




 本文深入探讨HDFS中NameNode如何管理和维护元数据,包括FsImage和Edits文件的作用,SecondaryNameNode的工作原理,以及元数据在内存与磁盘间同步的详细流程。
本文深入探讨HDFS中NameNode如何管理和维护元数据,包括FsImage和Edits文件的作用,SecondaryNameNode的工作原理,以及元数据在内存与磁盘间同步的详细流程。
思考:NameNode中的元数据是存储在哪里的?
首先,我们做个假设,如果存储在NameNode节点的磁盘中,因为经常需要进行随机访问,还有响应客户请求,必然是效率过低。因此,元数据需要存放在内存中。但如果只存在内存中,一旦断电,元数据丢失,整个集群就无法工作了。因此产生在磁盘中备份元数据的FsImage。
这样又会带来新的问题,当在内存中的元数据更新时,如果同时更新FsImage,就会导致效率过低,但如果不更新,就会发生一致性问题,一旦NameNode节点断电,就会产生数据丢失。因此,引入Edits文件(只进行追加操作,效率很高)。每当元数据有更新或者添加元数据时,修改内存中的元数据并追加到Edits中。这样,一旦NameNode节点断电,可以通过FsImage和Edits的合并,合成元数据。
但是,如果长时间添加数据到Edits中,会导致该文件数据过大,效率降低,而且一旦断电,恢复元数据需要的时间过长。因此,需要定期进行FsImage和Edits的合并,如果这个操作由NameNode节点完成,又会效率过低。因此,引入一个新的节点SecondaryNamenode,专门用于FsImage和Edits的合并。
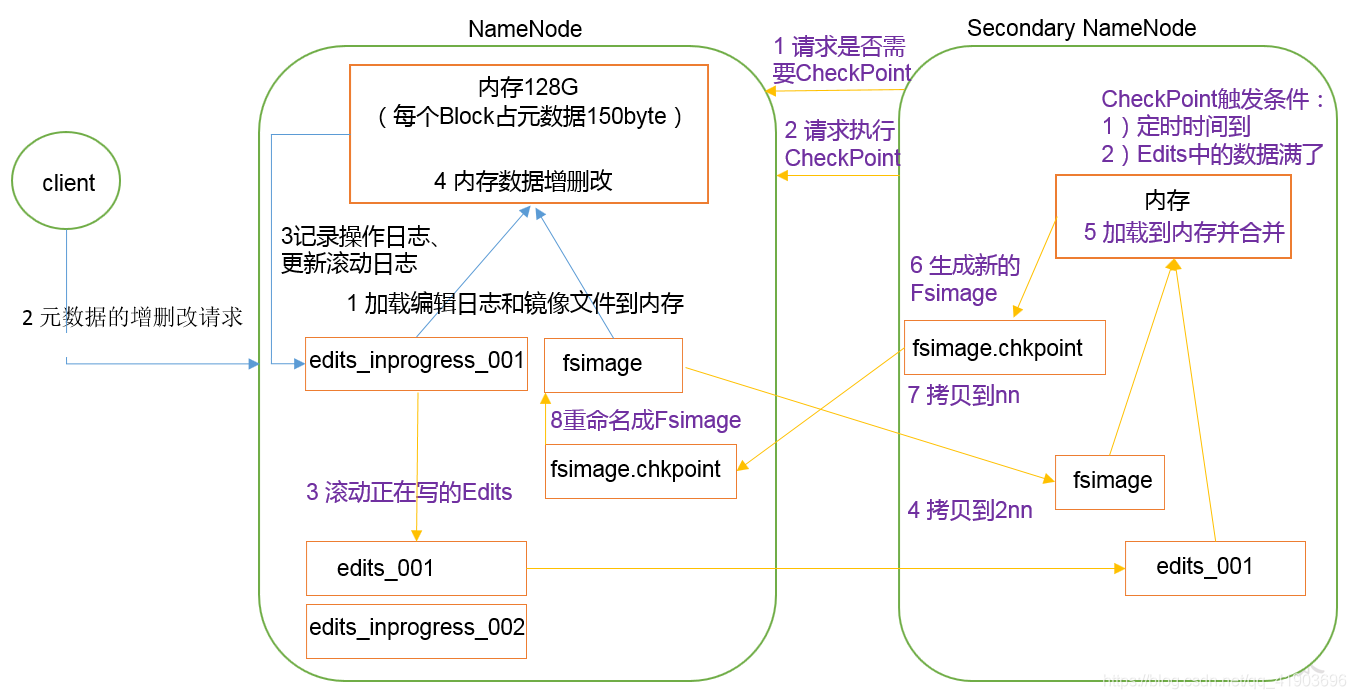
以下是NameNode和SecondaryNameNode的工作机制流程图:
Fsimage:NameNode内存中元数据序列化后形成的文件。
Edits:记录客户端更新元数据信息的每一步操作(可通过Edits运算出元数据)。
NameNode启动时,先滚动Edits并生成一个空的edits.inprogress,然后加载Edits和Fsimage到内存中,此时NameNode内存就持有最新的元数据信息。Client开始对NameNode发送元数据的增删改的请求,这些请求的操作首先会被记录到edits.inprogress中(查询元数据的操作不会被记录在Edits中,因为查询操作不会更改元数据信息),如果此时NameNode挂掉,重启后会从Edits中读取元数据的信息。然后,NameNode会在内存中执行元数据的增删改的操作。
由于Edits中记录的操作会越来越多,Edits文件会越来越大,导致NameNode在启动加载Edits时会很慢,所以需要对Edits和Fsimage进行合并(所谓合并,就是将Edits和Fsimage加载到内存中,照着Edits中的操作一步步执行,最终形成新的Fsimage)。SecondaryNameNode的作用就是帮助NameNode进行Edits和Fsimage的合并工作。
