



 解析了软件工程课程中的一次结对编程作业,包括WordCount基本需求实现和进阶需求,利用Jsoup爬取CVPR2018论文信息,以及团队协作的心得体会。
解析了软件工程课程中的一次结对编程作业,包括WordCount基本需求实现和进阶需求,利用Jsoup爬取CVPR2018论文信息,以及团队协作的心得体会。
格式描述
==========
课程名称:软件工程1916|W(福州大学)
作业要求:结对第二次—文献摘要热词统计及进阶需求
结对学号:221600408_蔡鸿键 | 221600409_蔡森林
作业目标:
一、基本需求:实现一个能够对文本文件中的单词的词频进行统计的控制台程序。
二、进阶需求:在基本需求实现的基础上,编码实现顶会热词统计器。
作业格式描述:该博客首段
作业完成工具: IDEA & github
博客编辑器: MARKDOWN
PSP:正文
- github: WordCount基础篇
github: WordCount进阶篇
作业目录
==========
1.WordCount基本需求
2.思路分析
3.关键代码
4.测试图片
5.困难与解决
6.心得与总结
7.psp与花絮
作业正文
==========
2.WordCount基本需求
(一)WordCount基本需求
实现一个命令行程序,不妨称之为wordCount。
统计文件的字符数:
只需要统计Ascii码,汉字不需考虑
空格,水平制表符,换行符,均算字符
统计文件的单词总数,单词:至少以4个英文字母开头,跟上字母数字符号,单词以分隔符分割,不区分大小写。
英文字母: A-Z,a-z
字母数字符号:A-Z, a-z,0-9
分割符:空格,非字母数字符号
例:file123是一个单词,123file不是一个单词。file,File和FILE是同一个单词
统计文件的有效行数:任何包含非空白字符的行,都需要统计。
统计文件中各单词的出现次数,最终只输出频率最高的10个。频率相同的单词,优先输出字典序靠前的单词。
按照字典序输出到文件result.txt:例如,windows95,windows98和windows2000同时出现时,则先输出windows2000
输出的单词统一为小写格式
输出的格式为
characters: number
words: number
lines: number
: number
: number
...
(二)WordCount进阶需求
新增功能,并在命令行程序中支持下述命令行参数。说明:字符总数统计、单词总数统计、有效行统计要求与个人项目相同
- 使用工具爬取论文信息
从CVPR2018官网爬取今年的论文列表,输出到result.txt(一定叫这个名字),内容包含论文题目、摘要,格式如下:
为爬取的论文从0开始编号,编号单独一行
两篇论文间以2个空行分隔
在每行开头插入“Title: ”、“Abstract: ”(英文冒号,后有一个空格)说明接下来的内容是论文题目,或者论文摘要
后续所有字符、单词、有效行、词频统计中,论文编号及其紧跟着的换行符、分隔论文的两个换行符、“Title: ”、“Abstract: ”(英文冒号,后有一个空格)均不纳入考虑范围
- 附加题(20')
本部分不参与自动化测试,如有完成,需在博客中详细描述,并在博客中附件(.exe及.txt)为证。附加功能的加入不能影响上述基础功能的测试,分数取决于创意和所展示的完成度,创意没有天花板,这里不提出任何限制,尽你们所能去完成。
1 . 解题思路
总体:我们先抓住需求中的统计函数的关键点,再思考分析一些边缘条件,给出规定,优化函数。
具体:1.WordCount基本需求:从文本文件中逐个读取所有字符,然后将其保存为字符串,接着通过正则表达式匹配单词,保存于TreeMap中,统计并排序,最后将统计结果输出到文件中。
2.WordCount进阶需求:通过Jsoup工具将CVPR2018官网的论文列表爬取下来,保存在result文本文件中,同样也是进行逐个字符读取统计,保存字符串进行相应的统计和排序,最后输出结果。
