






 本文围绕HashMap线程不安全问题展开。先通过模拟场景对比HashMap和ConcurrentHashMap结果,分析JDK 1.8中HashMap在多线程下size变多、元素覆盖等问题,还提及扩容时的元素覆盖情况;又探讨JDK 1.7因头插法复制元素导致的死循环和数据丢失问题。
本文围绕HashMap线程不安全问题展开。先通过模拟场景对比HashMap和ConcurrentHashMap结果,分析JDK 1.8中HashMap在多线程下size变多、元素覆盖等问题,还提及扩容时的元素覆盖情况;又探讨JDK 1.7因头插法复制元素导致的死循环和数据丢失问题。
序
差不多两周没有更新了,感受到深深的罪恶,拖更可不是个好习惯,我一直觉得坏习惯一旦开始,就会有第二次,第三次....
特别是打开公众号后台,看到新增了一个粉丝,巨开心,感谢观众姥爷支持。
上周去重庆旅游了4天,又冷,又累,没事可以写写游记,哈哈哈,又可以水文章。
概述
可以先看前篇 HashMap源码分析
我们都知道HashMap线程不安全,源码的注释也写明,多线程访问必须加锁。
* Note that this implementation is not synchronized.
* If multiple threads access a hash map concurrently, and at least one of
* the threads modifies the map structurally, it must be
* synchronized externally.
模拟场景
那到底为什么呢?到底会出现什么不安全的情况呢,我们写个例子看看。
public class HashMapTest {
static Map map = new HashMap<>();public static void main(String[] args) throws Exception{int num = 5;// 控制线程同时起跑final CountDownLatch startDownLatch = new CountDownLatch(1);// 控制线程都跑完任务final CountDownLatch stopDownLatch = new CountDownLatch(num);
IntStream.range(0,num).forEach(i->{new Thread(()->{try {// 每个线程到这些先等着
startDownLatch.await();// 每个线程往map里添加10000个相同的keyfor (int j=0;j<10000;j++){
map.put("key"+j,j);
}
} catch (Exception e) {
e.printStackTrace();
}
System.out.println("第"+(i+1)+"个线程执行完成了,size="+map.size());
stopDownLatch.countDown();
}).start();
});
Thread.sleep(1000);// 让所有等待的线程同时执行
startDownLatch.countDown();// 当前线程等待,等待所有线程都执行完了才往下执行
stopDownLatch.await();
System.out.println("全部执行完成,size="+map.size());
}
}我们先把 HashMap换成 ConcurrentHashMap 看下正确的结果
static Map map = new ConcurrentHashMap<>();第3个线程执行完成了,size=10000
第1个线程执行完成了,size=10000
第5个线程执行完成了,size=10000
第2个线程执行完成了,size=10000
第4个线程执行完成了,size=10000
全部执行完成,size=10000
应该跟所有人的预料结果一模一样。想知道 ConcurrentHashMap的源码分析,可以阅读前篇 ConcurrentHashMap现在换成 HashMap 看看会出现什么情况
以下结果为JDK1.8环境:
第一种情况
第2个线程执行完成了,size=12081
第5个线程执行完成了,size=12081
第3个线程执行完成了,size=12081
第4个线程执行完成了,size=12081
第1个线程执行完成了,size=12081
全部执行完成,size=12081
第二种情况
java.lang.ClassCastException: java.util.HashMap$Node cannot be cast to java.util.HashMap$TreeNode
at java.util.HashMap$TreeNode.moveRootToFront(HashMap.java:1819)
at java.util.HashMap$TreeNode.treeify(HashMap.java:1936)
