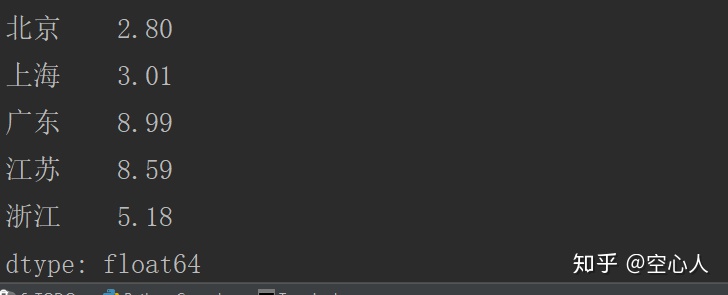
注:上述参数中,index表示的是索引,必须与数据等长度,name代表对象名称
b、series常用属性
- value:返回Series对象所有元素
- index:返回索引
- dtypes:返回数据类型
- shape:返回series数据形状
- ndim:返回对象维度
- size:返回对象个数
import numpy as np
import pandas as pd
series = pd.Series({'北京':2.8,'上海':3.01,'广东':8.99,'江苏':8.59,'浙江':5.18})
print(series.values)
print(series.index)
print(series.index.values) # 输出的是array 索引
print(series.dtypes)
print(series.ndim)
print(series[0:3]) # python是左开右闭的,第四行元素是去不到的
print(series['北京']) # 输出北京的值
print(series['北京':'广东']) # 输出北京到广东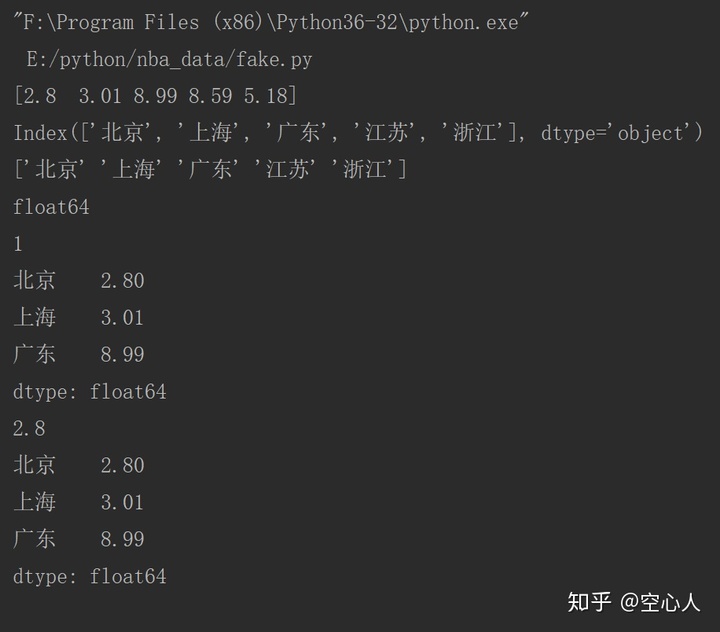
series拼接,修改,删除:
import numpy as np
import pandas as pd
series1 = pd.Series({'北京':2.8,'上海':3.01,'广东':8.99,'江苏':8.59,'浙江':5.18})
series2 = pd.Series({'四川':3.8,'重庆':2.01})
series1 = series1.append(series2) #将series2拼接到series1后面
print(series1)
#修改
series1['北京'] = 2.89
print(series1)
#删除 删除这里要注意下,加上inplace = True 才是真正对元素进行删除,如果不加只是对视图
#进行删除,此时并没有真正的删除掉
series1.drop(['四川'],inplace=True)
print(series1) 注:重点注意删除的时候要加上inplace = True 才能够把元素真正的删除
DataFrame