2 . 设计过程
- 代码结构
WordCount的基本需求
- 类图
- 活动图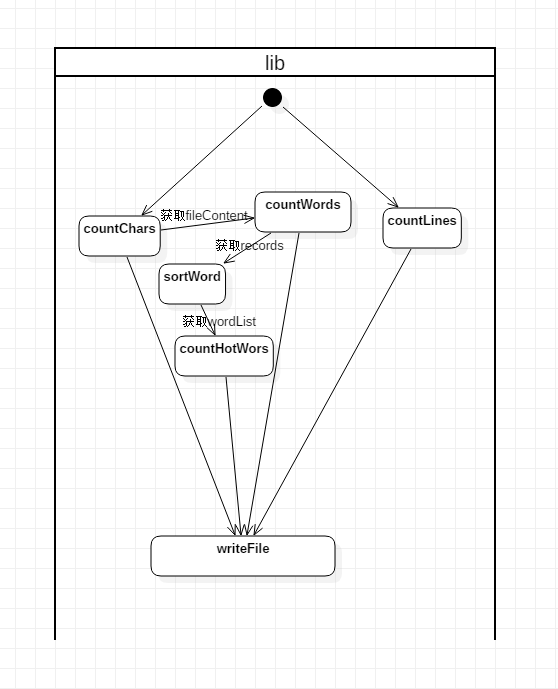
WordCount的进阶需求
- 类图
- 活动图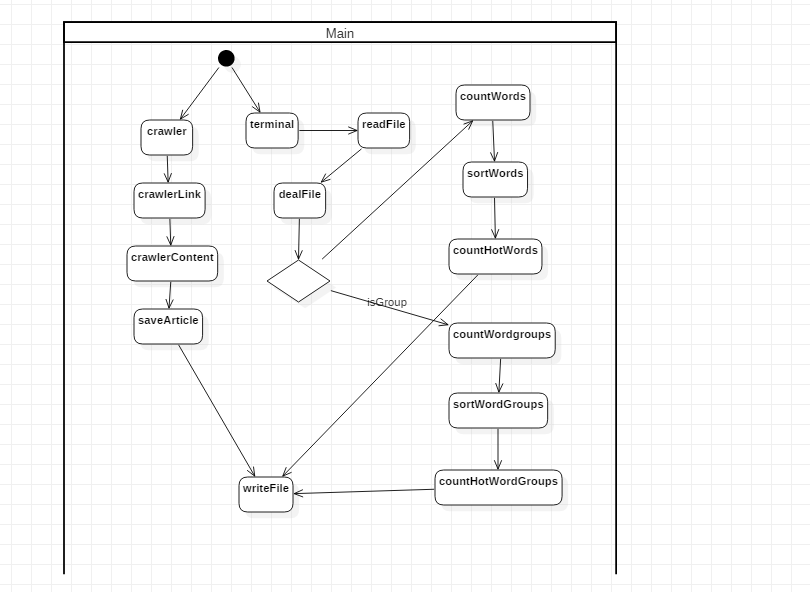
- 阶段一
- 共同讨论WordCount的基本功能需求
- 代码基本实现WordCount的基本需求
- 将项目各个功能分离成独立函数并进行相应的测试调整
- 对代码进行相应的测试和调整优化
- 阶段二
- 共同讨论WordCount的进阶功能需求
- 实现CVPR2018官网的论文爬取整理
- 代码基本实现WordCount的进阶需求
- 对代码进行相应的测试和调整优化
- 阶段三
- 将项目按照作业格式上传github
- 撰写博客
3 . 关键代码
WordCount基本需求
- 统计文件的字符数
//统计字符数 public static void countChars()throws Exception{ countChars = 0; File file = new File(path); BufferedReader br = new BufferedReader(new FileReader(file)); StringBuffer sbf = new StringBuffer(); int val; while((val=br.read())!=-1){ if((0<=val && val<=9)){ countChars++; }else if(val == 10){ continue; }else if(11<=val && val<=127){ countChars++; } sbf.append((char)val); } br.close(); fileContent = sbf.toString().toLowerCase(); }- 统计文件的有效行数
//统计有效行数 public static void countLines()throws Exception{ countLines = 0; String regex = "\\s*"; File file = new File(path); BufferedReader br = new BufferedReader(new FileReader(file)); String line; while((line=br.readLine())!=null){ if(!line.matches(regex)){ countLines++; } } br.close(); }- 统计文件的单词个数
//统计单词数 public static void countWords(){ countWords = 0; Pattern expression = Pattern.compile("[a-z]{4,}[a-z0-9]*"); String str = fileContent; Matcher matcher = expression.matcher(str); String word; while (matcher.find()) { word = matcher.group(); countWords++; if (records.containsKey(word)) { records.put(word, records.get(word) + 1); } else { records.put(word, 1); } } }- 统计文件的热词个数
//统计热门单词个数 public static void countHotWords(){ sortWord(); String str; int length = wordList.size(); if(length > 10){ for(int i = 0; i < 10; i++){ str = wordList.get(i); hotWordList.add(str); } } else{ hotWordList.addAll(wordList); } }- 热门单词排序