at java.util.HashMap$TreeNode.split(HashMap.java:2162)
at java.util.HashMap.resize(HashMap.java:713)
at java.util.HashMap.putVal(HashMap.java:662)
at java.util.HashMap.put(HashMap.java:611)
at com.cc.sf.hashMap.HashMapTest.lambda$null$0(HashMapTest.java:31)
at java.lang.Thread.run(Thread.java:745)
java.lang.ClassCastException: java.util.HashMap$Node cannot be cast to java.util.HashMap$TreeNode
at java.util.HashMap$TreeNode.moveRootToFront(HashMap.java:1819)
at java.util.HashMap$TreeNode.treeify(HashMap.java:1936)
at java.util.HashMap.treeifyBin(HashMap.java:771)
第2个线程执行完成了,size=2779
第5个线程执行完成了,size=9217
at java.util.HashMap.putVal(HashMap.java:643)
at java.util.HashMap.put(HashMap.java:611)
at com.cc.sf.hashMap.HashMapTest.lambda$null$0(HashMapTest.java:31)
at java.lang.Thread.run(Thread.java:745)
第4个线程执行完成了,size=16117
第1个线程执行完成了,size=16117
第3个线程执行完成了,size=16117
全部执行完成,size=16117
分析
1. size 变多了问题
我们的代码只执行了 put() 操作,看过前篇 HashMap源码分析,分析过源码,现在我们简单梳理下过程
看下源码 (JDK 1.8):
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {
Node[] tab; Node p; int n, i;// table为空 或者长度为0 先初始化if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;//将p赋值为对应桶位置的头结点//如果key对应的数组位置还是空着的 则直接new一个放进去if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);else {// e为要插入的node
Node e; K k;// 如果头结点的hash 和key的hash一样 且key也一样 则该节点即为要插入的节点if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;// 如果该链表还是个红黑树 则按照红黑树的插入方法else if (p instanceof TreeNode)
e = ((TreeNode)p).putTreeVal(this, tab, hash, key, value);// 正常链表else {// 死循环for (int binCount = 0; ; ++binCount) {// 是否为尾节点 是 则直接插入 并且退出循环if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);// 是否要转成红黑树if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);break;
}// 不是尾节点 则 比对hash 和 key是一样 是 退出循环 e已经在上面赋值if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))break;//p指向下一个节点
p = e;
}
}// 如果e不为空 则替换e的value 并返回旧值if (e != null) { // existing mapping for key
V oldValue = e.value;if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);return oldValue;
}
}
++modCount;// 是否触发扩容if (++size > threshold)
resize();
afterNodeInsertion(evict);return null;
}如果两个线程同时执行这个方法,且key都一样,则不管是哪种情况,都只会插入一个值,另外一个会被覆盖掉,但是最后的 ++size 都会执行到,所以虽然只插入了一个元素,但是却算多次插入。
