






 本文详细介绍了HDFS中元数据的管理方式,包括edits文件和fsimage的作用及其交互流程,解释了为什么更改记录在edits而不是fsimage中,并讨论了两者合并的过程以及触发条件。
本文详细介绍了HDFS中元数据的管理方式,包括edits文件和fsimage的作用及其交互流程,解释了为什么更改记录在edits而不是fsimage中,并讨论了两者合并的过程以及触发条件。
客户端对hdfs进行写文件时会首先被记录在edits文件中。
edits修改时元数据也会更新。
每次hdfs更新时edits先更新后客户端才会看到最新信息。
fsimage:是namenode中关于元数据的镜像,一般称为检查点。
一般开始时对namenode的操作都放在edits中,为什么不放在fsimage中呢?
因为fsimage是namenode的完整的镜像,内容很大,如果每次都加载到内存的话生成树状拓扑结构,这是非常耗内存和CPU。
内容包含了namenode管理下的所有datanode中文件及文件block及block所在的datanode的元数据信息。随着edits内容增大,就需要在一定时间点和fsimage合并。
合并过程:
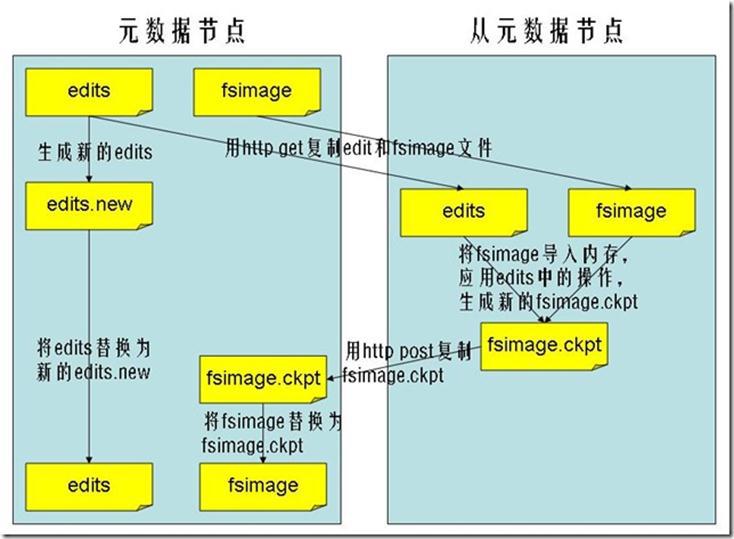

完成合并的是secondarynamenode,会请求namenode停止使用edits,暂时将新写操作放入一个新的文件中(edits.new)。secondarynamenode从namenode中通过http get获得edits,因为要和fsimage合并,所以也是通过http get 的方式把fsimage加载到内存,然后逐一执行具体对文件系统的操作,与fsimage合并,生成新的fsimage,然后把fsimage发送给namenode,通过http post的方式。namenode从secondarynamenode获得了fsimage后会把原有的fsimage替换为新的fsimage,把edits.new变成edits。同时会更新fstime。
hadoop进入安全模式时需要管理员使用dfsadmin的save namespace来创建新的检查点。
secondarynamenode在合并edits和fsimage时需要消耗的内存和namenode差不多,所以一般把namenode和secondarynamenode放在不同的机器上。
fs.checkpoint.period: 默认是一个小时(3600s)
fs.checkpoint.size: edits达到一定大小时也会触发合并(默认64MB)

















 481
481

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









