



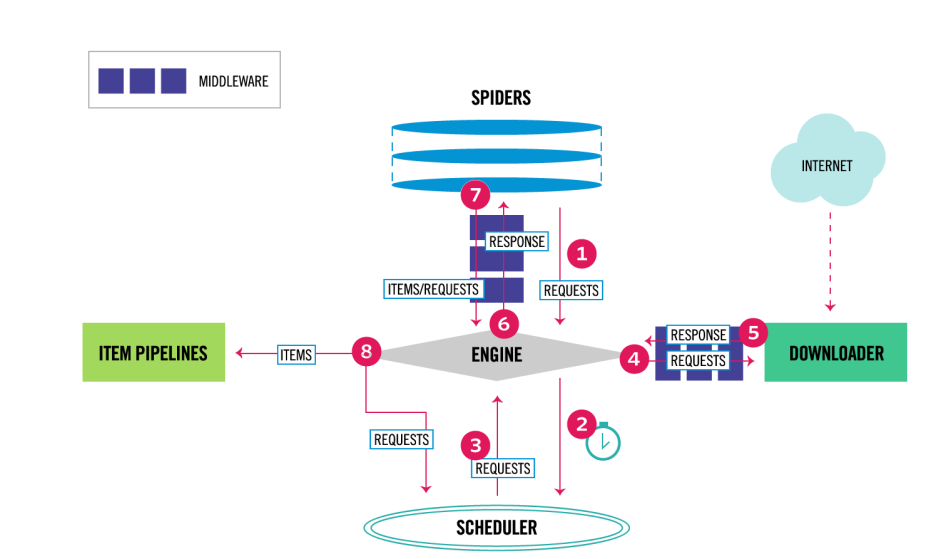
The data flow in Scrapy is controlled by the execution engine, and goes like this:
1. The Engine gets the initial Requests to crawl from the Spider.
2. The Engine schedules the Requests in the Scheduler and asks for the next Requests to crawl.
3. The Scheduler returns the next Requests to the Engine.
4. The Engine sends the Requests to the Downloader, passing through the Downloader Middlewares (see
process_request()).
5. Once the page finishes downloading the Downloader generates a Response (with that page) and sends it to the
Engine, passing through the Downloader Middlewares (see process_response()).
6. The Engine receives the Response from the Downloader and sends it to the Spider for processing, passing
through the Spider Middleware (see process_spider_input()).
7. The Spider processes the Response and returns scraped items and new Requests (to follow) to the Engine,
passing through the Spider Middleware (see process_spider_output()).
8. The Engine sends processed items to Item Pipelines, then send processed Requests to the Scheduler and asks
for possible next Requests to crawl.
9. The process repeats (from step 1) until there are no more requests from the Scheduler.

















 1054
1054

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









