






 本文详细介绍了使用pythonpreprocess.py脚本进行音视频数据预处理及模型训练的步骤。包括如何通过命令行获取帮助信息,具体参数的使用方法,以及在LJSpeech数据集上运行预处理和遇到训练过程中的常见问题。
本文详细介绍了使用pythonpreprocess.py脚本进行音视频数据预处理及模型训练的步骤。包括如何通过命令行获取帮助信息,具体参数的使用方法,以及在LJSpeech数据集上运行预处理和遇到训练过程中的常见问题。
一、预处理
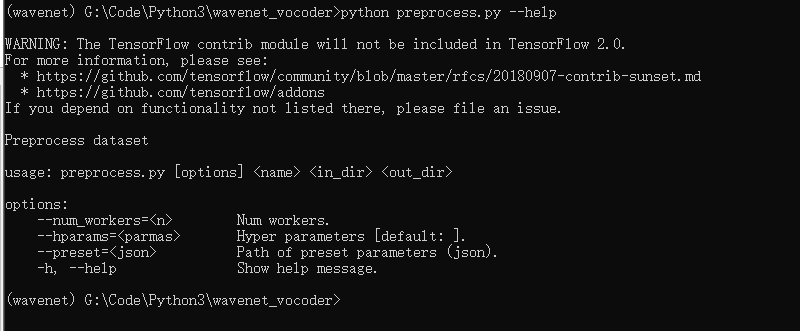
1.在进行预处理时,如果不明白需要的参数,可以使用命令获取帮助,从这里我们可以看到可以具体的用法和对应的参数。
python preprocess.py --help
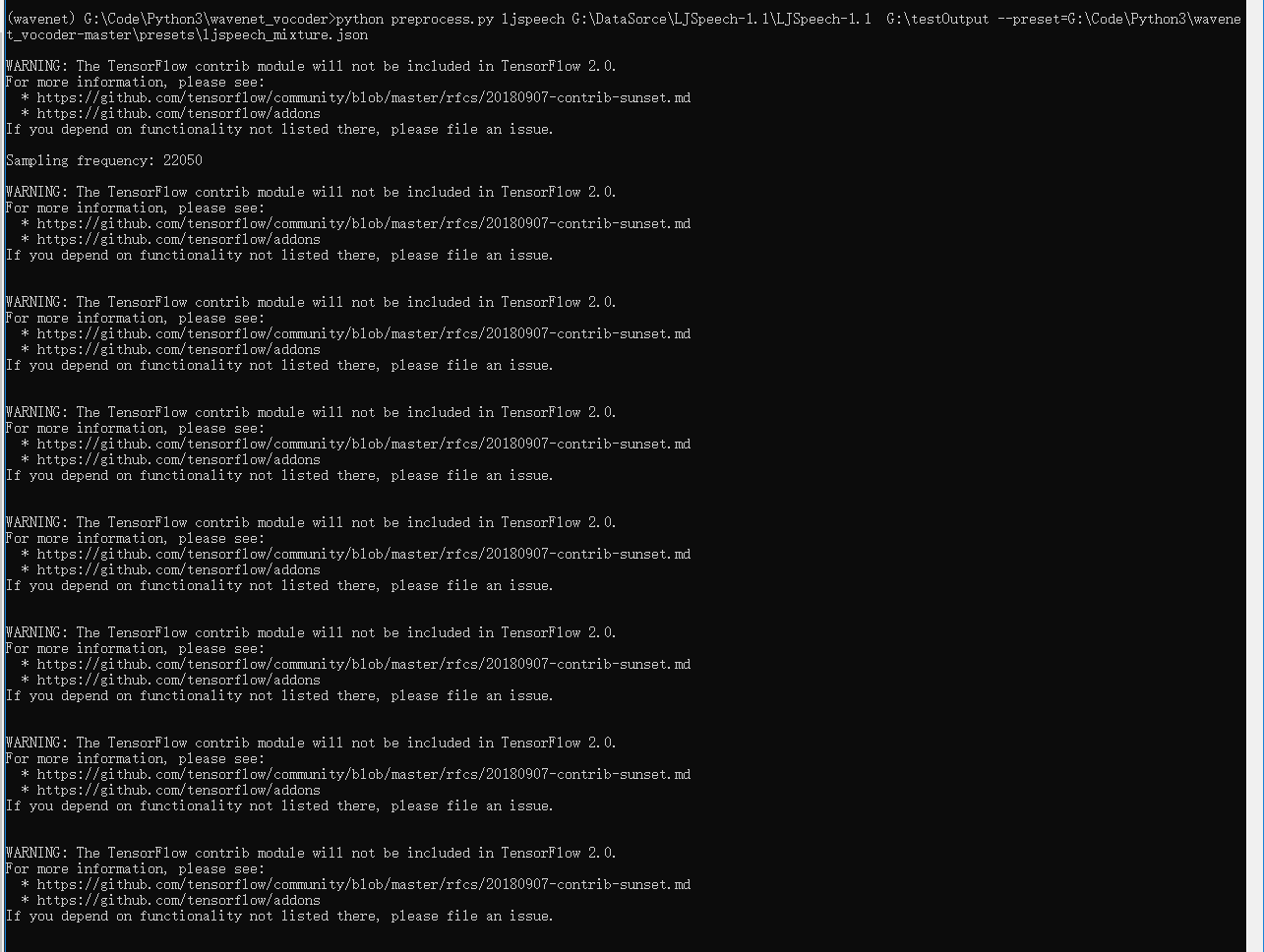
2.接下来就直接输入命令来获取预处理的结果吧。
