



 本文探讨了数据压缩的基本概念,包括压缩对象、目的及分类。通过实例分析了不同文件类型的压缩效果,讨论了文本数据的冗余度,并计算了一阶熵以评估数据的不确定性。
本文探讨了数据压缩的基本概念,包括压缩对象、目的及分类。通过实例分析了不同文件类型的压缩效果,讨论了文本数据的冗余度,并计算了一阶熵以评估数据的不确定性。
1、教材习题 Page7
1-1数据压缩的一个基本问题是“我们要压缩什么”,对此你是怎样理解的?
数据压缩,就是指不丢失有用信息的前提下,以最少的数码表示信号源所发的信号,减少容纳给定消息集合或数据采样集合的信号空间。
所谓的信号空间就是我们压缩的对象,即: 1. 物理空间,如存储器和U盘等数据存储介质。 2. 时间空间,如传输给定消息集合所需的时间。3.频带空间,如传输给定消息所要求的宽带等。
1-2数据压缩的另一个基本问题是“为什么进行压缩”,对此你又是怎样理解的?
减少信息存储空间,提高其传输、存储和处理效率。经过数据压缩可以将一些占用内存比较大多媒体数据,压缩成可以缩小的文件内存,这样可以方便传递。使得人们对信息存储空间操作更加便捷。
1-6数据压缩是如何分类的?
按压缩的原理可以分为:预测编码、变换编码、量化和矢量量化编码、信息熵编码、子带编码、模型编码。
压缩还分为:可逆压缩、不可逆压缩。
2、参考书《数据压缩导论(第4版)》Page 8
1. 用你的计算机上的压缩工具来压缩不同文件。研究原文件的大小和类型对于压缩文件与原文件大小之比的影响。
一般字符文件的压缩比较高。可以达到50%左右。视频,音频,图像文件,压缩比一般80%左右。有的图像文件如.JPG格式的,本来就是带压缩的,再用rar等工具压缩的效果不明显。
2. 从一本通俗杂志中摘录几段文字,并删除所有不会影响理解的文字,实现压缩。例如,在"this is the dog that belong to my friend” 中,删除 is 、the、that和to之后,仍然能传递相同的意思。用被删除的单词数与原文本的总单词数之比来衡量文本中的冗余度。用一本技术期刊中的文字来重复这一实验。对于摘自不同来源的文字,我们能否就其冗余度做出定量论述?
冗余度,通俗的讲就是数据的重复度。在一个数据集合中重复的数据称为数据冗余。因为摘自不同来源的文字所介绍的内容的不同,文字出现的次数也一定不会相同,由于对文字的压缩,被删除的文字的数量也会不同,所有我们不能对摘自不同来源的文字做冗余度定量论述的。
三、参考书《数据压缩导论(第4版)》P30
3、给定符号集A={a1,a2,a3,a4},求以下条件下的一阶熵:
(a)P(a1)=P(a2)=P(a3)=P(a4)=1/4
(b)P(a1)=1/2 , P(a2)=1/4 , P(a3)=P(a4)=1/8
(c)P(a1)=0.505 , P(a2)=1/4 , P(a3)=1/8 , P(a4)=0.12
解:
(a) H=-1/4*4*log21/4
=- log21/4
=2
(b)H= -(1/2*log21/2+1/4*log21/4+1/8*log21/8+1/8*log21/8)
=-1/2*log21/2-1/4*log21/4-1/8*log21/8-1/8*log21/8)
=1/2+1/2+3/8+3/8=7/4
(c)H=-(0.505*log20.505+1/4*log21/4+1/8*log21/8+0.12*log20.12)
=-0.505*log20.505-1/4*log21/4-1/8*log21/8-0.12*log20.12
=-0.505*log20.505+1/2+3/8-0.12*log20.12=1.8672
4、考虑以下序列:
ATGCTTAACGTGCTTAACCTGAAGCTTCCGCTGAAGAACCTG
CTGAACCCGCTTAAGCTTAAGCTGAACCTTCTGAACCTGCTT
(a)根据此序列估计个概率值,并计算这一序列的一阶、二阶、
三阶和四阶熵。
(a)总的有84个字母,由计数,得
P(A)=21/84=1/4,P(C)=24/84=2/7,P(G)=16/84=4/21,P(T)=23/84
H=-(1/4*log21/4+2/7*log22/7+4/21*log24/21+23/84*log223/84)
=-1/4*log21/4-2/7*log22/7-4/21*log24/21-23/84*log223/84
=2
7、做一个实验,看看一个模型能够多么准确地描述一个信源。
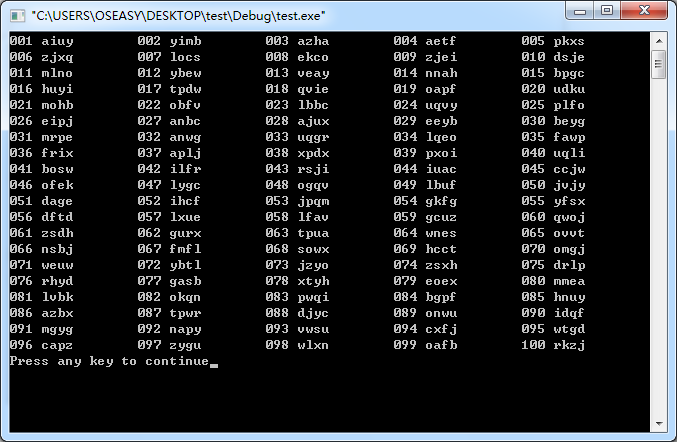
(a)编写一段程序,从包括26个字母的符号集{a,b,...,z}中随机选择字母,组成100个四字母单词,这些单词中有多少是有意义的?
执行结果:

















 4533
4533

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









