






2024年7月16日,大暑将至,立秋不远。我们基于Python的转录组学全分析框架的文章——"OmicVerse: a framework for bridging and deepening insights across bulk and single-cell sequencing"——正式在Nature Communication上发表了,这是我们课题组第一个里程碑意义的成果,也是我第一篇作为第一作者发表在Nature系列期刊上的文章,对我们的成果感兴趣的朋友可以查看文末的【原文链接】。
我在去年7月份的时候,将OmicVerse的第一个版本发布到了预印本网站Biorxiv上,并在“生信技能树”等公众号上撰写了一些大致的介绍。在这里,我想写一些OmicVerse开发背后的故事,以及该框架的愿景是什么。
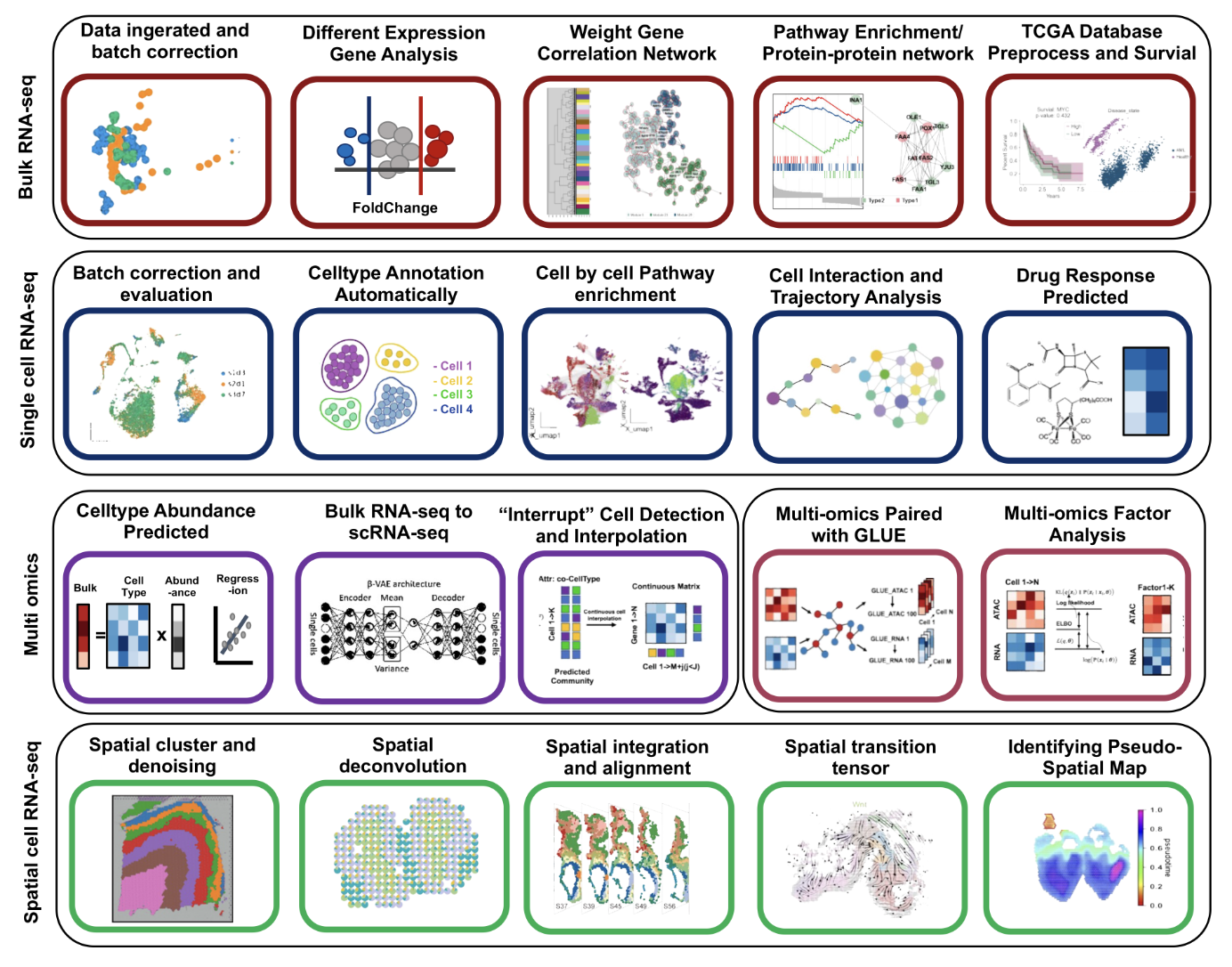
框架起源
我应该是大二上的时候开始接触生物信息学,那会儿单细胞测序刚刚兴起,生信还是一片蓝海,那会儿你会一个RNA-seq的分析,都能被课题组当成是一个宝贝。我算是半个科班出身,得益于计算机的双学位,我在接触生物信息学的时候,没有遇到太大的门槛,调包-分析,一气呵成。
