



 本文深入浅出地介绍了机器学习中的核心概念:线性回归与梯度下降。通过预测住房价格的实际案例,阐述了如何构建单变量线性回归模型,并运用梯度下降算法来优化模型参数,以最小化预测误差。
本文深入浅出地介绍了机器学习中的核心概念:线性回归与梯度下降。通过预测住房价格的实际案例,阐述了如何构建单变量线性回归模型,并运用梯度下降算法来优化模型参数,以最小化预测误差。
上一篇 ※※※※※※※※ 【回到目录】 ※※※※※※※※ 下一篇
2.1 模型描述
让我们以预测住房价格的例子开始:首先要使用一个数据集,数据集包含不同房屋尺寸所售出的价格,根据数据集画出我的图表。比方说,如果你朋友的房子是 1250 平方尺大小,你要告诉他们这房子能卖多少钱。那么,你可以做的一件事就是构建一个模型,也许是条直线,从这个数据模型上来看,也许你可以告诉你的朋友,他能以大约220000(美元)左右的价格卖掉这个房子。这就是监督学习算法的一个例子。
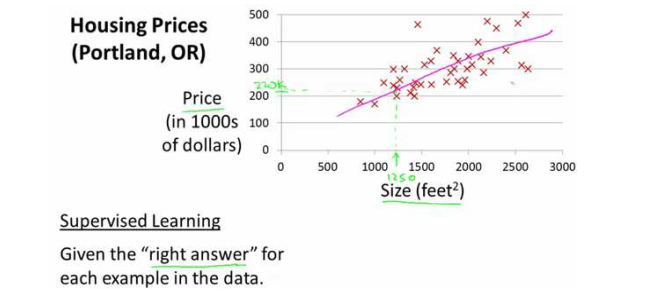
总结来说,需要做的就是利用数据集中的数据,找出可以描述该数据集中输入和输出的关系的数学模型。在程序中我们要首先设定这么一个函数h(假设函数)。
我们将要用来描述这个回归问题的标记如下:
? ——代表训练集中实例的数量
? ——代表特征/输入变量
? ——代表目标变量/输出变量
(?, ?) —— 代表训练集中的实例
(?(?), ?(?)) ——代表第? 个观察实例
h ——代表学习算法的解决方案或假设函数(hypothesis)
对于只有一个输入的问题,我们可以将h表达为:ℎ?(?) = ?0 + ?1?。只含有一个特征/输入变量的问题叫做单变量线性回归问题。
2.2 代价函数
由上节可知,问题的核心在于找到一种可以描述数据集中输入和输出的关系的数学模型,即求解假设函数ℎ?(?) = ?0 + ?1?。求解假设函数要做的就是为该函数选择合适的参数(parameters)?0 和 ?1。我们选择的参数决定了我们得到的直线相对于我们的训练集的准确程度,模型所预测的值与训练集中实际值之间的差距(下图中蓝线所指)就是建模误差(modeling error)。
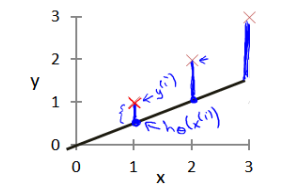
我们的目标便是选择出可以使得建模误差的平方和能够最小的模型参数。 即使得代价函数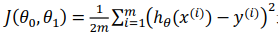 最小。找到了最小的代价函数,就找到了最能准确表达输入和输出之间关系的数学模型。
最小。找到了最小的代价函数,就找到了最能准确表达输入和输出之间关系的数学模型。
对于代价函数J,我们可以绘制出选择不同的参数?0 和 ?1时,J的等高线图。从图中可以看出,在三维空间中存在一个使得?(?0, ?1)最小的点。
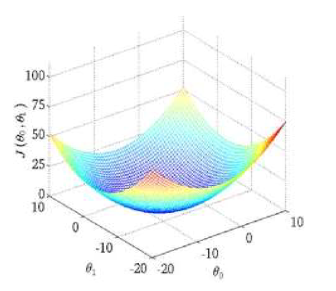
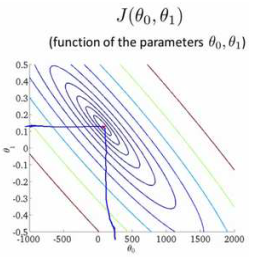
但是,绘出图形然后人工的方法来读出这些点的数值,找到最小的J,显然是个很麻烦的办法。因此需要找到一种算法,可以自动找到能使代价函数J最小化的参数?0和?1的值。梯度下降算法就是一种较好的选择。
2.3 梯度下降
梯度下降的思想:
- start with some parameters:?0, ?1, . . . , ??;
- keep changing parameters(?0, ?1, . . . , ?n)to reduce J(?0, ?1, . . . , ?n);
- get a local minimum(局部最小值)
批量梯度下降(batch gradient descent)算法的公式为:
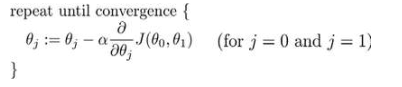
其中?是学习率(learning rate),它决定了我们沿着能让代价函数下降程度最大的方向向下迈出的步子有多大。
值得注意的是:parameters:?0, ?1, . . . , ??要同时更新。
2.4 梯度下降的直观理解
梯度下降的算法如下:
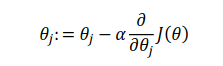
描述:对?赋值,使得?(?)按梯度下降最快方向进行,一直迭代下去,最终得到局部最小值。其中?是学习率(learning rate),它决定了我们沿着能让代价函数下降程度最大的方向向下迈出的步子有多大。
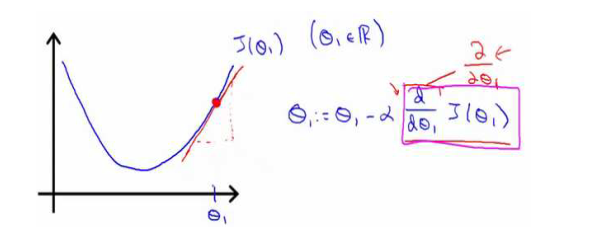
通过上图对梯度下降的过程进行理解:①如果函数处于下降趋势,则代价函数J的偏导数为负数,减去一个负数等于加上一个正数,那么?的值就会变大,随着?的变大,代价函数J逐渐减小,达到了降低J的目的;
②如果函数处于上升趋势,则代价函数J的偏导数为正数,减去一个正数,那么?的值就会变小,随着?的变小,代价函数J逐渐减小,同样也达到了降低J的目的。
再来看看学习率?:①若?太小,那么数据的挪动非常细致,同样也非常慢,需要很多步才能到达最低点。②如果?太大,那么梯度下降法可能会越过最低点,甚至可能无法收敛,甚至发散。
2.5 梯度下降的线性回归
将梯度下降应用在线性回归中,具体的程序实现为:

%单变量线性回归中的梯度下降 for iter = 1:num_iters theta = theta-alpha*(1/m)*X'*((theta'*X')'-y); %求解参数? J_history(iter) = computeCost(X, y, theta); %计算代价函数J end
以上,就是吴恩达机器学习课程第二章的主要内容。
如果这篇文章帮助到了你,或者你有任何问题,欢迎扫码关注微信公众号:一刻AI 在后台留言即可,让我们一起学习一起进步!


















 1128
1128

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