//对统计完的单词进行排序 public static void sortWord(){ List<Map.Entry<String, Integer>> list = new ArrayList<>(records.entrySet()); Collections.sort(list, new Comparator<Map.Entry<String, Integer>>() { @Override public int compare(Map.Entry<String, Integer> o1, Map.Entry<String, Integer> o2) { return o2.getValue().compareTo(o1.getValue()); } }); String str; for (Map.Entry<String, Integer> e: list) { str = "<"+e.getKey()+">: "+e.getValue(); wordList.add(str); } }WordCount进阶需求
- 线程爬取CVPR2018官网
//线程爬取官网链接 public static void crawler(){ try{ String url = "http://openaccess.thecvf.com/CVPR2018.py"; crawlerLink(url); new Thread(new Runnable() { @Override public void run() { while(!links.isEmpty()){ String link = links.getFirst(); links.removeFirst(); crawlerContent(link); try { Thread.sleep(1000); } catch (InterruptedException e) { e.printStackTrace(); } } } }).start(); }catch (Exception e){ e.printStackTrace(); } }- 爬取CVPR2018官网所有文章链接
//爬取所有文章链接 public static void crawlerLink(String url){ try{ Document doc = Jsoup.connect(url).get(); Element content = doc.getElementById("content"); Elements ptitles = content.getElementsByClass("ptitle"); for(Element item : ptitles){ Element link = item.selectFirst("a"); String href = "http://openaccess.thecvf.com/"+link.attr("href"); links.add(href); } }catch (Exception e){ e.printStackTrace(); } }- 获取CVPR2018所有文章的标题和摘要
