






 本文介绍了一种在Linux环境下模拟CPU占用的小程序实现方法。包括让单个CPU核心达到100%占用、所有核心同时达到100%占用及指定特定核心满载的技术细节。此外还介绍了如何使用taskset命令绑定进程到特定CPU核心。
本文介绍了一种在Linux环境下模拟CPU占用的小程序实现方法。包括让单个CPU核心达到100%占用、所有核心同时达到100%占用及指定特定核心满载的技术细节。此外还介绍了如何使用taskset命令绑定进程到特定CPU核心。
linux下模拟CPU占用100%小程序
来源:https://blog.youkuaiyun.com/lin434406218/article/details/54694900
一、单个核100%
代码kill_cpu.c
#include <stdlib.h>
int main()
{
while(1);
return 0;
}
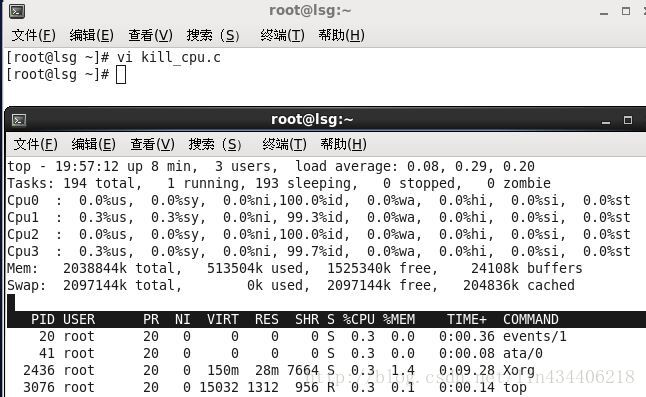
运行之前的CPU
运行:
# gcc -o out kill_cpu.c
# ./out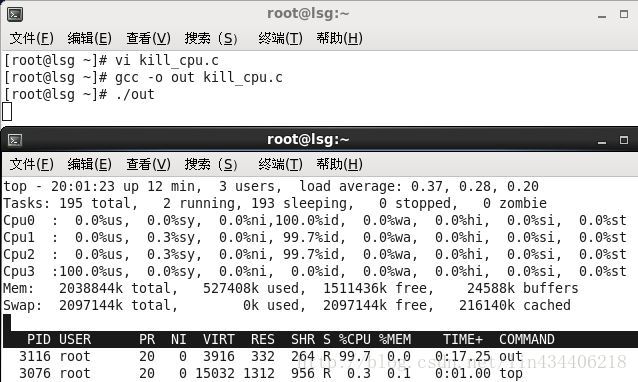
结束:Ctrl + C
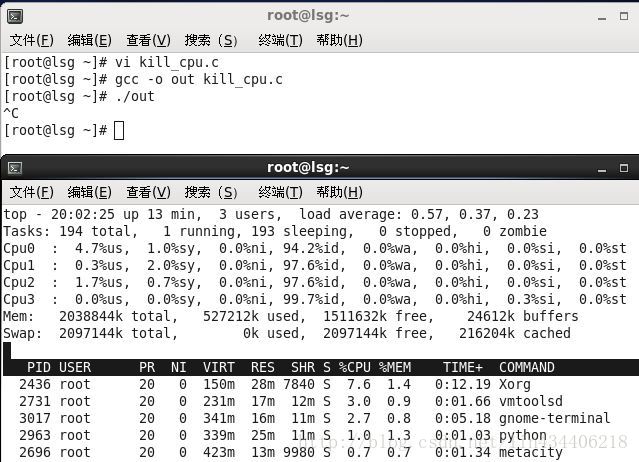
在运行程序之前先在本地测试自己的程序,避免程序的逻辑错误或者死循环的错误。
数据库服务器执行某一个SQL或者存储过程需要大量的运算(一般为软件设计不合理)
二、让所有的核都是100%
