






 本文通过实例演示了如何使用NLTK进行文本分析,包括查找指定词汇的上下文、寻找相似词汇及绘制词汇分布图等操作。
本文通过实例演示了如何使用NLTK进行文本分析,包括查找指定词汇的上下文、寻找相似词汇及绘制词汇分布图等操作。
sklearn实战-乳腺癌细胞数据挖掘(博主亲自录制视频教程)

测试NLTK数据包
导入nltk.book包中所有的东西:
能使用以下函数的是nltk.text.Text对象
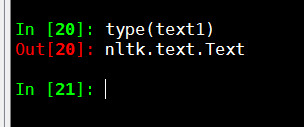
from nltk.book import *

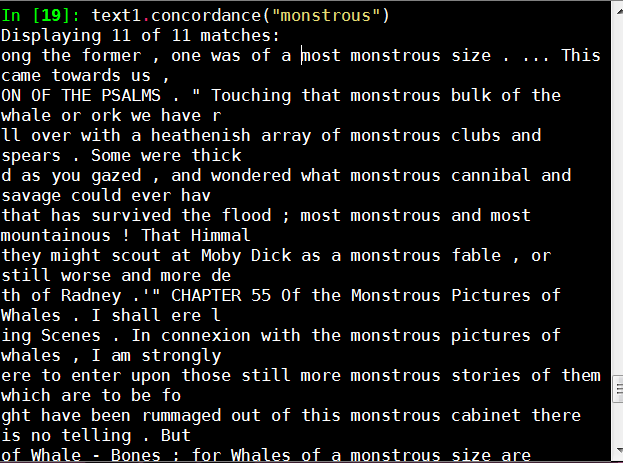
text1.concordance("monstrous")
找出文中含有单词monstrous的语句
再看几个例子。
查看语料库中的文本信息,直接敲它的名字:
-
- >>> text1
- <Text: Moby Dick by Herman Melville 1851>
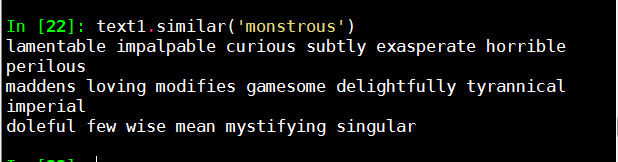
text1.similar('monstrous')
找出文中与单词monstrous(畸形,丑陋)的同义词
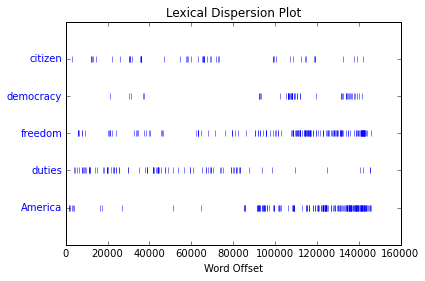
查看词语的分散度图
text4.dispersion_plot(['citizens','democracy','freedom','duties','America'])


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