- DataFrame是pandas基本数据结构,类似于数据库中的表或者EXCEL中的表格数据格式
- DataFrame既有行索引,也有列索引,可以看成十多个Series组成的
- 通过pandas.DataFrame来创建DataFrame数据结构
- pandas.DataFrame(data,index,dtype,columns)
- 上述参数中,data可以为列表,array或者dict
- 上述参数中,index表示航索引,columns代表列名或者列标签
a、创建DataFrame的三种方法
import numpy as np
import pandas as pd
list = [['张三','男',23],['李四','男',25],['王五','女',18]]
array =np.array(list)
#[['张三', '男', 23], ['李四', '男', 25], ['王五', '女', 18]]
df1 = pd.DataFrame(list,columns=['姓名','性别','年龄']) #列表
df2 = pd.DataFrame({'姓名':['张三','李四','王五'],'性别':['男','男','女'],'年龄':[23,25,18]}) #字典
df3 = pd.DataFrame(array,columns=['姓名','性别','年龄']) #array
print(df1)
print(df2)
print(df3)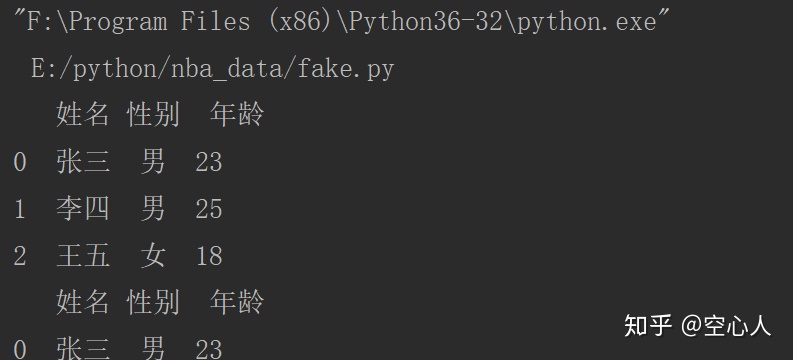
b、DataFrame的常用属性
- values:返回Series对象所有元素
- index:返回索引
- dtypes:返回每一列的数据类型
- shape:返回series数形状
- ndim:返回对象维度
- size:返回对象个数
- columns:返回列标签
import numpy as np
import pandas as pd
list = [['张三','男',23],['李四','男',25],['王五','女',18]]
array =np.array(list)
#[['张三', '男', 23], ['李四', '男', 25], ['王五', '女', 18]]
df1 = pd.DataFrame(list,columns=['姓名','性别','年龄']) #列表