SecondaryNameNode首先会询问NameNode是否需要CheckPoint(触发CheckPoint需要满足两个条件中的任意一个,定时时间到和Edits中数据写满了)。直接带回NameNode是否检查结果。SecondaryNameNode执行CheckPoint操作,首先会让NameNode滚动Edits并生成一个空的edits.inprogress,滚动Edits的目的是给Edits打个标记,以后所有新的操作都写入edits.inprogress,其他未合并的Edits和Fsimage会拷贝到SecondaryNameNode的本地,然后将拷贝的Edits和Fsimage加载到内存中进行合并,生成fsimage.chkpoint,然后将fsimage.chkpoint拷贝给NameNode,重命名为Fsimage后替换掉原来的Fsimage。NameNode在启动时就只需要加载之前未合并的Edits和Fsimage即可,因为合并过的Edits中的元数据信息已经被记录在Fsimage中。
NameNode被格式化之后,将在/opt/module/hadoop-2.7 .2/data/tmp/dfs/name/curent目录中产生如下文件:
fs image 0000000000000000000
fsimage_ 0000000000000000000 .md5
seen txid
VERS ION
( 1 ) Fsimage文件: HDFS文件系统元数据的一个永久性的检查点,其中包含HDFS文件系统的所有目
录和文件inode的序列化信息。
(2 ) Edits文件:存放HDFS文件系统的所有更新操作的路径,文件系统客户端执行的所有写操作首先
会被记录到Edits文件中。
( 3 ) seen_ _txid文件保存的是一 个数字,就是最后一 个edits_ 的数字
( 4 )每次NameNode启动的时候都会将Fsimage文件读入内存,加载Edits里面的更新操作,保证内存
中的元数据信息是最新的、同步的,可以看成NameNode启动的时候就将Fsimage和Edits文件进行了合并。
通过查看fs image 0000000000000000000文件的内容发现元数据的数据结构是这样的
<inode>
<id>16386</id>
<type>DIRECTORY</type>
<name>user</name>
<mtime>1512722284477</mtime>
<permission>obcy:supergroup:rwxr-xr-x</permission>
<nsquota>-1</nsquota>
<dsquota>-1</dsquota>
</inode>
其中并没有记录数据块所对应的DataNode节点信息,那么NameNode是如何找到具体的数据位置的那?
是因为DataNode在启动后会像NameNode自动的上报自己节点的所有块信息,这样就能找到对应的数据了。在上报完成之前hdfs集群是处于一种安全模式下的。安全模式结束后就可以正常的访问数据了。

















 563
563

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