$ for i in `seq 1 $(cat /proc/cpuinfo | grep "physical id" | wc -l)`; do ./out & done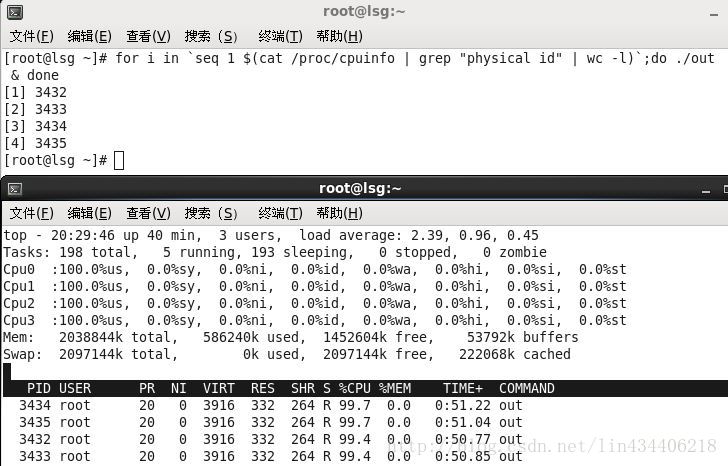
所有的核都是100%,cat /proc/cpuinfo | grep “physical id” | wc -l 是获取到CPU的核数,逻辑核数。这样每一个cpu上都会调度到一个死循环的进程。
批量kill进程
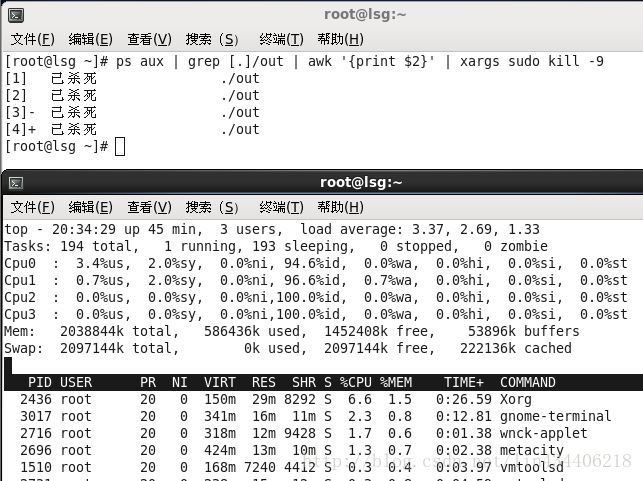
ps aux显示其他用户启动的进程(a)
查看系统中属于自己的进程(x)
启动这个进程的用户和它启动的时间(u)
把大的作业分给多个CPU一起运行,避免单个CPU运行导致CPU消耗过高而引发的系统奔溃问题
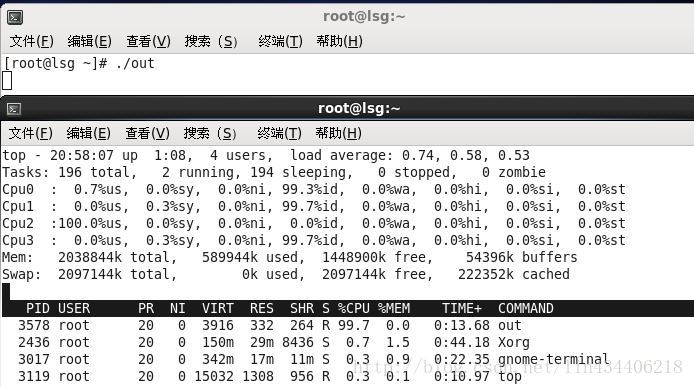
三、让某个核100%
当前的进程在cpu2上
通过taskset命令绑定CPU(taskset 指定进程运行在某个特定的CPU上)
taskset -cp CPUID 进程ID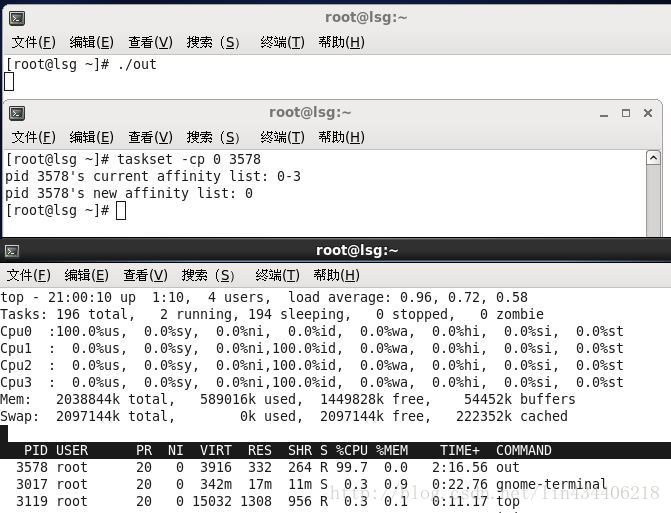
把某一个任务直接指定一个CPU专门运行,保证该任务快速运行,不会长期拉低整个系统的运作效率

















 1139
1139

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