//获取所有文章的标题和摘要 public static void crawlerContent(String url){ try{ StringBuilder results = new StringBuilder(); Document doc = Jsoup.connect(url).get(); Element content = doc.getElementById("content"); results.append(index+"\r\n"); String title = content.getElementById("papertitle").text(); results.append("title: "+title+"\r\n"); String abstractText = content.getElementById("abstract").text(); results.append("abstract: "+abstractText+"\r\n"+"\r\n"+"\r\n"); saveArticle(results); index++; }catch (Exception e){ e.printStackTrace(); } }- 将CVPR2018官网爬取的内容保存到result文本
//将爬取的内容保存到result文本 public static void saveArticle(StringBuilder content)throws Exception{ File file = new File(path+"result.txt"); if(!file.exists()){ file.createNewFile(); } FileWriter fw = new FileWriter(file,true); BufferedWriter bw = new BufferedWriter(fw); bw.write(content.toString()); bw.flush(); bw.close(); }- 接收命令行参数
if(args.length == 0){ throw new IllegalArgumentException(); } for (int i = 0; i < args.length; i++) { if(args[i].equals("-i")){ orders.put("-i",args[i+1]); i++; }else if(args[i].equals("-o")){ orders.put("-o",args[i+1]); i++; }else if(args[i].equals("-w")){ orders.put("-w",args[i+1]); i++; }else if(args[i].equals("-m")){ orders.put("-m",args[i+1]); i++; }else if(args[i].equals("-n")){ orders.put("-n",args[i+1]); i++; } }- 命令行输入的参数赋值
//命令行参数赋值 public static void terminal(){ inputPath = path + orders.get("-i"); outputPath = path + orders.get("-o"); w = Integer.valueOf(orders.get("-w")); if(orders.containsKey("-m")){ m = Integer.valueOf(orders.get("-m")); isGroup = true; } if(orders.containsKey("-n")){ n = Integer.valueOf(orders.get("-n")); }else{ n = 10; } }- 统计字符数和有效行数(countChars = countAllChars - countNums)
