




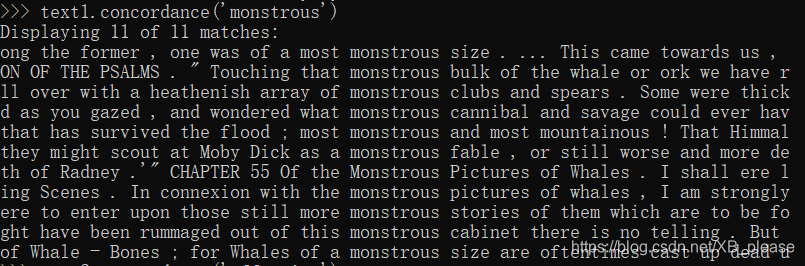
词语索引视图显示一个指定单词的每一次出现,连同一些上下文一起显示。
函数名concordance
函数名similar

函数common_contexts允许我们研究两个或两个以上的词共同的上下文,如monstro
us和very。我们必须用方括号和圆括号把这些词括起来,中间用逗号分割。

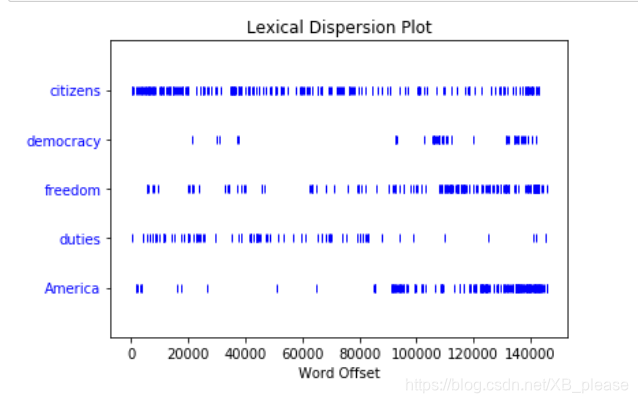
判断词在文本中的位置:从文本开头算起在它前面有多少词。这个位置信息可以用离散图表示。每一个竖线代表一个单词,每一行代表整个文本
绘制图形之前先导入numpy和matplotlib包
text4.dispersion_plot([“citizens”, “democracy”, “freedom”, “duties”, “America”])
函数名generate用来产生一些随机文本
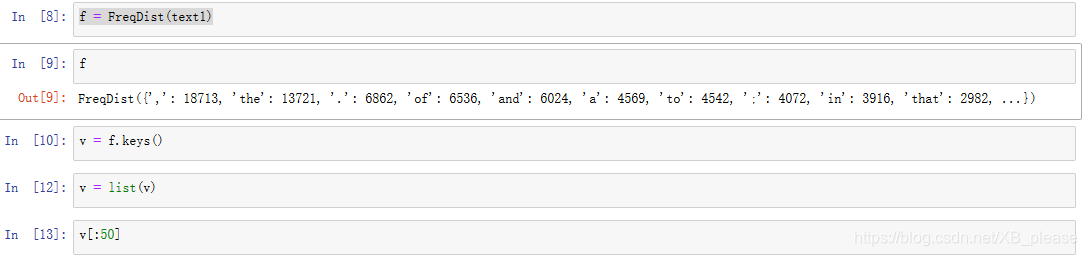
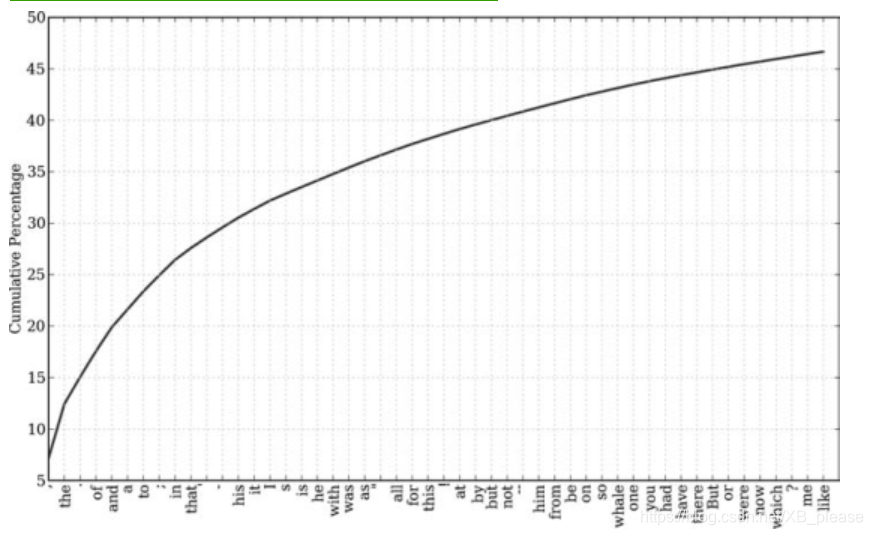
我们使用FreqDist寻找《白鲸记》中最常见的 50个词。可以产生一个这些词汇的累积频率图。用fdist1.plot(50,cumulative=True)产生图
f.plot(50,cumulative = True)
那些只出现一次的低频词我们用f.hapaxes()查看它们

















 399
399

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









