





最近python很火,想在空余时间学习一波,但是安装完Python后运行发现居然报错了,错误代码是0xc000007b,于是通过往上查找发现是因为首次安装Python缺乏VC++库的原因
错误提示如下:
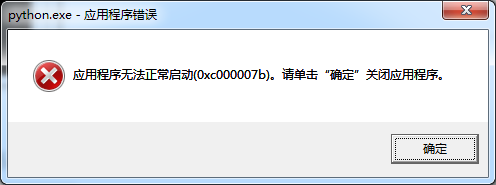
其实这是一个挺常见的系统报错,缺乏VC++库。
我安装的是python3.5.2,这个版本需要的vc版本是2015的了,下载:Microsoft Visual C++ 2015
安装完后发现就正常了:
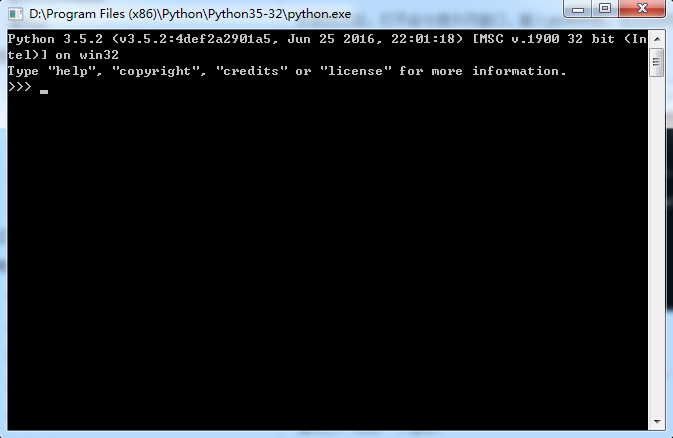

 本文介绍了解决Python安装后出现0xc000007b错误的方法,该错误通常由于缺少VC++库导致。针对Python 3.5.2版本,文章推荐下载并安装Microsoft Visual C++ 2015来修复这一问题。
本文介绍了解决Python安装后出现0xc000007b错误的方法,该错误通常由于缺少VC++库导致。针对Python 3.5.2版本,文章推荐下载并安装Microsoft Visual C++ 2015来修复这一问题。
错误提示如下:
其实这是一个挺常见的系统报错,缺乏VC++库。
我安装的是python3.5.2,这个版本需要的vc版本是2015的了,下载:Microsoft Visual C++ 2015
安装完后发现就正常了:
转载于:https://www.cnblogs.com/fuzitu/p/8480118.html
 572
572

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