df2 = pd.DataFrame({'姓名':['张三','李四','王五'],'性别':['男','男','女'],'年龄':[23,25,18]})
df3 = pd.DataFrame(array,columns=['姓名','性别','年龄'])
print(df1)
print(df1.shape) #输出数据有几行几列
print(df1.dtypes) # 输出每一列数据的类型
print(df1.columns) # 输出属性有哪些列名
print(df1.columns.tolist()) # 以列表的形式输出
print(df1.ndim) #输出数据的维度
print(df1.size) # 输出数据由几个元素构成
print(df1.index.tolist()) #输出该对象的列标签
二、数据的获取与保存
- pandas内置了10多种数据源读取函数,常见的就是CSV和EXCEL
- pandas读取出来的数直接是数据框格式,方便后续的数据处理和分析
- 可以快速将数据保存为CSV或者EXCEL格式
- 参数较多,可以自行控制,但很多时候用默认参数
- 读取CSV时,注意编码,常用编码为utf-8,gbk,gbk2312等
a、读取csv数据
import os
import pandas as pd
os.getcwd() #获取当前的路径
os.chdir('C:data第三章') #将python的路径改为刚刚获取的当前路径
#经过上一步之后下面的路径可以直接写成文件的名称 凡是文件中有中文的就将编码改为gbk dtype:将info_id这个变量以字符串类型去读取
#nrow=10 代表只读取前10行 sep:分隔符,默认是, header:表示以第几行为表头,默认第0行
df = pd.read_csv('meal_order_info.csv',encodind='gbk',dtype={'info_id':str},nrow=10,sep=',',header=0)
df.head(5) #查看前5行
df.tail(5) #查看最后5行
df.types #查看每一列变量数据的类型
b、读取excel数据

注:sheet_name表示工作页名称
连续读取多个工作页(重点)
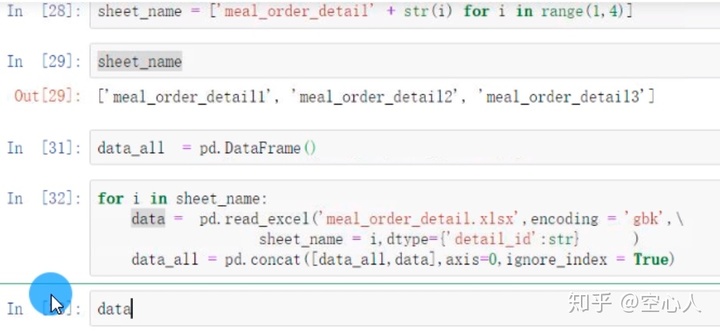
c、保存数据

index=False:表示不写入自动生成的索引
三、数据筛选
方法:
- 基础索引方式,就是直接引用
