






 本文深入探讨了机器学习中的分类问题,重点讲解逻辑回归的概念、假设函数、判定边界及代价函数等内容,旨在帮助读者理解二元及多元分类的基本原理。
本文深入探讨了机器学习中的分类问题,重点讲解逻辑回归的概念、假设函数、判定边界及代价函数等内容,旨在帮助读者理解二元及多元分类的基本原理。
上一篇 ※※※※※※※※ 【回到目录】 ※※※※※※※※ 下一篇
7.1 分类问题
本节内容:什么是分类
之前的章节介绍的都是回归问题,接下来是分类问题。所谓的分类问题是指输出变量为有限个离散值,比如正确或错误、0或1、是或否等等。我们将首先从二元分类问题开始讨论,可将分类总结成 y ∈ { 0 , 1 },,其中 0 表示负向类,1 表示正向类。
Logistic回归与线性回归有一个主要的区别,在线性回归中,ℎ?(?)的值可以小于0,也可以大于1;而在Logistic回归中,ℎ?(?)的值在 0 - 1 的范围内。所以这个算法的性质是:它的输出值永远在0 - 1 之间。
注意:Logistic回归是一种分类算法。虽然它也被称为回归,但实际上是分类算法,适用于输出变量y取离散值的情况。
7.2 假设函数
本节内容:逻辑回归的假设函数ℎ?(?)是什么。
在上节中我们介绍了,分类器的输出值在 0 和1 之间。因此,我们希望找出一个满足该性质的假设函数,即预测值要在 0 和1 之间。我们可以将 ℎ?(?) 视为某种情况的概率,如正确或者错误的概率:
当ℎ?(?) >= 0.5时,预测 ? = 1。 比如一件事情为正确的概率大于0.5,那么我们就认为它是正确的(取1);
当ℎ?(?) < 0.5时,预测 ? = 0。 比如一件事情为正确的概率大于0.5,那么我们就认为它是错误的(取0)。
引入新的模型:逻辑回归,该模型的输出变量范围始终在 0 和 1 之间。逻辑回归的假设函数的模型是: ℎ?(?) = ?(???) ,其中: ? 代表特征向量 ,? 代表S形函数(sigmoid函数),公式:\[g(z) = \frac{1}{{1 + {e^{ - z}}}}\]
因此:\[{{\rm{h}}_\theta }(x) = \frac{1}{{1 + {e^{ - {\theta ^T}x}}}}\]
S形函数的图像为:
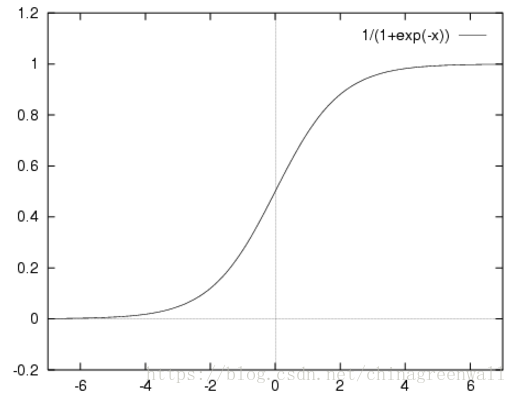
如上文中所谈,ℎ?(?)的作用是:对于给定的输入变量,根据选择的参数计算输出变量=1 的可能性,即ℎ?(?) = ?(? = 1|?;?) 。例如,对于给定的 x ,通过已经确定的参数计算得出:ℎ?(?) = 0.7,则表示有70%的几率 y 为正向类,相应地 y 为负向类的几率为1 - 0.7 = 0.3。
7.3 判定边界
对于线性可分的分类情况,可以用简单的线性模型进行分类。如下图所示:
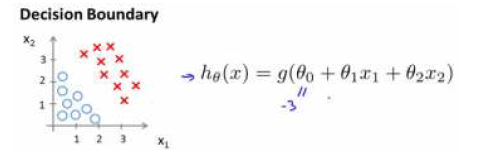
对于复杂的分析情况,可能需要加入二次方特征,使得 ℎ?(?) = ?(?0 + ?1?1 + ?2?2 + ?3?12 + ?4?22)。如下图所示:
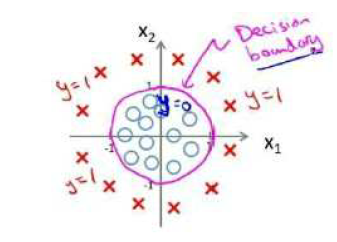
由此可见,判定边界并不是训练集的属性,而是假设函数本身及其参数的属性。只要给定了参数向量 ? ,就可以得到判定边界。我们可以用非常复杂的模型来适应非常复杂形状的判定边界。
7.4 代价函数
对于线性回归模型,我们定义的代价函数是所有模型误差的平方和。理论上来说,我们也可以对逻辑回归模型沿用这个定义,但是问题在于,当我们  带入到这样定义了的代价函数中时,我们得到的代价函数将是一个非凸函数。
带入到这样定义了的代价函数中时,我们得到的代价函数将是一个非凸函数。
 非凸函数中局部最优解太多,可能会导致无法收敛到全局最小值。引出需要找到一个非凸的代价函数。
非凸函数中局部最优解太多,可能会导致无法收敛到全局最小值。引出需要找到一个非凸的代价函数。
需要重新定义代价函数为: ,其中
,其中