但是很快我遇到了第一个问题,那就是对R语言的不熟悉,以至于很多依赖出错的时候,我没法去手动修改,并且R语言的语法对C++出身的程序员来说,并不是什么友好的代码规范,我也尝试过tidyverse,但最后还是放弃了。在阅读了转录组分析的统计学模型后,我开始萌生了一个想法:“我为什么不自己用Python复现转录组分析的算法呢?“
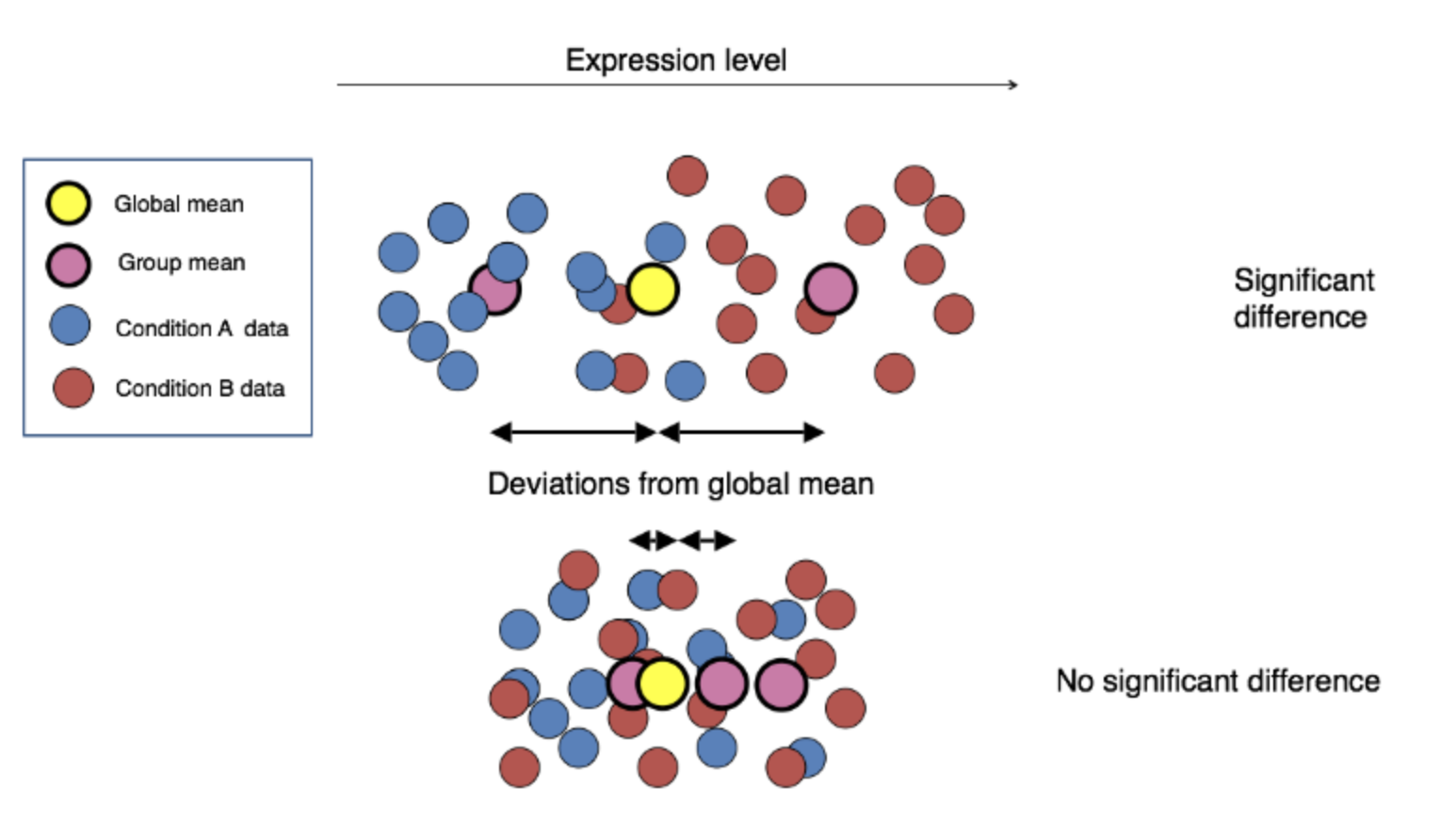
说时迟那时快,我很快便把ttest,foldchange等统计学模型应用到了RNA-seq上,然后使用matplotlib(Python的绘图包)完成了可视化,然后为了方便,我开始自学Python包制作,我将这些函数,全部封装进了一个包,叫Pyomic。这时候,我也大三了。同时在转录组分析的时候,写了第一个算法ERgene,这是一个快速计算内参基因的算法,这个算法最开始是用来解决蛋白质组中的内参定量的问题,常见的内参有时候在质谱中找不到。得益于我的老师杜宏武的鼓励,我将这个包封装测试后,发表在了Scientific Report上,时至今日,我还是很喜欢这个算法,因为我在做benchmark的时候,在电脑装了windows7的虚拟机运行excel2003来跑一些古老的算法。
