




 本文详细介绍了数据仓库的架构,包括数据采集层、处理层、服务层和应用层,并重点阐述了数据仓库分层的原因和设计,特别是ODS层的作用。数据仓库建模部分探讨了关系建模、维度建模和Data Vault模型的优缺点,强调了数据仓库建模的目标和方法。
本文详细介绍了数据仓库的架构,包括数据采集层、处理层、服务层和应用层,并重点阐述了数据仓库分层的原因和设计,特别是ODS层的作用。数据仓库建模部分探讨了关系建模、维度建模和Data Vault模型的优缺点,强调了数据仓库建模的目标和方法。

作者介绍
@猫耳朵
数据产品经理萌新。
开发经验丰富,专注于数据产品。
—————— BEGIN ——————
本文主要围绕架构、分层、建模三个方面,进一步加深对数仓的了解。
1 数据仓库的架构
从整体上来看,数据仓库体系架构可分为:数据采集层、数据计算层、数据服务层和数据应用层,如下图。
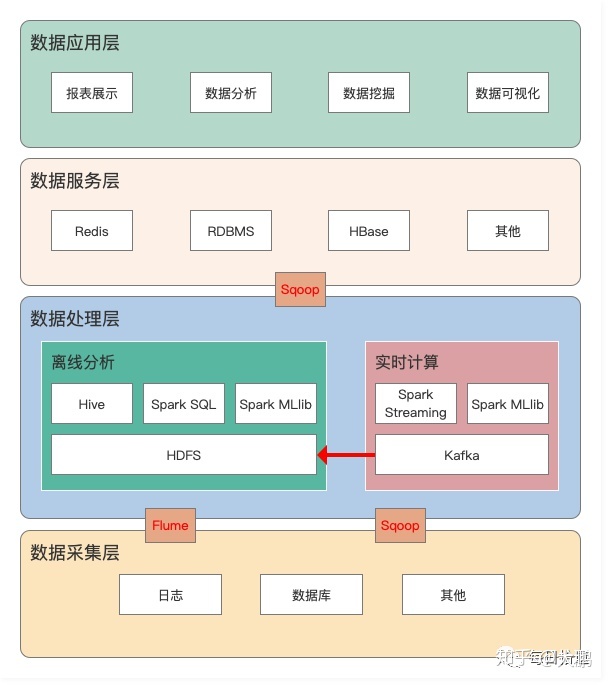
1)数据采集层
数据采集层的任务就是把数据从各种数据源中采集和存储到数据库上,期间有可能会做一些 ETL(即抽取、转换、装载)操作。
其中,日志所占份额最大,存储在备份服务器上的业务数据库中,如 Mysql 中的数据。其他数据的话,如 Excel 等需要手工录入的数据。
实时采集不是一条一条采集,而是根据一些限制条件,一般是数据大小限制(如 512KB 写一批)、时间阈值限制(如 30 秒写一批)。
采集的数据需要数据采集系统分发给下游,一般选取 Flume、Sqoop 等。
2)数据处理层
从数据采集系统出来的数据,分发给下游的数据处理平台,一般有 Hive、MapReduce、Spark Streaming、Storm 以及新兴的 Flink 等,阿里巴巴内部使用的是 StreamCompute。
3)数据服务层
数据服务层,通过接口服务化方式对外提供数据服务,以保证更好的性能和体验。针对不同的需求和数据应用场景,数据服务层的数据源架构在不同的数据库上,如 Mysql、HBase、MongoDB 等。实时的存储且需要支持高并发的话,就选择 HBase。
数据服务层可以使应用对底层数据存储透明,将海量数据方便高效地开放给各业务使用。
4)数据应用层
数据已经准备好,需要通过合适的应用提供给用户,让数据最大化地发挥价值。数据应用表现在各个方面,如报表展示、数据分析、数据挖掘、数据可视化等。
2 数据仓库分层
2.1 为啥要分层?
作为一名数据产品经理,笔者肯定希望自己的数据能够有秩序地流转,数据的整个生命周期能够清晰明确地被设计者和使用者感知到。但是,随着业务的发展,频繁迭代和跨部门的业务变得越来越多。这就容易导致数据仓库出现如下问题:
1)缺乏统一的业务和技术标准,如:开发规范、指标口径不统一。
2)缺乏统一数据质量监控,如:字段数据不完整和不准确等。
3)业务知识体系散乱,导致数据研发人员开发成本增加。
4)数据架构不合理,数据层之间分工不明显,数据流向混乱。
5)缺失统一维度和指标管理。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