有些读者可能会有疑问了,那实际元素到底是多没多呢?
答案是不确定。可能多了可能少了。
我们修改上面的例子 在最后加上打印出实际的元素总数:
AtomicInteger i= new AtomicInteger(0);
map.forEach((a,b)->i.incrementAndGet());
System.out.println("实际元素个数:"+i.get());
多次执行 搜集到如下两种情况
第2个线程执行完成了,size=14248
第3个线程执行完成了,size=14248
第1个线程执行完成了,size=14248
第4个线程执行完成了,size=14248
第5个线程执行完成了,size=14248
全部执行完成,size=14248
实际元素个数:9738
第1个线程执行完成了,size=12599
第4个线程执行完成了,size=13157
第5个线程执行完成了,size=16054
第2个线程执行完成了,size=16054
第3个线程执行完成了,size=16054
全部执行完成,size=16054
实际元素个数:13269
第一种比标准少了,第二种比标准多了。
真令人头大,怎么反复横跳呢?
不急,我们慢慢来,接着看扩容源码。
final Node[] resize() {
Node[] oldTab = table;int oldCap = (oldTab == null) ? 0 : oldTab.length;int oldThr = threshold;int newCap, newThr = 0;if (oldCap > 0) {// 扩容再大 也不能大过最大值if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;return oldTab;
}// 扩充为原来的2倍(左移 即为乘2)else if ((newCap = oldCap <1) = DEFAULT_INITIAL_CAPACITY)
newThr = oldThr <1; // double threshold
}// threshold>0说明调用了设置该值的构造方法else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;// 初始化else { // signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}// 计算新的resize上限if (newThr == 0) {float ft = (float)newCap * loadFactor;
newThr = (newCap float)MAXIMUM_CAPACITY ? (int)ft : Integer.MAX_VALUE);
}
threshold = newThr;@SuppressWarnings({"rawtypes","unchecked"})
Node[] newTab = (Node[])new Node[newCap];
table = newTab;if (oldTab != null) {// 每个数组里面的Node链表都重新分配// 不是带着原下标 就是待在(原下标+oldCap)的下标for (int j = 0; j Node e;if ((e = oldTab[j]) != null) {
oldTab[j] = null;// 如果只链接一个节点,重新计算并放入新数组if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;// 如果是红黑树 拆分处理else if (e instanceof TreeNode)
((TreeNode)e).split(this, newTab, j, oldCap);else {
Node loHead = null, loTail = null;
Node hiHead = null, hiTail = null;
Node next;do {
next = e.next;// e.hash & oldCap,若为0则索引位置不变,不为0则新索引=原索引+旧数组长度// 原索引if ((e.hash & oldCap) == 0) {if (loTail == null)
loHead = e;else
loTail.next = e;
loTail = e;
}// 原索引+oldCapelse {if (hiTail == null)
hiHead = e;else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);// 原索引放到bucket里if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}// 原索引+oldCap放到bucket里if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}return newTab;