我的成绩还可以,拿到了我们学校的保研资格,于是到处去面试,跟老师们交流,印象比较深的有两件事:
- 第一件是在北京大学面试的时候发生的,当时可能觉得MIT协议很好,于是Pyomic的协议也是MIT。在面试的时候,高歌老师直接指出了这个问题,问了我两遍,Pyomic的算法都是自己写的吗?我当时引入了一个外部dynamicTree的模块,这是WGCNA的核心算法,但我觉得我整个分析都是自己实现的,于是就被diss了,问我为啥把别人GPL的协议给继承成了MIT。自此,我对著作权,有了一个更清晰的认识。
- 第二件是在中山大学面试的时候发生的,当时有个PI问我,你觉得Pyomic有什么意义吗?就是复现别人的算法?时至今日,这个问题有了一个很好的答案,我们为Python分析转录组学奠定了一个分析标准,统一了各类接口,这是一个很值得做的事情。
OmicVerse的正式提出
OmicVerse这个名字,是在2023年4月份的时候,也就是我博一的时候确定的。当时我在处理单细胞转录组的数据,遇到了两个让我很烦躁的问题:”包安装的依赖冲突“和”不同包的输入输出差异极大“,这两件事严重拖低了我的分析效率,我便在想,我能否统一这些算法,使其安装不报错,输入只需要一种格式就好了。