






| 版权声明:本文原创发表于 【请点击连接前往】 ,未经作者同意必须保留此段声明!如有侵权请联系我删帖处理! |
为大家介绍一个简单的爬虫工具BeautifulSoup
BeautifulSoup拥有强大的解析网页及查找元素的功能本次测试环境为python3.4(由于python2.7编码格式问题)
此工具在搜索你想爬的数据匹配的方式就是html标签嵌套的顺序(html介绍在其它随笔内)
首先来聊聊BeautifulSoup的安装pip install python-bs4 包含BeautifulSoup方法
再来安装依赖工具requests和解析格式lxml下载安装包 解压进入目录 python setup.py install此方法是请求服务
先来写一个简单的网页解析代码如下:

#!/usr/bin/env python
# -*- coding:utf-8 -*-
from bs4 import BeautifulSoup
import requests
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36',
}
url = "http://www.jd.com/"
wb_data = requests.get(url,headers=headers)
soup = BeautifulSoup(wb_data.text,'lxml')
print(soup)
来简单说明下每行代码得作用:
from从bs4库里import导入BeautifulSoup方法
import导入requests方法
headers表示头文件,伪装成浏览器浏览网页,当然我这里写得简单还没写全
url网页地址
wb_data网页数据requests.get请求访问(url网页京东,headers伪装的头文件)
soup解析后的数据BeautifulSoup解析数据(wb_data网页数据,lxml解析的格式按这个要求解析)
print答应soup解析后的网页数据 也就是网页源代码如下 由于网页源代码很长所以这里截图只能显示一部分
学好基础包括html的结构标签的嵌套还有CSS的名字在网页位置等后教你们怎么去抓电影等网站并且把内容归类好方便查阅
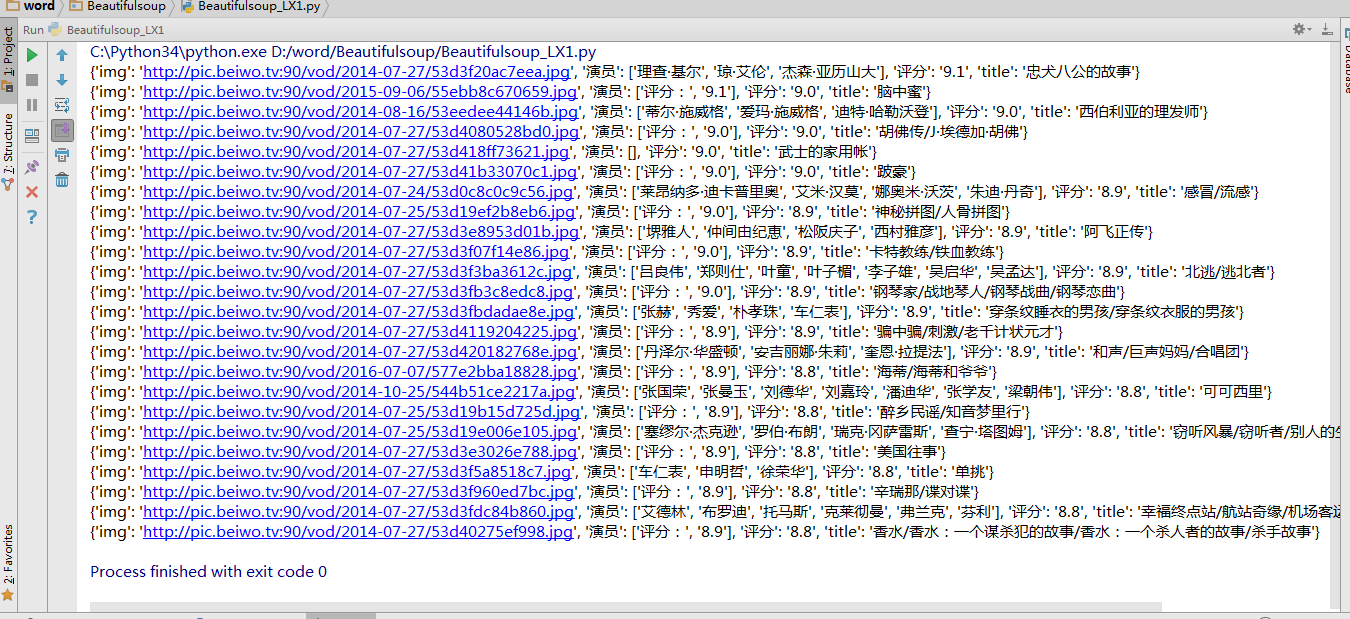
下面是我抓去某电影网站的数据及归类效果掩饰:

















 1259
1259

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









