







 本文介绍了一种使用C语言处理文件的方法,包括读取文件字符、统计单词数量和使用二维数组存储每行的字符数和单词数。通过一个具体示例,展示了如何实现这些功能,并与Word文档的统计功能进行了对比验证。
本文介绍了一种使用C语言处理文件的方法,包括读取文件字符、统计单词数量和使用二维数组存储每行的字符数和单词数。通过一个具体示例,展示了如何实现这些功能,并与Word文档的统计功能进行了对比验证。
【总结】
1.读取文件字符的一般步骤:首先打开文件并判断是否正常打开;然后先读取一个字符,然后判断是否为空文件,如果不是空文件则做循环;输出字符;读取下一个字符,如果下一个字符为EOF则结束循环。
2.统计文件中单词的数目:用word来标记,如果word为0表示此前的字符不是字母,未开始一个新单词;如果word为1表示已经开始或正在读取一个单词。
3.用二维数组来存储每行的字符数和单词数。
【代码】
#include <stdio.h>
#include <stdlib.h>
#include <ctype.h>
#define maxSize 100
int Counting(FILE* fp, int a[][2])
{
char ch;
int k = 0;
int word = 0;//一开始未读入新单词,所以word为0
fscanf(fp, "%c", &ch);
while (!feof(fp))
{
if (ch == '\n')
{
word = 0;
k++;
}
else
{
a[k][0] += 1;//该行的字符数加一
if (!isalpha(ch))
word = 0;
else if (word == 0)//如果是字母,并且此前的字符不是字母
{
a[k][1] += 1;//该行单词数加一
word = 1;//表示现在读取的字母是属于同一个单词
}
}
fscanf(fp, "%c", &ch);//读取下一个字符,如果下一个字符为EOF则停止统计
}
fclose(fp);
return k + 1;//返回总的行数,因为是从0行开始所以要加一
}
int main()
{
int sum_ch = 0, sum_words = 0;
int sum_rows;
int a[maxSize][2] = { 0 };
FILE* fp;
if ((fp = fopen("data56.txt", "r")) == NULL)
{
exit(0);
}
sum_rows = Counting(fp, a);;
int i;
for (i = 0; i < sum_rows; ++i)
{
printf("%dth: characters:%d, words:%d\n", i + 1, a[i][0], a[i][1]);
sum_ch += a[i][0];
sum_words += a[i][1];
}
printf("sum_ch:%d\nsum_words:%d\nsum_rows:%d\n", sum_ch, sum_words, sum_rows);
return 0;
}【验证】
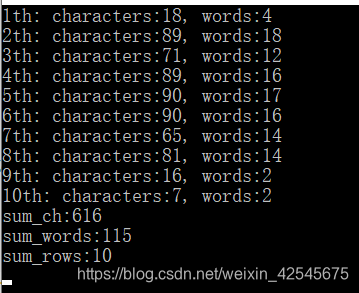
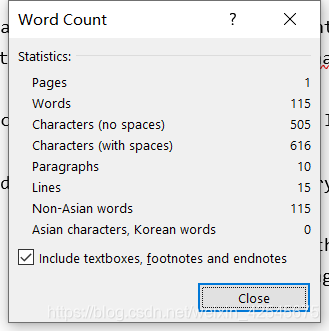
与word文档的统计功能做比较:
【文本文件】
Dear Sir or Madam,
I am one of customers in your online store. I am writing this letter for the purpose of
making a complaint about an electonic dictionary I bought two days ago.
The reason for my dissatisfaction is that the dicitionay is of very low quality. In the
first place, the battery can only last for three hours. In addition, there are a number of
spelling mistakes in the dictionary. I appreciate it very much if you could change one for
me, and I would like this matter settled by the end of this week.
Thank you for your time and consideration. I am looking forward for your reply.
Yours sincerely,
Li Ming



















 2020
2020

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