于是,我便开始研究算法们背后的输入和输出。然后写着写着,就封装了大量的算法,因为顺手,所以这些算法都是扔进了Pyomic这个包中进行实现。
受到scvi-tools的启发,这是一个用于单细胞测序的深度学习模型框架,我就想弄一个更全面的基于Python的单细胞测序分析框架。Pyomic感觉这个名字,并不能准确反映我想做的事,在几经查阅英文命名后,有一天晚上散步的时候,看着天上的星星,突然想到,为啥我不用“Verse”结尾呢?于是便有了OmicVerse,一个月的时间,便把所有算法封装好,并且撰写按Brief Communication的形式撰写好了手稿。

但还没开始投,投稿前总是需要问一问的。于是,我就分别给“Nature Biotechnology”和”Nature Method“的编辑写信,问了一下他们对这篇稿件的兴趣,叫做投稿前预询问,然后Method的编辑很高兴,让我们投过去,但是Biotechnology的编辑就差没把”Rubbish“两字写邮件里了。我确实是不死心的,死也要死的明白点,想问一下我到底缺了什么,后面在我的再三恳切地询问后,她告诉我说,没有biological insight。有时候,灵感就是一瞬间的事儿,我既然分别封装了Bulk RNA-seq和single cell RNA-seq,这缺一个桥梁算法啊!不过一查,Bulk2single有人做过了,single2bulk就更不用说。不过有趣的是,我在此前开发了一个轨迹推断的算法,这个算法在一些数据集上效果怎么都差,我就在想,我可以使用Bulk来插补轨迹呀!于是,这就是BulkTrajBlend的雏形,后面做了一系列工作来完善,这是后话了。
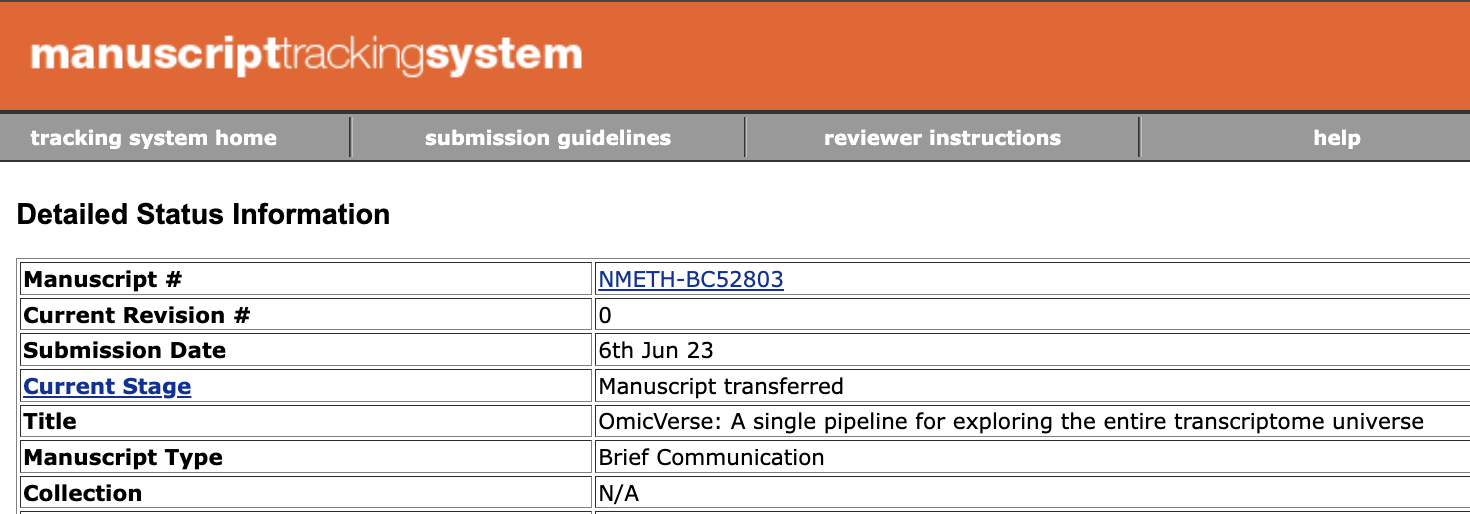
于是我就兴高采烈地,投到了Nature Method的投稿系统,然后。。。一个月的等待,给我拒了,让我转NC,我也不能说什么,NC就NC吧,毕竟我博士期间还没论文呢。后来今年3月份的时候,我看见了Method上发了tidyomics,我始终没想明白,OmicVerse比这个算法差在哪里了?
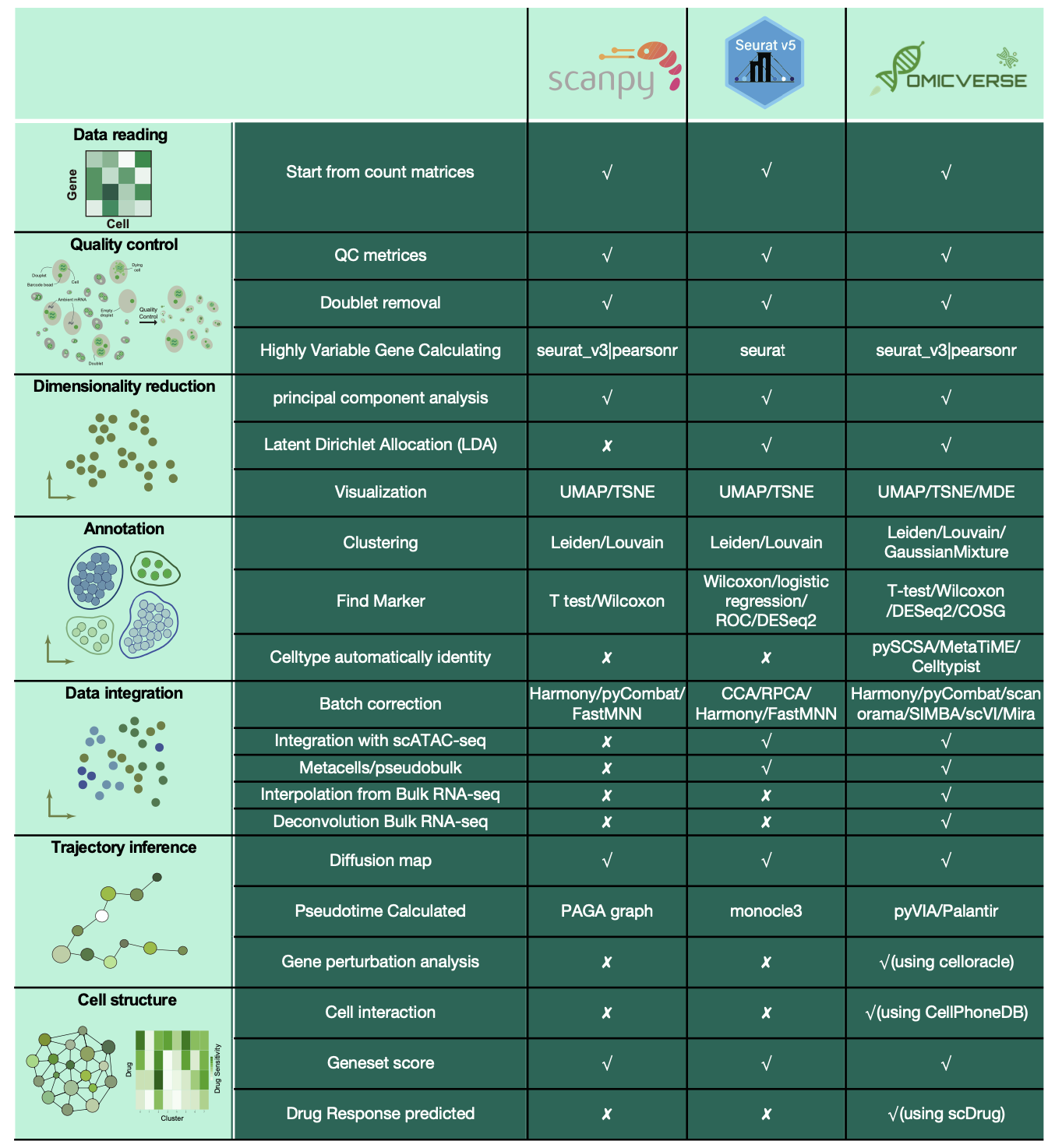
OmicVerse的壮大