//读取输入文件所有字符内容 public static void readFile()throws Exception{ File file = new File(inputPath); BufferedReader br = new BufferedReader(new FileReader(file)); int val; while((val=br.read())!=-1){//统计所有字符数 if((0<=val && val<=9)){ countAllChars++; }else if(val == 10){ continue; }else if(11<=val && val<=127){ countAllChars++; } } br.close(); } //获取文章标题,摘要字符内容及有效行数 public static void dealFile()throws Exception{ String regex = "\\d+"; File file = new File(inputPath); if(!file.exists()){ file.createNewFile(); } BufferedReader br = new BufferedReader(new FileReader(file)); String line,title,abstractText; while((line=br.readLine())!=null){ if(line.matches(regex)){ countNums += line.length() + 1;//统计论文编号所在行字符数 } else if(line.startsWith("title: ")){ countLines++;//统计有效行数 countNums += 7;//统计title: 字符数 title = line.substring(6).toLowerCase(); if(w == 0){ countWords(title,1); }else if(w == 1){ countWords(title,10); } if(isGroup){ if(w == 0){ countWordGroups(title,1); }else if(w == 1){ countWordGroups(title,10); } } }else if(line.startsWith("abstract: ")){ countLines++;//统计有效行数 countNums += 10;//统计abstract: 字符数 abstractText = line.substring(9).toLowerCase(); countWords(abstractText,1); if(isGroup){ countWordGroups(abstractText,1); } } } br.close(); countHotWords(); if(isGroup){ countHotWordGroups(); } }- 统计单词权重词频
//统计单词 public static void countWords(String content, int weight){//weight权重的词频统计 Pattern expression = Pattern.compile("[a-z]{4,}[a-z0-9]*");//匹配单词 String str = content; Matcher matcher = expression.matcher(str); String word; while (matcher.find()) { word = matcher.group(); countWords++; if (records.containsKey(word)) { records.put(word, records.get(word) + weight); } else { records.put(word, weight); } } }- 统计词组权重词频(拟字符串匹配算法)