python preprocess.py ljspeech G:\DataSorce\LJSpeech-1.1\LJSpeech-1.1 G:\testOutput --preset=G:\Code\Python3\wavenet_vocoder-master\presets\ljspeech_mixture.json
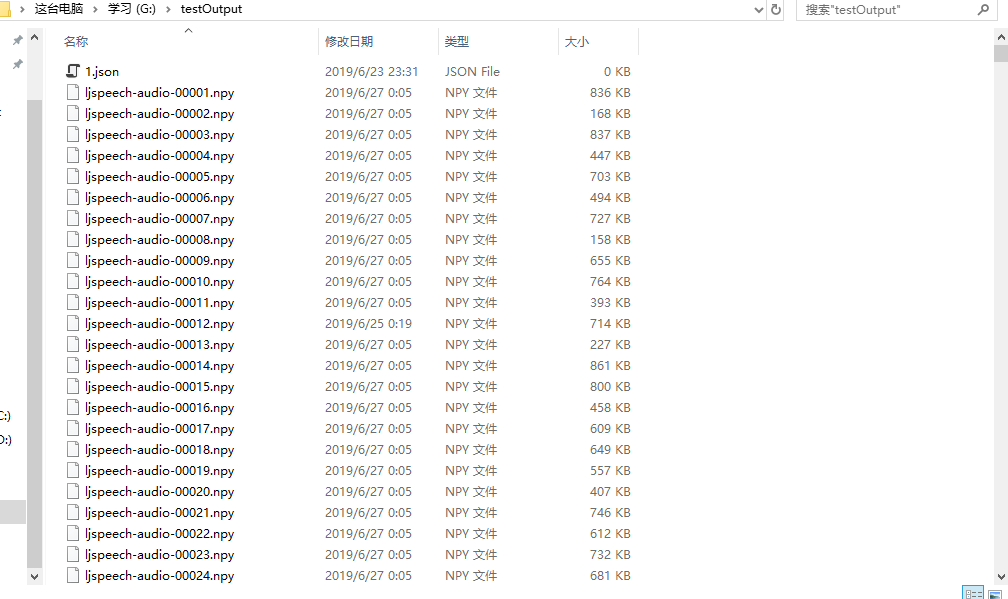
3.最终得到的结果就是这些一堆的东西(还在研究有什么用)
二、训练
1.在进行训练时,如果不明白需要的参数,我们也可以使用命令获取帮助,从这里我们可以看到可以具体的用法和对应的参数。
python preprocess.py --help
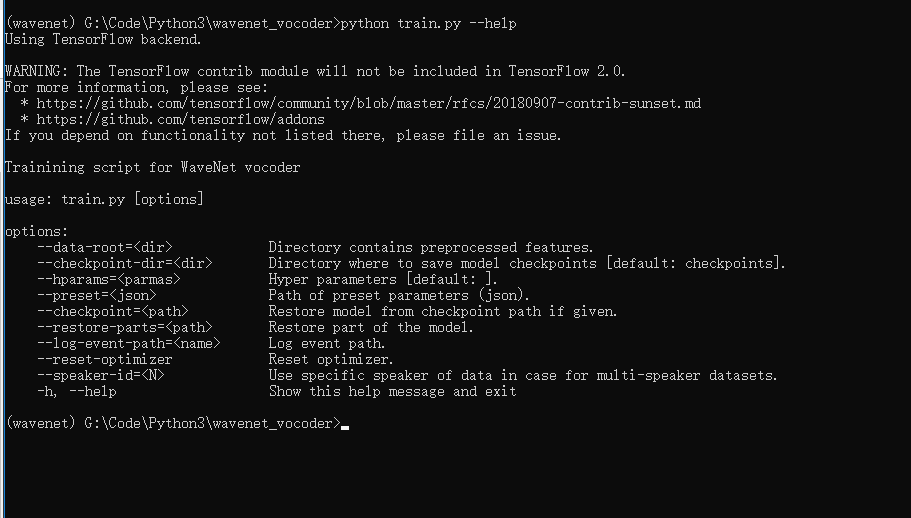
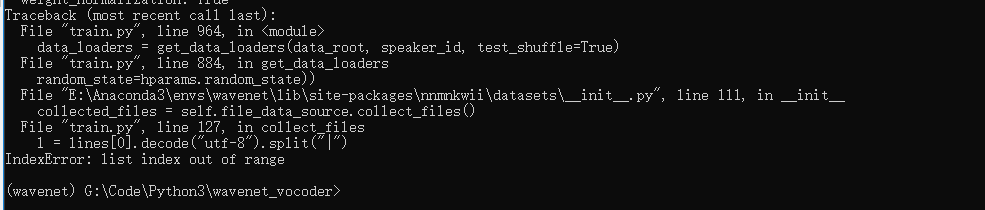
2.我们执行训练的命令,遇到了一个问题,这个我还在查。。。。待续。。。。。

















 710
710

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









