






问题描述:
当我们直接爬虫国内网站时,中文会出现乱码
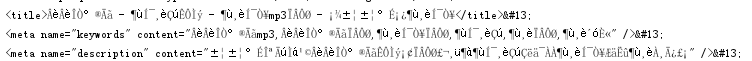
原因就是python 内部编码格式与我们爬虫的网站不一致。因为此时我们需要去目标网站先去看他的编码格式,如:
<meta http-equiv="Content-Type" content="text/html; charset=gb2312">
那么我们在python 解析时也要加上对应编码即可
rHtml = requests.get(link, headers=headers, timeout=20)
print(rHtml.status_code)
if (rHtml.status_code == 200):
rHtml.encoding = 'gb2312'
d = pq(rHtml.text)
print(d)

















 1258
1258

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