- ioc[行索引名称或者条件,列索引名称或者标签]
- iloc[行索引位置,列索引位置]
- 增删改查和条件查询
- 熟练掌握drop(labels,axis,inplace=True)的用法
a、直接引用
第一步:按照上面的读取excel数据的方法读取数据
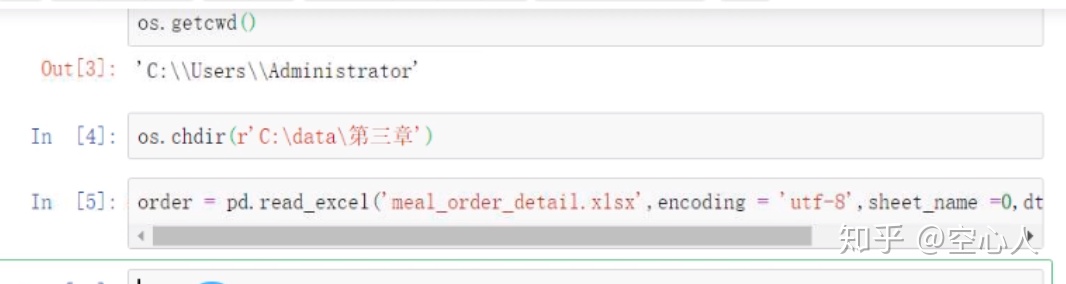
第二步:读取到数据之后可以先看看数据的前五行,后五行,看看数据有哪些列名,看看数据的类型有哪些:
order.head(5) #查看数据前五行有什么
order.tail(5) #查看数据后五行有什么
order.columns #查看数据有哪些列名
order.dtypes #查看数据有哪些类型
order.ndim #查看数据的维度
order.shape #查看数据有多少行多少列
order.size #查看总共有多少个元素 就等于行数乘以列数
order.[:10] #查看前10行,显示得是0-9行第三步:数据选择
选择数据中某一变量:
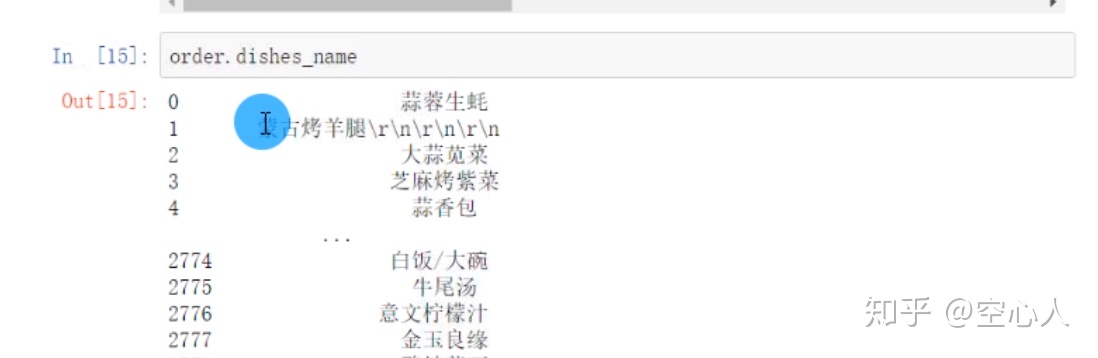
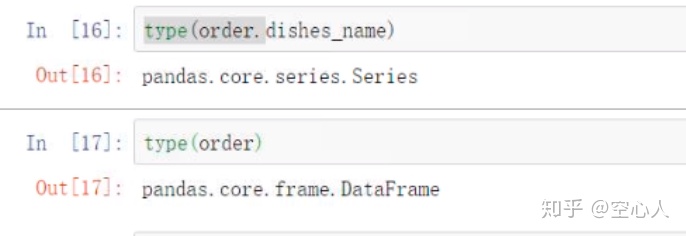
查看其数据结构:order是dataframe,而变量是series
选取多列的指定行数:(选取前50行)
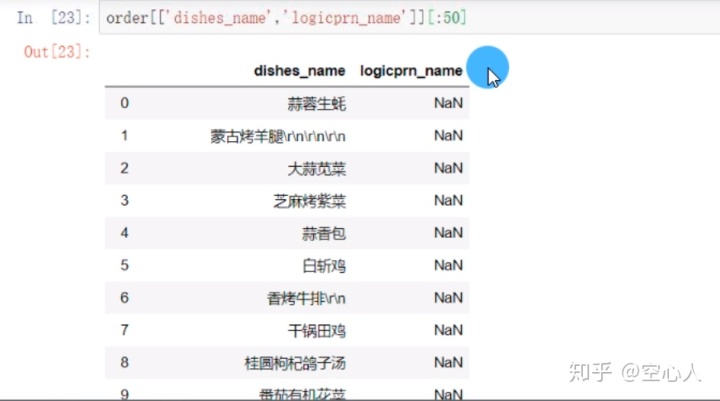
b、loc和iloc的用法:
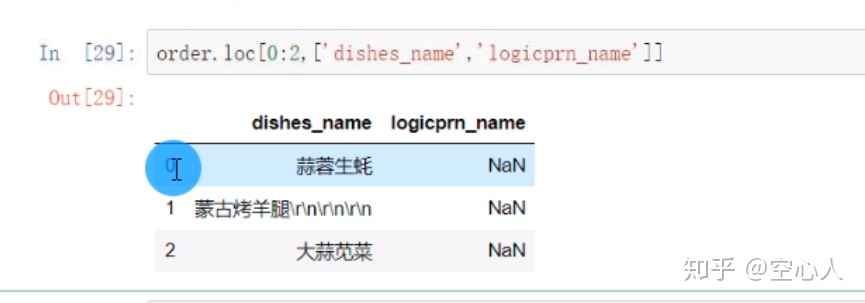
loc 指定选取哪些行,哪些列:

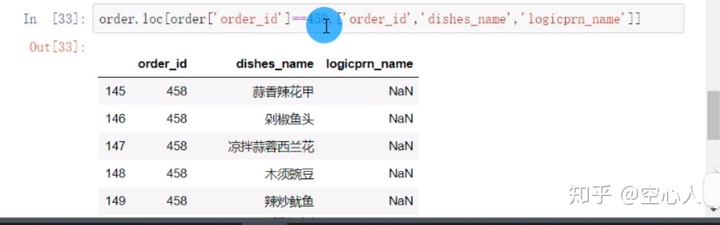
筛选出满足指定变量等于多少的所有的行:
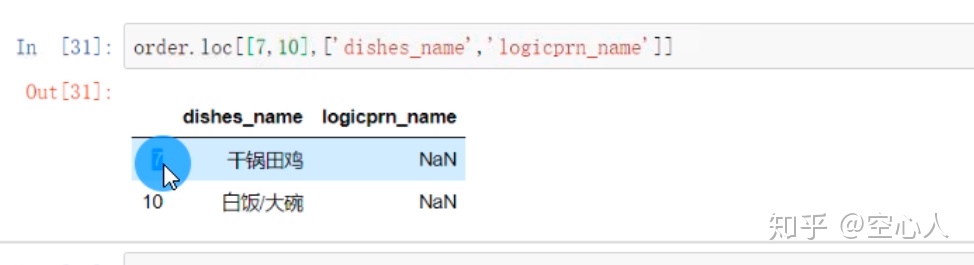
iloc[A,B] A,B分别代表列的位置和行的位置(如果是iloc[0:6]只写出了一个,那么它代表的是A,也就是说只取出前面的1-7行)
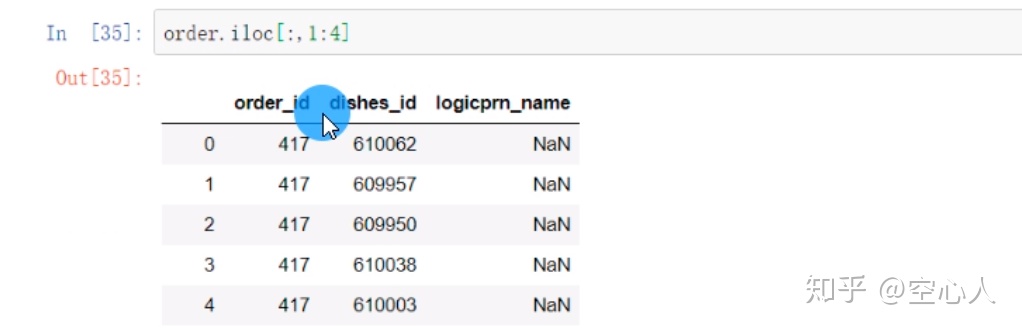
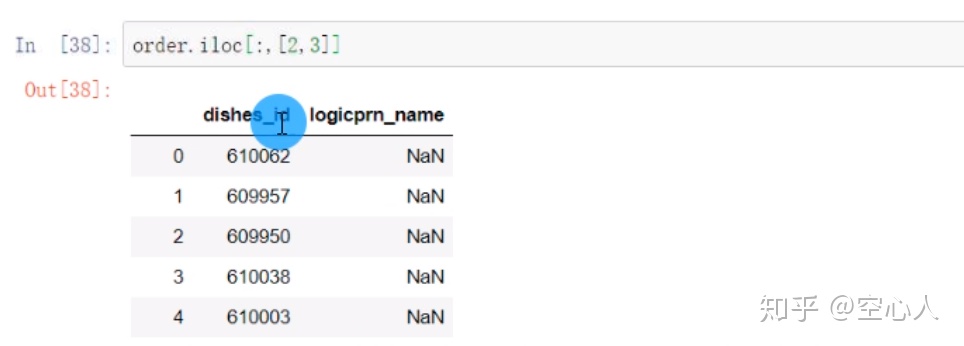

















 9560
9560

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