第一种情况:y = 1 时,ℎ?(?)与 ????(ℎ?(?), ?)之间的关系图:

(1) 当实际的y = 1,且ℎ?(?) = 1 时: cost = - log( ℎ?(?) ) = 0。就是说ℎ?(?)与实际情况y一致时,代价函数为0
(2) 当实际的y = 1,且ℎ?(?) ≠ 1 时: 随着ℎ?(?)的减小,cost = - log( ℎ?(?) ) 逐渐增大。也就是说ℎ?(?)与实际情况 y 之间相差越大,代价函数的值也就越大。
第二种情况:y = 0 时,ℎ?(?)与 ????(ℎ?(?), ?)之间的关系图:

(1) 当实际的y = 0,且ℎ?(?) = 0 时: cost = - log( ℎ?(?) ) = 0。就是说ℎ?(?)与实际情况y一致时,代价函数为0
(2) 当实际的y = 0,且ℎ?(?) ≠ 0 时: 随着ℎ?(?)的增加,cost = - log( 1 - ℎ?(?) ) 逐渐增大。也就是说ℎ?(?)与实际情况 y 之间相差越大,代价函数的值也就越大。
7.5 简化代价函数与梯度下降
我们将构建的 ????(ℎ?(?), ?) 简化如下:
????(ℎ?(?), ?) = −? × ???(ℎ?(?)) − (1 − ?) × ???(1 − ℎ?(?))
代入代价函数中得到:
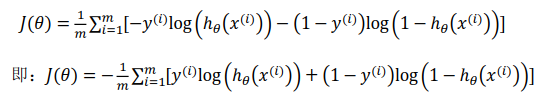
在得到这样一个代价函数以后,我们便可以用梯度下降算法来求得能使代价函数最小的参数了。

对 J(?) 的求导,熟悉高等数学的可以推导一下。我的推导用铅笔写的很潦草,这里附上黄广海博士的推导过程:

ps:如果看起来比较蒙的话,可以不把ℎ?(?)分解开,将其视为一个整体来推导,其中ℎ?(?)的导数 = ℎ?(?) *(1 - ℎ?(?))
现在,如果你把这个更新规则和我们之前用在线性回归上的进行比较的话,你会惊讶地发现,这个式子正是我们用来做线性回归梯度下降的。
但是对于线性回归:假设函数为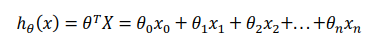 对于逻辑回归:假设函数为
对于逻辑回归:假设函数为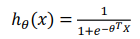
因此,即使更新参数的规则看起来基本相同,但由于假设的定义发生了变化,所以逻辑函数的梯度下降,跟线性回归的梯度下降实际上是两个完全不同的东西。
7.6 高级优化
我们在最小化代价函数中应用到了梯度下降的方法,实际上除了梯度下降法,还有很多优秀的算法来计算代价函数?(?)和其偏导数,从而最小化代价函数。其他优化代价函数的方法有:共轭梯度法 BFGS (变尺度法) 和 L-BFGS (限制变尺度)等。关于这些优化算法的细节,可以参考该文章:【优化算法】MATLAB/Octave或者其他的一些编程语言中,并不需要自己实现这些高级算法,一般都可以找到实现这些算法的库,调用这些库就好啦,除非你是吴恩达所提的专门研究数值计算的人 =_=
7.7 多类别分类:一对多
在之前的内容中主要讲的是二元分类,即 y ∈ { 0 , 1 }。在二元分类中,我们的数据看起来可能是像这样:
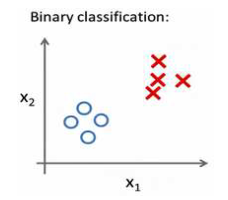
但是在多元分类问题是,数据看起来是这样的:
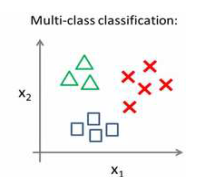
在前文中,我们已经学习了如何利用逻辑回归进行二元分类,而在多元分类中,我们利用的依旧是二元分类的思想:即将其中一类视为1,其他的全部归类于0,这个模型记作ℎ?(1)(?);接着,类似地第我们选择另一个类标记为正向类(? = 2),再将其它类都标记为负向类,将这个模型记作 ℎ?(2)(?),依此类推。
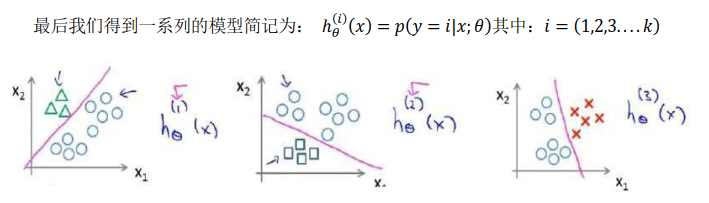
我们利用 k 个ℎ?(?),每个ℎ?(?)都代表着某一种类别。比如ℎ?(i)(?)代表第 i 种类别,然后在这 k 个ℎ?(?)中找到那个使得ℎ?(?)最大的 i ,无论 i 值是多少,我们都有最高的概率值,我们预测?就是那个值。
如果这篇文章帮助到了你,或者你有任何问题,欢迎扫码关注微信公众号:一刻AI 在后台留言即可,让我们一起学习一起进步!

以上,就是吴恩达机器学习课程第七章的主要内容。

















 1128
1128

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









