






 本文介绍了如何使用Python中的urllib2模块模拟不同类型的浏览器进行网络请求。通过修改请求头中的User-Agent字段,可以实现对特定网站的身份模拟,绕过一些基本的防爬措施。
本文介绍了如何使用Python中的urllib2模块模拟不同类型的浏览器进行网络请求。通过修改请求头中的User-Agent字段,可以实现对特定网站的身份模拟,绕过一些基本的防爬措施。
python网络访问的标准模块
urllib与urllib2并不是升级版的关系,具体可见谷歌文章:difference between urllib and urllib2
urllib2的官方文档:https://docs.python.org/2.7/library/urllib2.html#module-urllib2
最简单的应用:
urllib2.urlopen(url,data,timeout)
data:以post提交url时用的
urllib2.Request(url, data=None, headers={},origin_req_host=None, unverifiable=False)
headers:发给服务器的身份证号,默认情况下urllib2的身份证号为自己的版本号Python-urllib/x.y。
网站通过浏览器发送过来的User-Agent的值来确认浏览器身份,因此用urllib2创建一个请求对象,并给它一个包含头数据的字典来欺骗网站。
#!/usr/bin/env python
# _*_ coding: utf-8 _*_
# __author__ ='kong'
import urllib2
import userAgents
class Urllib2ModifyHeader(object):
def __init__(self):
PIUA = {"User-Agent":"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0)"}
MUUA = {"User-Agent":"NOKIA5700/ UCWEB7.0.2.37/28/999"}
self.url = "http://fanyi.youdao.com"
self.useUserAgent(PIUA,1)
self.useUserAgent(MUUA,2)
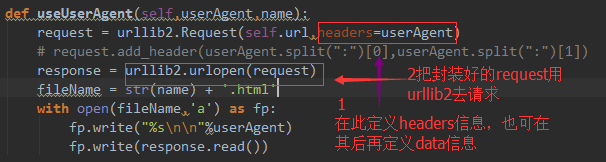
def useUserAgent(self,userAgent,name):
request = urllib2.Request(self.url,headers=userAgent)
# request.add_header(userAgent.split(":")[0],userAgent.split(":")[1])
response = urllib2.urlopen(request)
fileName = str(name) + '.html'
with open(fileName,'a') as fp:
fp.write("%s\n\n"%userAgent)
fp.write(response.read())
if __name__ == '__main__':
umh = Urllib2ModifyHeader()
解释:

















 3531
3531

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









