



 本文介绍K-Means聚类算法原理及其在Python中的实现。通过具体案例,包括省份消费水平聚类和鸢尾花数据集聚类,详细展示了如何使用sklearn库进行数据预处理、模型训练及结果分析。
本文介绍K-Means聚类算法原理及其在Python中的实现。通过具体案例,包括省份消费水平聚类和鸢尾花数据集聚类,详细展示了如何使用sklearn库进行数据预处理、模型训练及结果分析。
1、介绍
K-Means 算法以k为参数,把n个对象分为k个簇,使簇内具有较高的相似度,是最简单的一种聚类算法。
2、目的
使各样所在簇的均值误差平方和最小。
3、处理过程
1)随机选择k个点作为初始聚类中心。
2)对于剩下的点,根据其与聚类中心的距离,将其归入最近的簇。
3)对每个簇,计算所有点的均值作为新的聚类中心。
4)重复2,3,直至聚类中心不再发生改变。
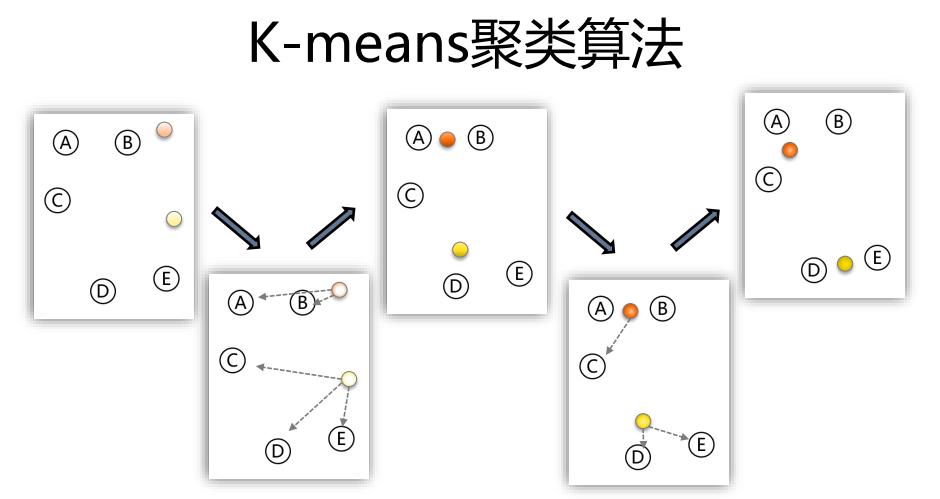
4、算法实例
1)数据介绍
现有1999年全国31个省份城镇居民家庭平均每人全年消费性支出的八个主要变量数据,这八个变量数据,这八个变量分别是:食品、衣着、家庭设备用品及服务、医疗保健、交通和通讯、娱乐教育文化服务、居住以及杂项商品和服务。利用已有数据,对31个省份进行聚类。
2)实验目的
通过聚类,了解1999年各个省份的消费水平在全国的情况。
核心:sklearn.cluster.Kmeans 。
3)数据
北京,2959.19,730.79,749.41,513.34,467.87,1141.82,478.42,457.64
天津,2459.77,495.47,697.33,302.87,284.19,735.97,570.84,305.08
河北,1495.63,515.90,362.37,285.32,272.95,540.58,364.91,188.63
山西,1406.33,477.77,290.15,208.57,201.50,414.72,281.84,212.10
内蒙古,1303.97,524.29,254.83,192.17,249.81,463.09,287.87,192.96
辽宁,1730.84,553.90,246.91,279.81,239.18,445.20,330.24,163.86
吉林,1561.86,492.42,200.49,218.36,220.69,459.62,360.48,147.76
黑龙江,1410.11,510.71,211.88,277.11,224.65,376.82,317.61,152.85
上海,3712.31,550.74,893.37,346.93,527.00,1034.98,720.33,462.03
江苏,2207.58,449.37,572.40,211.92,302.09,585.23,429.77,252.54
浙江,2629.16,557.32,689.73,435.69,514.66,795.87,575.76,323.36
安徽,1844.78,430.29,271.28,126.33,250.56,513.18,314.00,151.39
福建,2709.46,428.11,334.12,160.77,405.14,461.67,535.13,232.29
江西,1563.78,303.65,233.81,107.90,209.70,393.99,509.39,160.12
山东,1675.75,613.32,550.71,219.79,272.59,599.43,371.62,211.84
河南,1427.65,431.79,288.55,208.14,217.00,337.76,421.31,165.32
湖南,1942.23,512.27,401.39,206.06,321.29,697.22,492.60,226.45
湖北,1783.43,511.88,282.84,201.01,237.60,617.74,523.52,182.52
广东,3055.17,353.23,564.56,356.27,811.88,873.06,1082.82,420.81
广西,2033.87,300.82,338.65,157.78,329.06,621.74,587.02,218.27
海南,2057.86,186.44,202.72,171.79,329.65,477.17,312.93,279.19
重庆,2303.29,589.99,516.21,236.55,403.92,730.05,438.41,225.80
四川,1974.28,507.76,344.79,203.21,240.24,575.10,430.36,223.46
贵州,1673.82,437.75,461.61,153.32,254.66,445.59,346.11,191.48
云南,2194.25,537.01,369.07,249.54,290.84,561.91,407.70,330.95
西藏,2646.61,839.70,204.44,209.11,379.30,371.04,269.59,389.33
陕西,1472.95,390.89,447.95,259.51,230.61,490.90,469.10,191.34
甘肃,1525.57,472.98,328.90,219.86,206.65,449.69,249.66,228.19
青海,1654.69,437.77,258.78,303.00,244.93,479.53,288.56,236.51
宁夏,1375.46,480.89,273.84,317.32,251.08,424.75,228.73,195.93
新疆,1608.82,536.05,432.46,235.82,250.28,541.30,344.85,214.40
4)Python实现
(1)导入相关模块。numpy与sklearn。
import numpy as np [数组矩阵运算模块]
from sklearn.cluster import *[sklearn模块下引用聚类等相关函数,本例运用KMeans]
(2)定义数据导出函数。
def loadate(filepath):
fr=open(filepath,'r')
lines=fr.readlines()
retdata=[]
retname=[]
for line in lines:
readfile=line.split(",")
retname.append(readfile[0])
retdata.append(readfile[1:])
return retdata,retname