//统计单词词组 public static void countWordGroups(String content, int weight){//词组权重词频统计 StringBuffer sbf = new StringBuffer(); int size = content.length(); char []arr = content.toCharArray(); for (int i = 0; i < size; i++) {//去除分隔符整合所有字符 char val = arr[i]; if(48<=val && val<=57){ sbf.append(val); }else if(97<=val && val<=122){ sbf.append(val); } } allText = sbf.toString();//获取所有字符(去分隔符后) Pattern expression = Pattern.compile("[a-z]{4,}[a-z0-9]*"); String str = content; Matcher matcher = expression.matcher(str); String word; ArrayList<String> group = new ArrayList<>(); while (matcher.find()) {//提取单词 word = matcher.group(); group.add(word);//单词归组 } int len = group.size(); for (int i = 0; i <= len-m; i++) { String pr = ""; String pr2 = ""; for (int j = i; j < i+m; j++) {//将m个单词构成字符串pr,pr2为记录单词构成的词组 pr += group.get(j); pr2 += group.get(j); if(j < (i+m)-1){ pr2 +=" "; } } if(allText.indexOf(pr)!=-1){//在allText中匹配子字符串pr if (records2.containsKey(pr2)) {//词组归组 records2.put(pr2, records2.get(pr2) + weight); } else { records2.put(pr2, weight); } } } }- 统计高频单词
//统计热度单词 public static void countHotWords(){ sortWords(); String str; int length = wordList.size(); if(length > n){ for(int i = 0; i < n; i++){ str = wordList.get(i); hotWordList.add(str); } } else{ hotWordList.addAll(wordList); } }- 统计高频词组
//统计热度词组 public static void countHotWordGroups(){ sortWordGroups(); String str; int length = wordGroupList.size(); if(length > n){ for(int i = 0; i < n; i++){ str = wordGroupList.get(i); hotWordGroupList.add(str); } } else{ hotWordGroupList.addAll(wordGroupList); } }- 高频单词排序
//单词排序 public static void sortWords(){ List<Map.Entry<String, Integer>> list = new ArrayList<>(records.entrySet()); Collections.sort(list, new Comparator<Map.Entry<String, Integer>>() { @Override public int compare(Map.Entry<String, Integer> o1, Map.Entry<String, Integer> o2) { return o2.getValue().compareTo(o1.getValue()); } }); String str; for (Map.Entry<String, Integer> e: list) { str = e.getKey()+":"+e.getValue(); wordList.add(str); } }- 高频词组排序