}大概两步
- 新建一个现有2倍长度的数组
- 复制原数组里面的元素到新数组
比如第一个线程T1正在扩容,正在将原数组里的元素复制到新数组里面去,但是正好另一个线程T2插入一个key,T2当然直接插入到新数组里面去,里面的槽位大多数都是空的,因为T1才新创建,原数组的值T1还正在搬,会存在这种情况:T2判断了该key对应下标的table位置为null,正准备把这个值放进去的时候,T1先把原数组的值放进去,然后T2就把T1放进去的值覆盖了。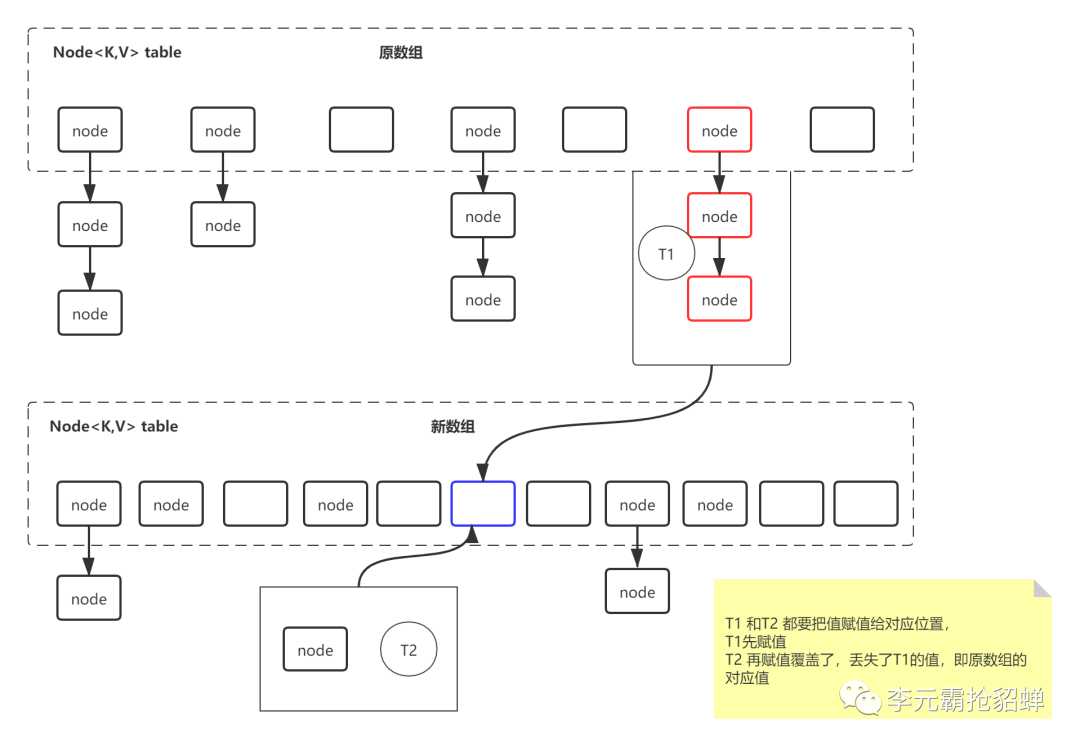
会变多的原因,应该跟红黑树有关,挖个坑,分享算法的时候补上。
报错的问题是因为已经转换成红黑树了,但是还是创建的链表节点。
头插法的死循环问题
应该都听说过JDK1.7 HashMap 因为链表拉链法使用头插法,会造成死循环问题。下面来一探究竟。上源码:
public V put(K key, V value)if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
if (key == null)
return putForNullKey(value);
int hash = hash(key);
int i = indexFor(hash, table.length);
for (Entry e = table[i]; e != null; e = e.next) { // 先遍历
Object k;if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i); // 再插入return null;
}void addEntry(int hash, K key, V value, int bucketIndex) {if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length); // 触发扩容
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
createEntry(hash, key, value, bucketIndex);
}void createEntry(int hash, K key, V value, int bucketIndex) {
Entry e = table[bucketIndex];// 头插法,链表头部指向新的键值对
table[bucketIndex] = new Entry<>(hash, key, value, e);
size++;
}其实根源不是put元素的时候使用的头插入,而是扩容的时候,复制元素的时候,使用头插法复制:
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
// 创建新数组
Entry[] newTable = new Entry[newCapacity];
// 将原数组的值 摞到新数组去
transfer(newTable, initHashSeedAsNeeded(newCapacity));
table = newTable;
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry e : table) {while(null != e) {
Entry next = e.next;if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}int i = indexFor(e.hash, newCapacity);// 将当前节点的 next 指向第一个节点
e.next = newTable[i];// 将当前节点设置为第一个节点
newTable[i] = e;
e = next;
}
}
}上面的代码应该都能看懂,核心就是后面加注释那那两句,遍历链表,复制到新数组使用的逆序插入,刷过算法题或者了解过的应该都知道,逆序打印一个链表。这样的操作在多线程环境下会造成死循环和数据丢失的问题。图解如下: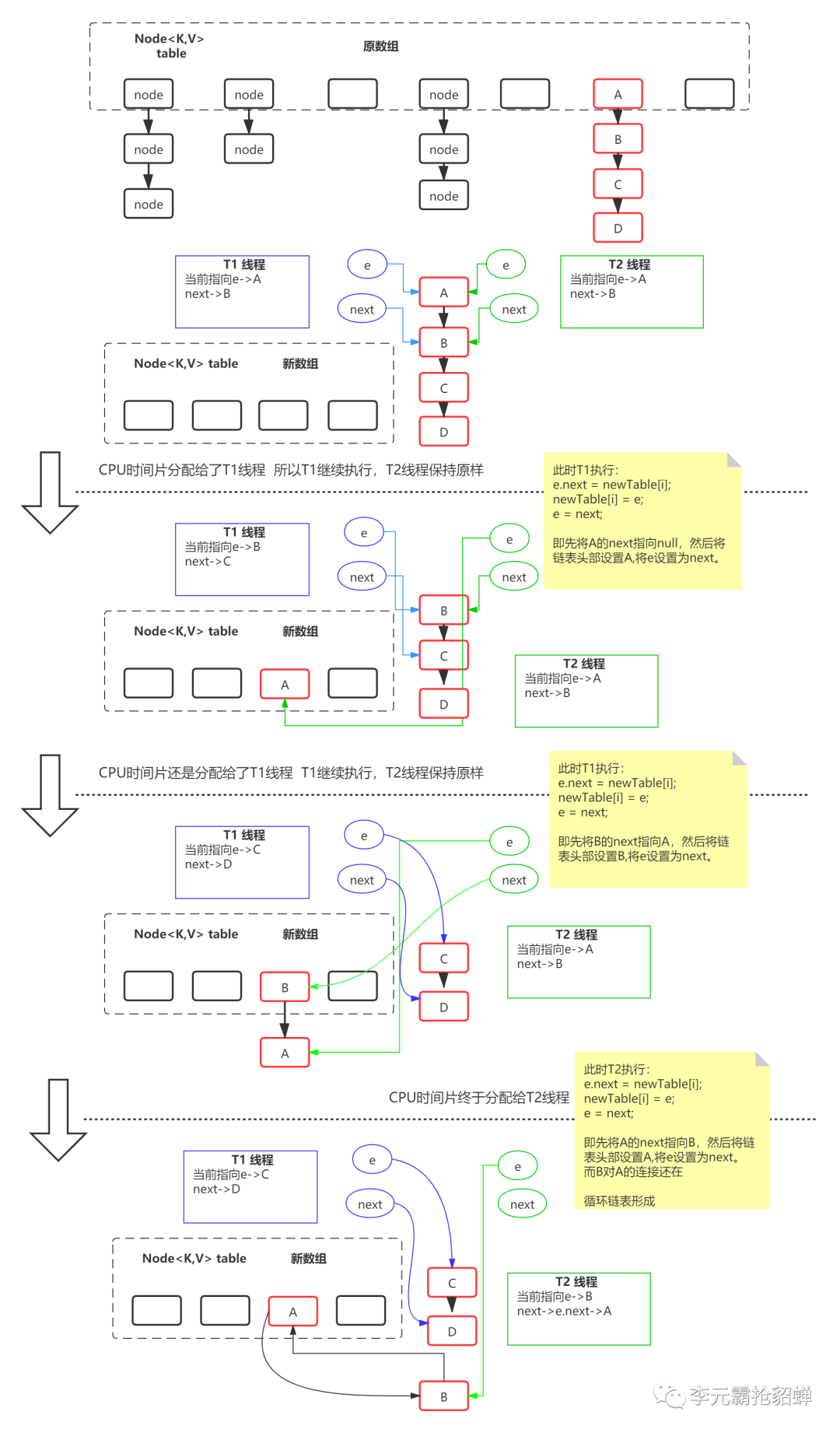 最后就形成循环链表,我们都知道遍历循环链表那就等同于死循环了。
最后就形成循环链表,我们都知道遍历循环链表那就等同于死循环了。
总结
JDK1.8 HashMap 多线程环境下会存在转换异常,丢失数据,重复数据的问题
JDK1.7 HashMap 死循环,丢失数据的问题
后记
看到这里,不知道小伙伴都理解了没有,如果还存在疑惑,请在评论区提出。这是我自己的理解,自己作图,如果存在错误,也请指出,不胜感激。
量变引发质变,经常进步一点点,期待蜕变的自己。

















 4822
4822

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