此前似乎是询问问题,我加了Python生物人的公众号的作者,在OmicVerse投出去之前我先挂了预印本,然后想试试推广,看看广大用户对于OmicVerse的反馈如何,于是便拜托Python生物人写了一篇推送,并且带上”清华大学“的tag,但似乎受众寥寥。
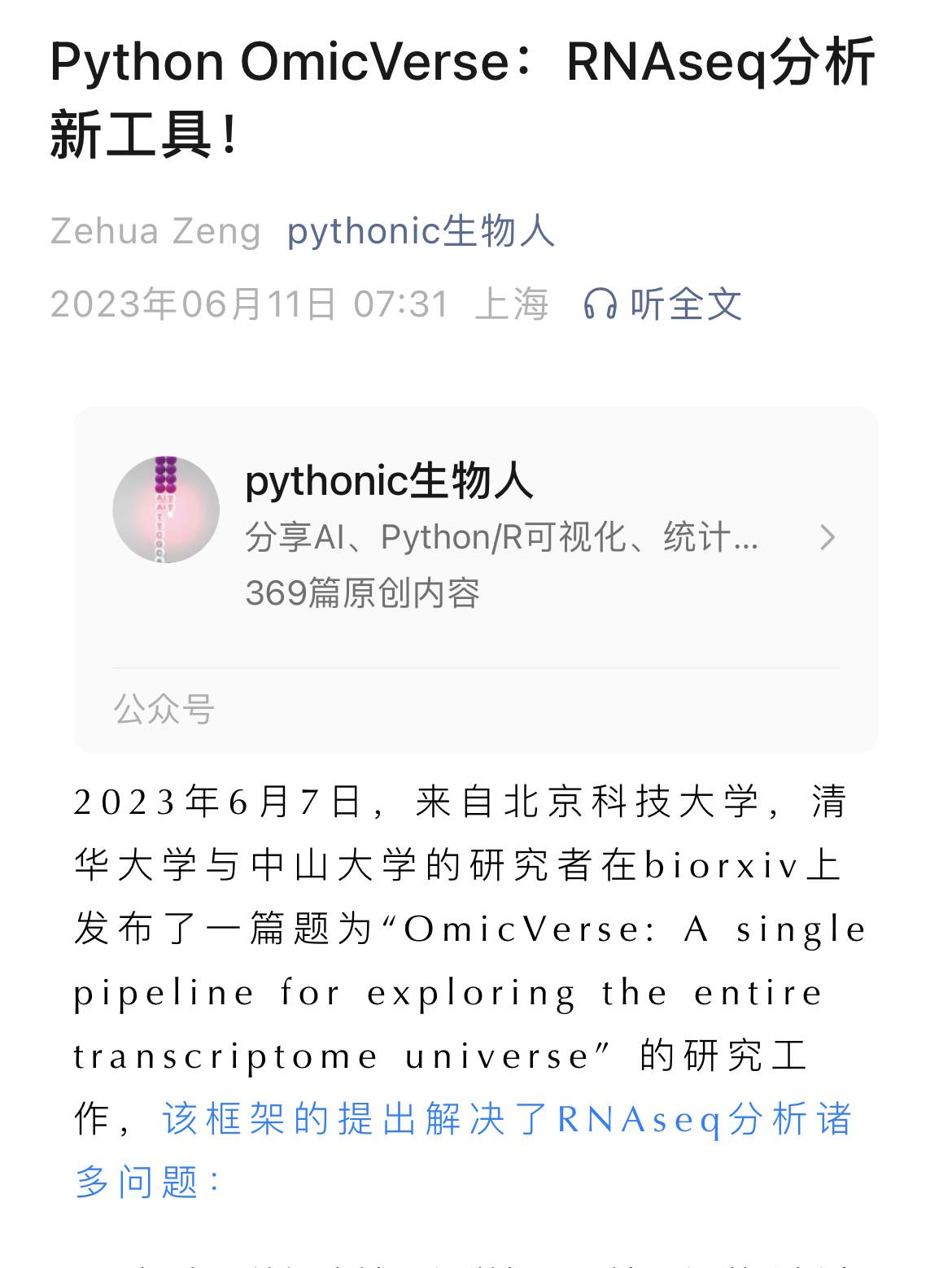
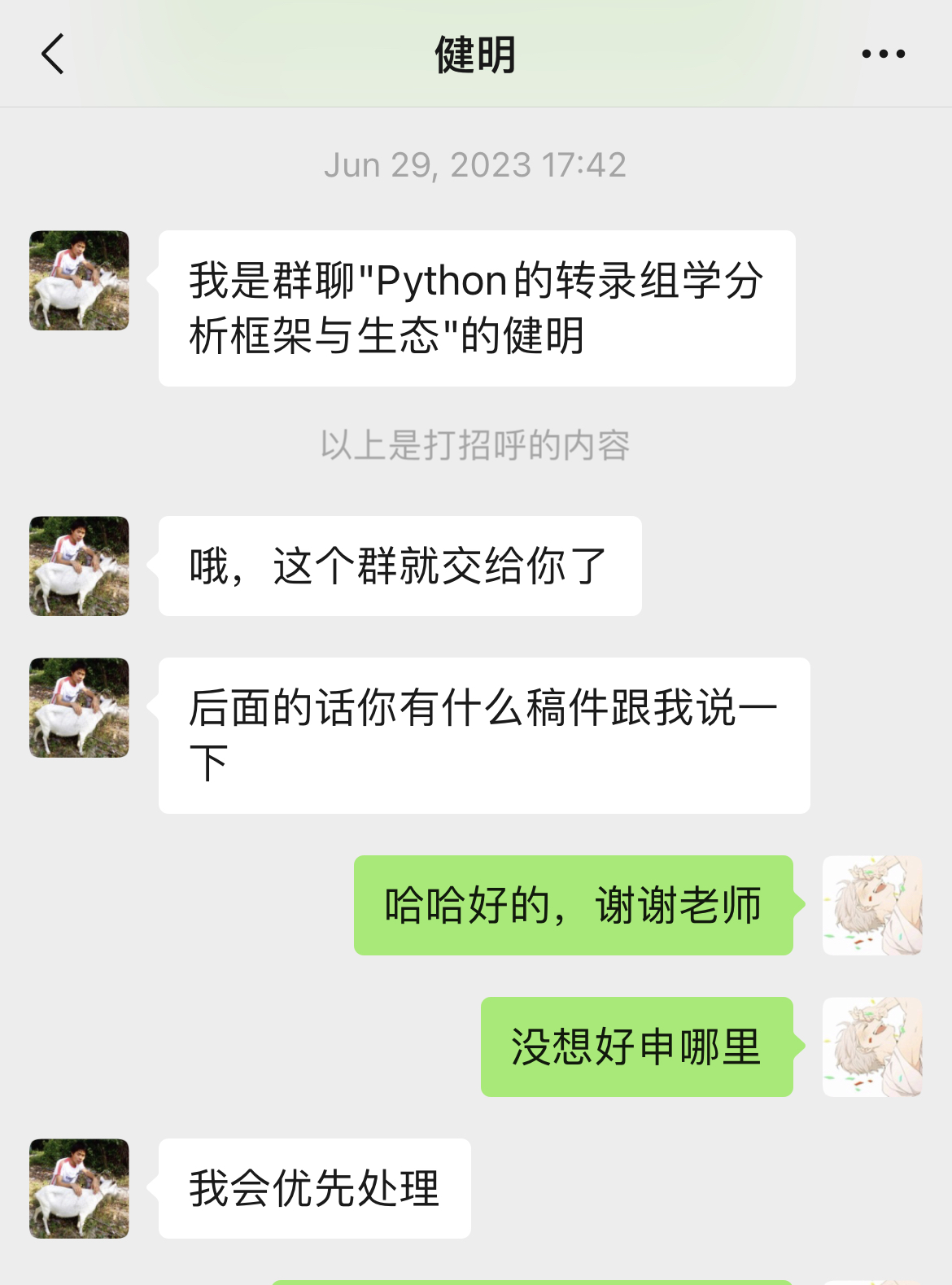
我觉得,不应该啊,我这个框架这么好用!于是,就拜托健明老师,在”技能树“上发文。但令我意外的是,健明老师特别喜欢这个框架,给了我大大的鼓励,并且着重宣传了一下Python,国产,全面等字眼,然后还成立了社群,自此,OmicVerse便开始被人所知晓,但是没文章,大家可能更多持一个观望的态度。以至于,到2024年4月,才有了第一个引用。
此外,我觉得,一个好用的算法,而且还是框架,不配置全面的教程怎么可以。所以我的用户文档,写的非常非常详细,这也是受一些算法写的不详细的迫害所养成的习惯,你写的越详细,就越方便他人,大家也就更愿意去使用。
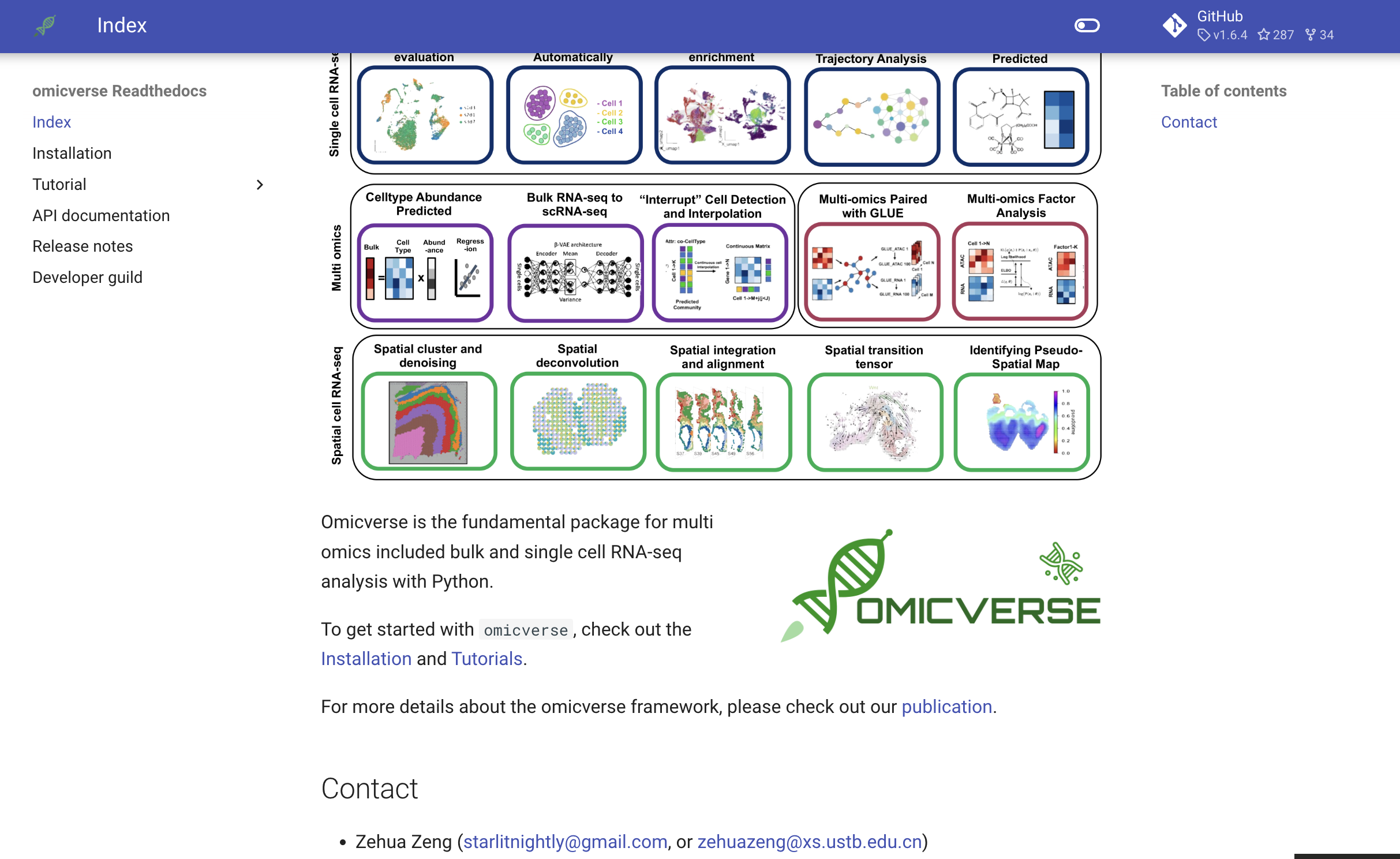