//词组排序 public static void sortWordGroups(){ List<Map.Entry<String, Integer>> list = new ArrayList<>(records2.entrySet()); Collections.sort(list, new Comparator<Map.Entry<String, Integer>>() { @Override public int compare(Map.Entry<String, Integer> o1, Map.Entry<String, Integer> o2) { return o2.getValue().compareTo(o1.getValue()); } }); String str; for (Map.Entry<String, Integer> e: list) { str = "<"+e.getKey()+">:"+e.getValue(); wordGroupList.add(str); } }
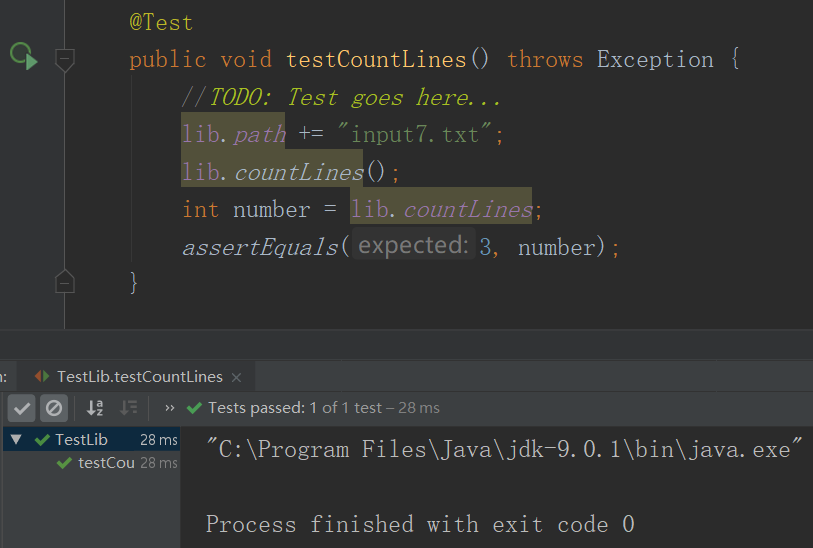
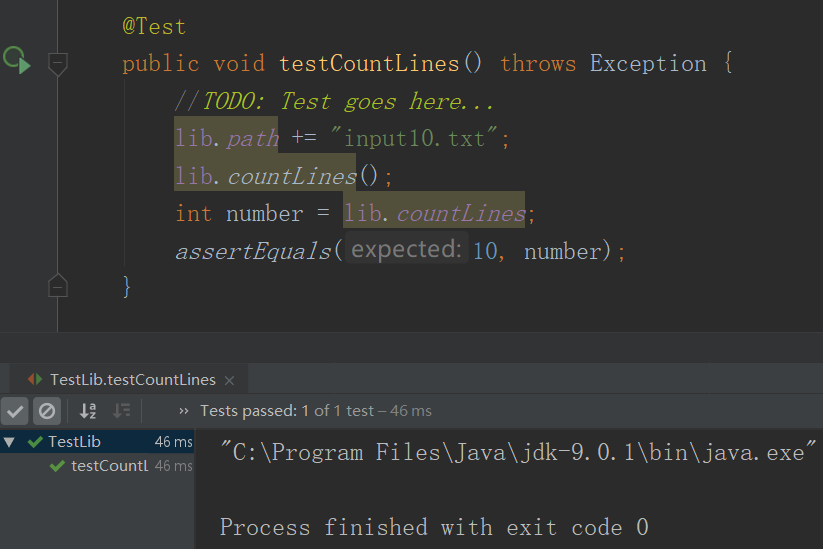
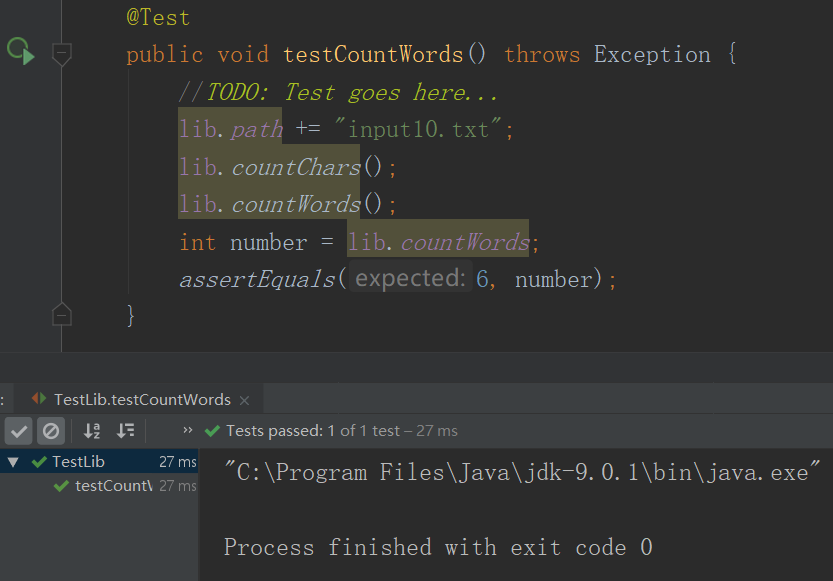
4.WordCount基本需求单元测试
- 样例1
- 测试1结果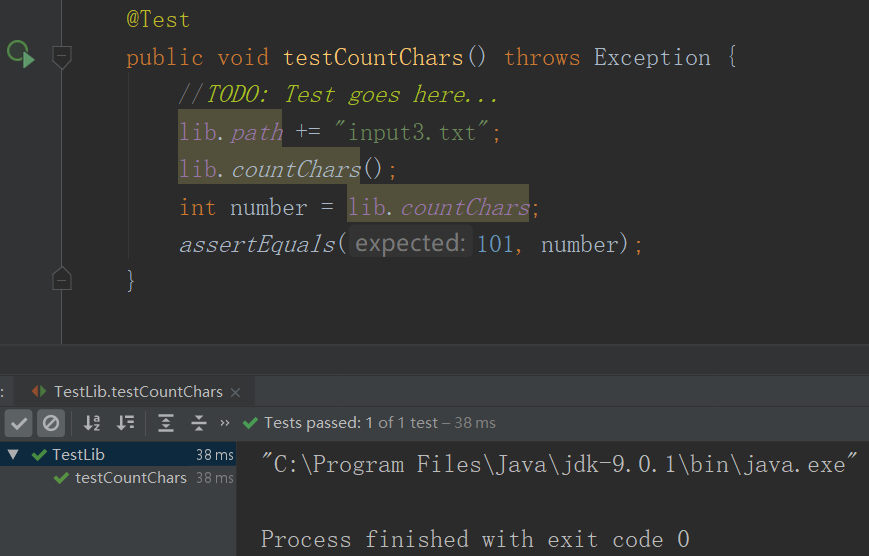
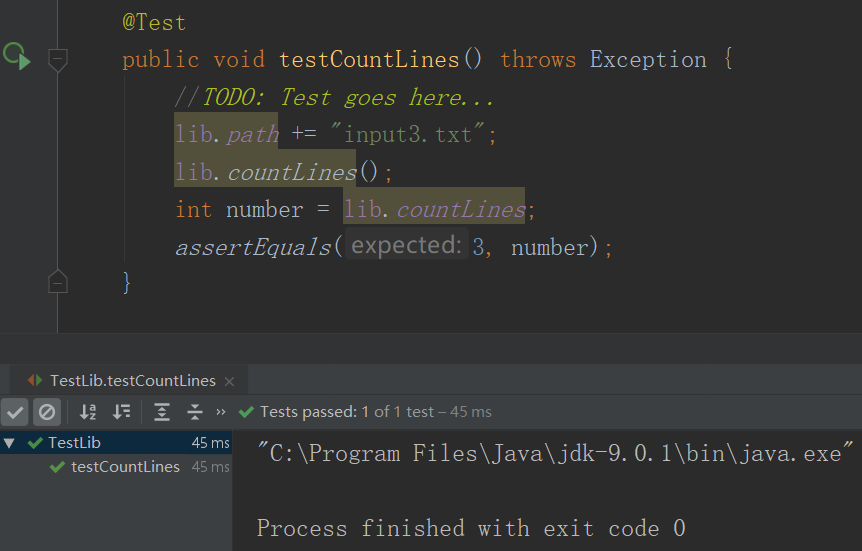
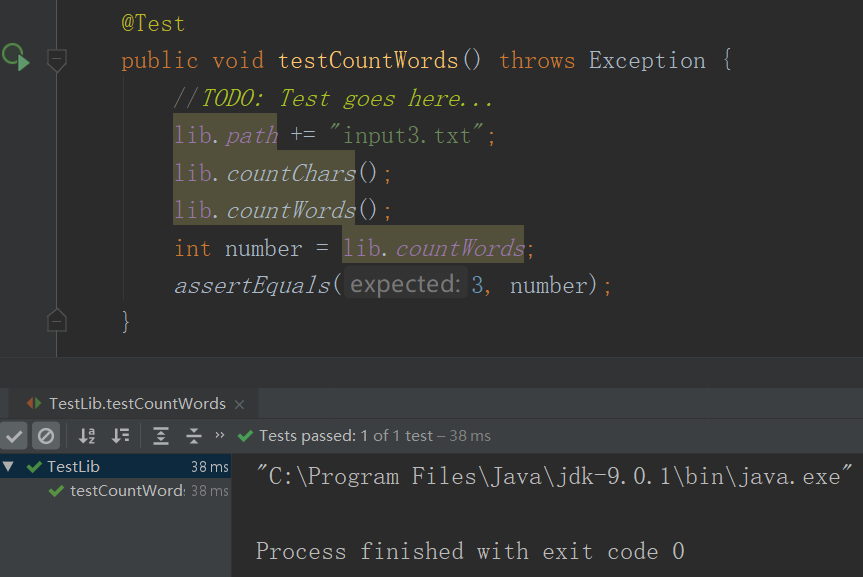
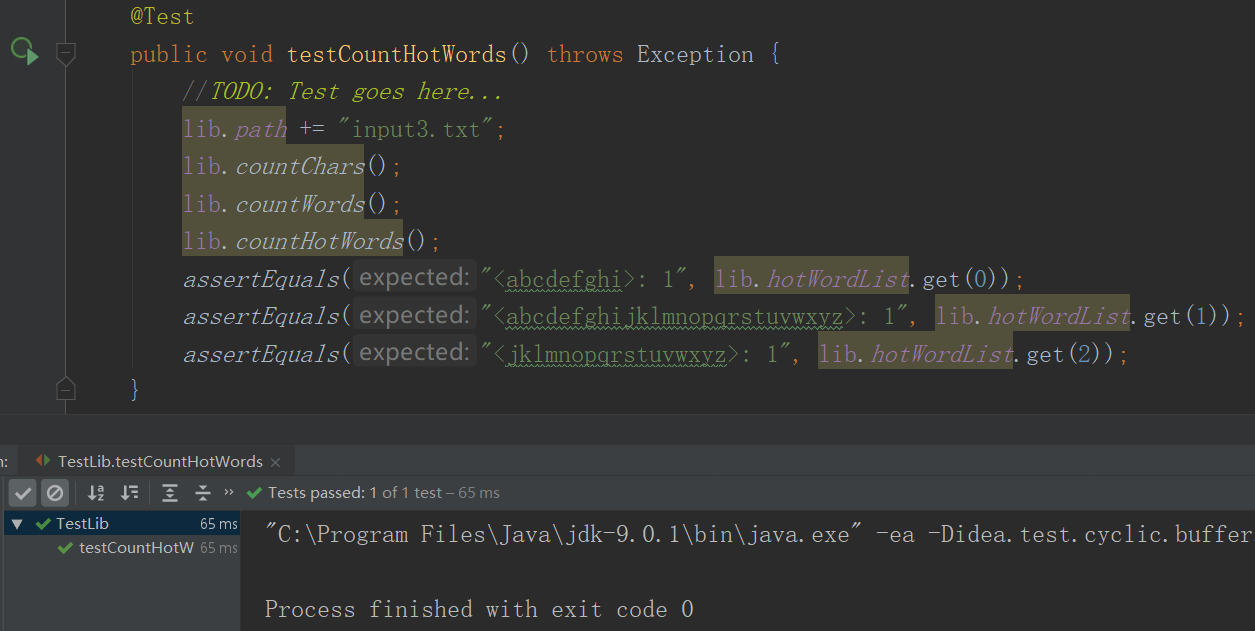
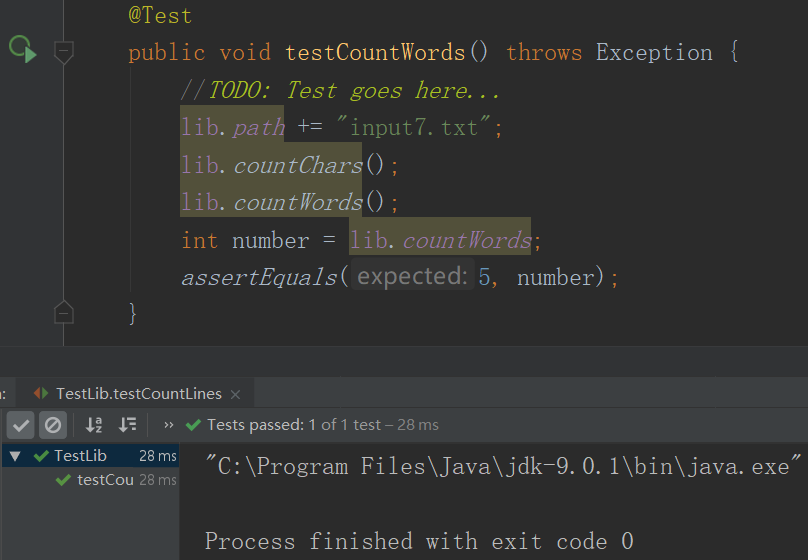
- 样例2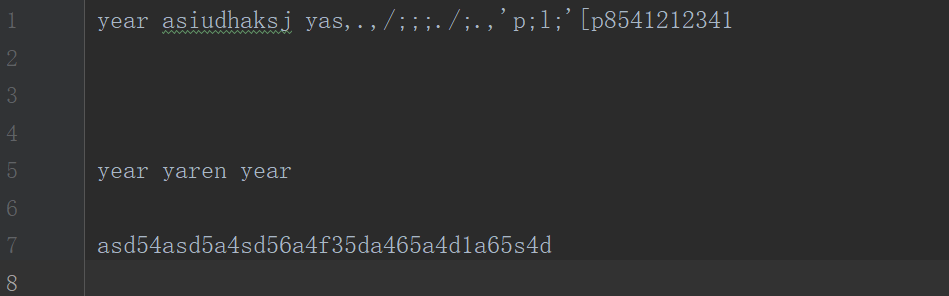
- 测试2结果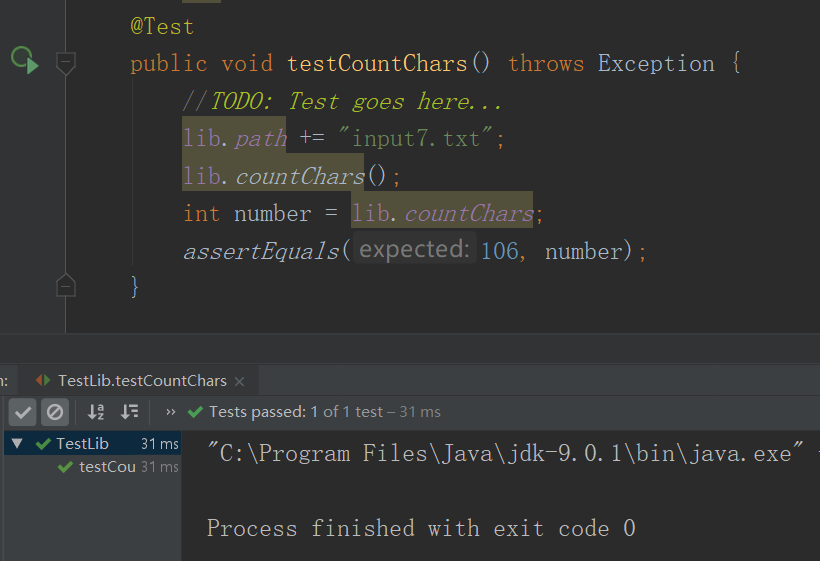
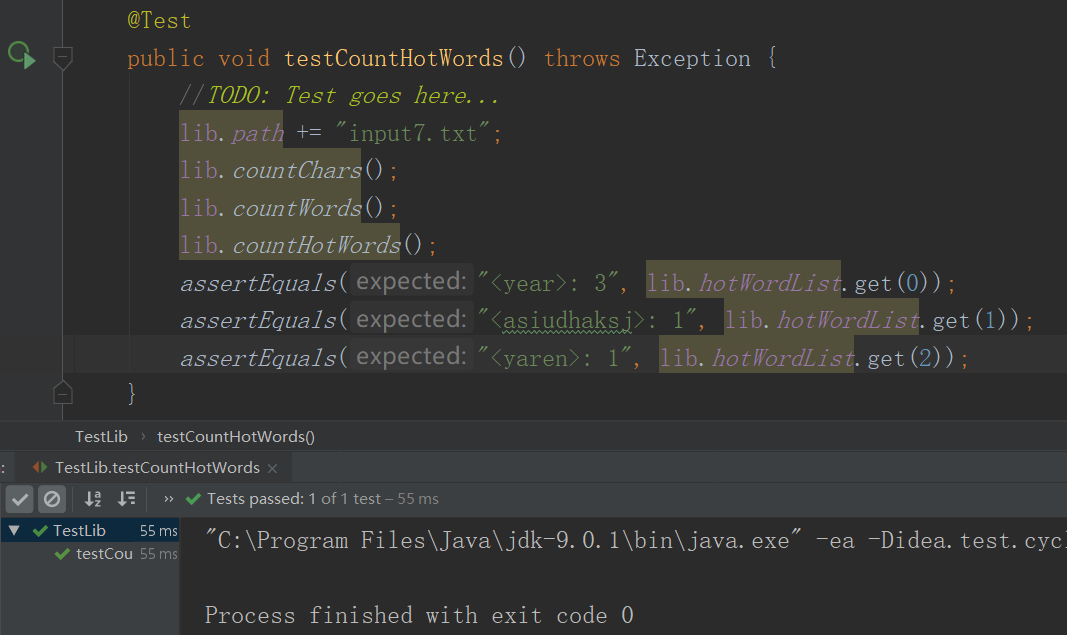
- 样例3
- 测试3结果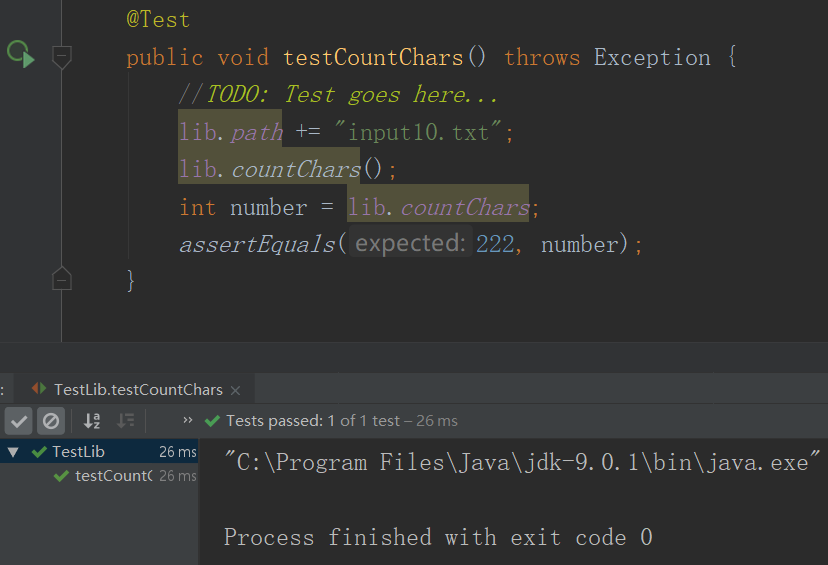
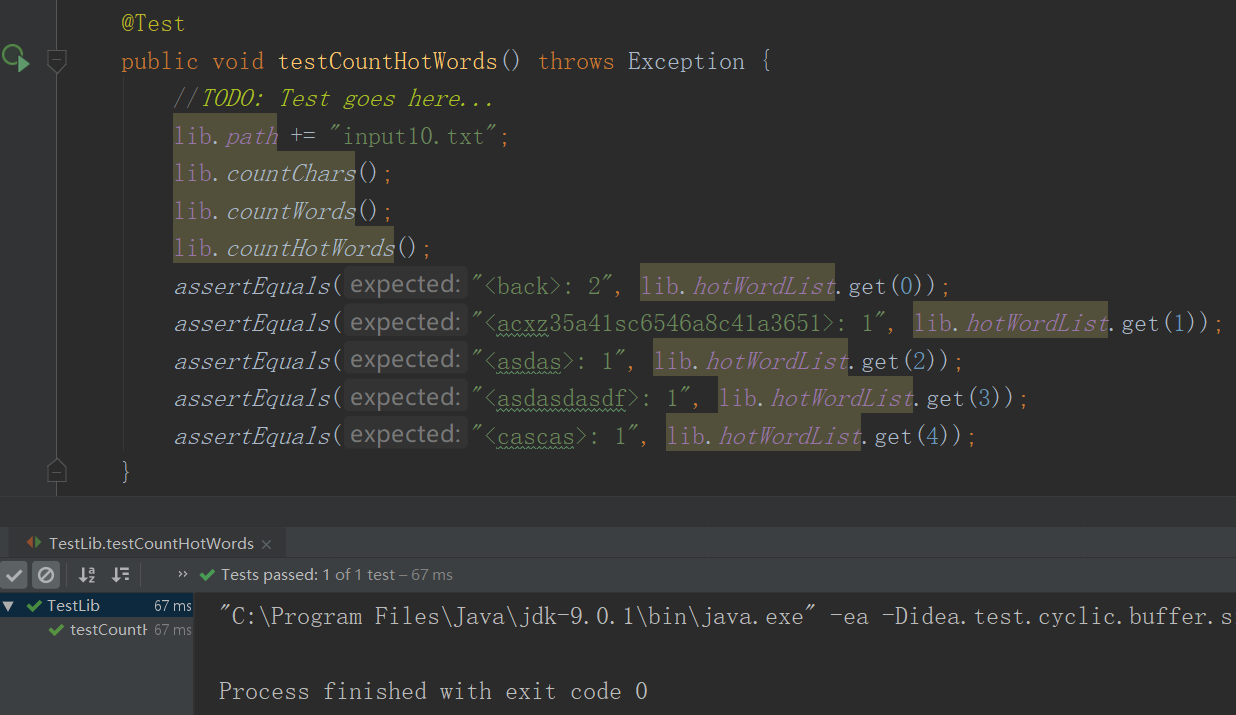
- WordCount进阶需求单元测试
- 由于时间的原因,未能实现单元测试功能。。。
5.交流与讨论
D:每个人分工不均
A:多商量多讨论
D:需求理解不到位
A:分析理解讨论需求
D:代码BUG改不出来
A:多多时候搜索引擎
6.困难与解决
- 对于统计文件的字符数,原本打算通过readLine()方法读取求取长度以获取字符数,但是突然发现行不通,因为readLine()不能读取换行,而且不能判断最后一行是否换行,以及空白行,最后决定采用read()方法逐个字符读取。
- 对于统计文件的有效行数,本来想借用read()读取到的“\n”字符来判断行数,突然发现空白行不能解决,照样统计,于是改用readLine()方法,借助正则表达式匹配空行的方法解决。
- 对于单词个数的统计,正则表达式一步到位。但是对于TreeMap的排序,自己还不很懂,最后通过百度,找到Collections接口调用排序得以解决。
- 对于“Core模块”的功能,我还不是很懂,不知道怎么把统计字符数,统计单词数,统计最多的10个单词及其词频这三个功能独立出来,总感觉三个功能模块联系密切,最后也只是简单地将每个功能单独成函数形式简单分离。