(3)数据处理并显示结果。
f __name__=='__main__':
data,cityname=loadate('**')
km=KMeans(n_clusters=3) //定义聚类中心个数
lable=km.fit_predict(data) //数据处理并加标签
clusters=[[],[],[]]
for i in range(len(cityname)):
clusters[lable[i]].append(cityname[i])//将相同标签的城市名称放入同一个列表中
for i in range(len(clusters)):
clusteraverage=np.sum(km.cluster_centers_,axis=1)//各簇平均花费
print("clustersum:%.2f"% clusteraverage[i])//输出结果
print(clusters[i])
5)sklearn.cluster.KMeans相关
官方API文档:http://scikit-learn.org/stable/modules/generated/sklearn.cluster.KMeans.html#sklearn.cluster.KMeans
6)KMeans聚类编程题
给出部分莺尾花lris数据集,将莺尾花聚类成3类,结果可视化,与莺尾花原本标签比较。
数据集:
5.0,3.0,1.6,0.2,setosa
5.0,3.4,1.6,0.4,setosa
5.2,3.5,1.5,0.2,setosa
5.2,3.4,1.4,0.2,setosa
4.7,3.2,1.6,0.2,setosa
4.8,3.1,1.6,0.2,setosa
5.4,3.4,1.5,0.4,setosa
5.2,4.1,1.5,0.1,setosa
6.6,3.0,4.4,1.4,versicolor
6.8,2.8,4.8,1.4,versicolor
6.7,3.0,5.0,1.7,versicolor
6.0,2.9,4.5,1.5,versicolor
5.7,2.6,3.5,1.0,versicolor
5.5,2.4,3.8,1.1,versicolor
5.5,2.4,3.7,1.0,versicolor
7.7,2.8,6.7,2.0,virginica
6.3,2.7,4.9,1.8,virginica
6.7,3.3,5.7,2.1,virginica
7.2,3.2,6.0,1.8,virginica
6.2,2.8,4.8,1.8,virginica
6.1,3.0,4.9,1.8,virginica
6.4,2.8,5.6,2.1,virginica
7.2,3.0,5.8,1.6,virginica
7.4,2.8,6.1,1.9,virginica
7.9,3.8,6.4,2.0,virginica
6.4,2.8,5.6,2.2,virginica
5.1,3.8,1.6,0.2,setosa
4.6,3.2,1.4,0.2,setosa
5.3,3.7,1.5,0.2,setosa
5.0,3.3,1.4,0.2,setosa
7.0,3.2,4.7,1.4,versicolor
6.4,3.2,4.5,1.5,versicolor
6.3,2.5,4.9,1.5,versicolor
6.1,2.8,4.7,1.2,versicolor
6.4,2.9,4.3,1.3,versicolor
6.6,3.0,4.4,1.4,versicolor
6.8,2.8,4.8,1.4,versicolor
6.7,3.0,5.0,1.7,versicolor
6.0,2.9,4.5,1.5,versicolor
5.7,2.6,3.5,1.0,versicolor
5.5,2.4,3.8,1.1,versicolor
5.5,2.4,3.7,1.0,versicolor
5.8,2.7,3.9,1.2,versicolor
6.2,2.9,4.3,1.3,versicolor
5.1,2.5,3.0,1.1,versicolor
5.7,2.8,4.1,1.3,versicolor
5.5,4.2,1.4,0.2,setosa
4.9,3.1,1.5,0.1,setosa
5.0,3.2,1.2,0.2,setosa
5.5,3.5,1.3,0.2,setosa
4.9,3.1,1.5,0.1,setosa
4.4,3.0,1.3,0.2,setosa
5.1,3.4,1.5,0.2,setosa
5.0,3.5,1.3,0.3,setosa
4.5,2.3,1.3,0.3,setosa
4.4,3.2,1.3,0.2,setosa
5.0,3.5,1.6,0.6,setosa
5.1,3.8,1.9,0.4,setosa
4.8,3.0,1.4,0.3,setosa
6.3,2.8,5.1,1.5,virginica
6.5,3.0,5.2,2.0,virginica
6.2,3.4,5.4,2.3,virginica
5.9,3.0,5.1,1.8,virginica
python参考代码:
from sklearn.cluster import KMeans
def loaddata(filepath):
fr=open(filepath,'r')
lines=fr.readlines()
data=[]
name=[]
for line in lines:
readfile=line.split(",")
data.append(readfile[:-1])
name.append(readfile[-1].strip('\n'))
return data,name
if __name__=="__main__":
flowerdata,flowername=loaddata('lris.txt')
km=KMeans(n_clusters=3)
lables=km.fit_predict(flowerdata)
cluster=[[],[],[]]
for i in range(len(flowername)):
cluster[lables[i]].append(flowername[i])
for i in range(len(cluster)):
print (cluster[i])
聚类结果如何?
2017/12/21/12:30:41

















 279
279

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