我觉得我做的最明智的一件事,那就是撰写了单细胞分析最好的教程——中文版,该教程脱胎于febain组的单细胞最佳实践,但是,我在原教程的基础上,加上了大量我自己的理解以及新算法,同时新算法使用OmicVerse作为统一接口,还开发了大量漂亮的可视化函数,用户也因此,慢慢变多了。我觉得互联网开源的精神食粮,是用户们的正反馈,用爱发电,大家开心,我也就有动力去迭代下一个版本,目前经过一年,已经1.6.4了。
后记
从我投稿,到正式接收,满打满算正好一年整,实际上如果不是一个审稿人失联了,可能在寒假,就接收了。当然这也是无法抗拒的外因,只能说,在暑假发表,阴差阳错吧。后续还会有OmicVerse2,OmicFate等一系列算法和框架,大家敬请期待~
特别感谢我在中山大学夏令营面试的时候认识的熊远妍老师,也非常欢迎大家报考她的课题组,她是一个非常非常open的人,课题组的氛围可以说是相当ok,她算是我在生信领域第一个真正意义上的指导老师。此外还特别谢谢健明老师,大家可能也挺熟悉的,如果不是他提供了这样一个平台,还替我大力宣传,我觉得OmicVerse的用户可能依然寥寥,而且很有意思的是,我跟健明老师算是不打不相识,原因忘了是什么了,好像是我批判老师一些事情来着,狠狠地怼了。
最后的最后,大家可能会好奇我的导师,是一个怎样的人,能让我几乎完全自由和独立地去探索自己想做的课题,没有任何限制。并在合适的时候,提供一些相应的指导,我的导师杜宏武教授,就是这么一个有趣的人,在课题组,你的兴趣得到充分地尊重,只要你想做,你有动力,那么这件事就是可行的。
暑假到了,祝大家假期愉快~
作者介绍

曾泽华,00年生,北京科技大学生物技术、物联网工程本科双学位,北京科技大学化学博士在读,主要研究方向是单细胞多组学算法的开发及癌症和发育生物学中的基因动态调控。博士期间作为第一作者开发了转录组学生态框架OmicVerse,细胞命运因子推断算法OmicFate,单细胞轨迹恢复算法BulkTrajBlend。目前以第一或通讯(含共同)作者身份在Nature Communication,Advanced Function Material等杂志发表多篇研究论文,论文总影响因子100+。
原创作者: starlitnightly 转载于: https://www.cnblogs.com/starlitnightly/p/18315242
















 2299
2299

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