- 对于Jsoup爬虫工具的使用还不是很熟练,如元素的定位和信息的提取经常出错。
- 对于统计论文当中的字符数,刚开始用readLine()方法读取title和abstract内容,发现并不能正确统计字符数,当中存在棘手的问题,就是换行符的统计不准确,最后决定采用总字符数减掉论文编号所在行的字符数,title:和abstract:的字符数。
- 对于单词词组的统计,刚开始无从下手,想采用正则表达式匹配,突然发现该怎么构建正则表达式,最后想了很久,决定采用拟字符串匹配算法的方法。也就是说,先把多个单词构成字符串,接着把要出来的字符串进行去分隔符的整合处理成大字符串,然后用子字符串去匹配,如匹配成功,则该词组满足要求,反之不成立,最后将满足要求的词组进行词频统计并保存。
7.心得与总结
最大的收获,应该就是发现问题,解决问题的过程,有时候因为一小小的细节,弄得自己焦头烂额,但是当突然找到问题的所在时,心里顿时轻松了很多。这或许是调试bug必然的过程。此外,我们也学到了一些实用的技能,如Jsoup工具的使用,GitHub的项目的上传等。
蔡鸿键
这次结对我对于团队的作用比较小,主要负责文档的编写与GITHUB的上传和代码测试优化,在代码这一块涉及比较小,主要是因为分工不明。我认为以后团队编码时应该大家先聚在一起讨论需求题目,相互信任,这才会使团队作用最大化。
队友这次主要负责代码部分,特别认真,考虑周到,分析需求到位。
蔡森林
这次结对编程,总体来说,收获还是挺大的,我主要负责代码编程,很多时候经常被一小bug弄得焦头烂额,但是有时候突然灵光一现,那又是多么令人开心的事。此次的编程,不仅让我的编程能力得到了锻炼,也让我学到了一些新的知识,更重要的是,团队协作,不仅可以督促自己,而且更能提高效率。
队友这次主要负责项目上传,博客撰写以及后期代码测试和优化,时不时给我提供思路参考。
总结
这次任务涉及代码部分但其实是模仿现在公司的代码编程规范,现在让我们接触这些规范是有好处的,能及时的改成我们的错误的编程,培养良好的,高效率的编程。这是非常重要的。
PSP
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分 钟) |
| Planning | 计划 | ||
| • Estimate | • 估计这个任务需要多少时间 | 600 | 550 |
| Development | 开发 | ||
| • Analysis | • 需求分析 (包括学习新技术) | 30 | 60 |
| • Design Spec | • ⽣成设计⽂档 | 20 | 30 |
| • Design Review | • 设计复审 | 20 | 10 |
| • Coding Standard | • 代码规范 (为目前的开发制定合适的规范) | 20 | 20 |
| • Design | • 具体设计 | 120 | 250 |
| • Coding | • 具体编码 | 360* | 480* |
| • Code Review | • 代码复审 | 30 | 30 |
| • Test | • 测试(自我测试,修改代码,提交修改) | 30 | 20 |
| Reporting | 报告 | ||
| • Test Repor | • 测试报告 | 10 | 15 |
| • Size Measurement | • 计算工作量 | 15 | 10 |
| • Postmortem & Process Improvement Plan | • 事后总结, 并提出过程改进计划 | 30 | 25 |
| 合计 | 685 | 950 |

















 365
365

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









