



 本文介绍了使用Python和scikit-learn对鸢尾花数据集进行的分析过程,包括数据加载、可视化、特征规范化、训练分类器及预测,并展示了如何通过三维散点图区分不同种类的鸢尾花。
本文介绍了使用Python和scikit-learn对鸢尾花数据集进行的分析过程,包括数据加载、可视化、特征规范化、训练分类器及预测,并展示了如何通过三维散点图区分不同种类的鸢尾花。
一.加载数据:
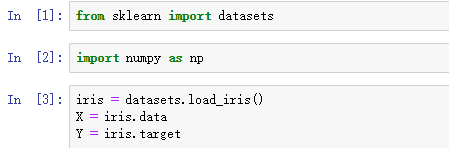
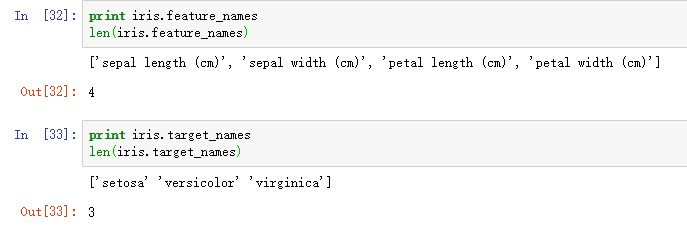
然后看一下有多少个特征和类别以及它们的名字:
二.数据可视化::
由于该套数据集有4个特征,所以只能选取2个特征进行显示。

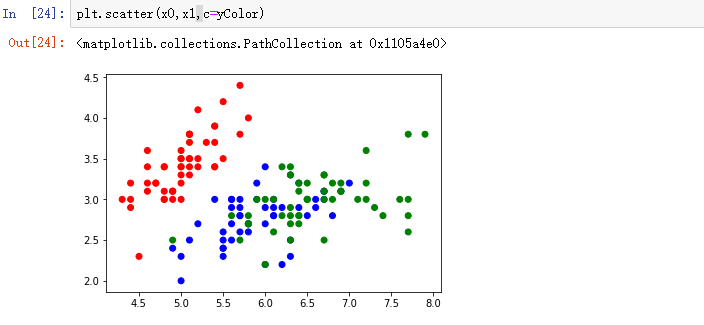
可见红色和绿色的点混在一起,所以再选择其他特征作为坐标轴:
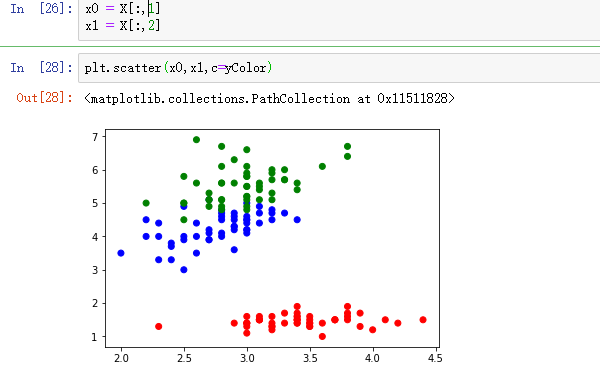
这样就可以区别这三种类别了。
补充:还可以用三维视图:
from sklearn import datasets import numpy as np import matplotlib.pyplot as plt from mpl_toolkits.mplot3d import Axes3D iris = datasets.load_iris() X = iris.data Y = iris.target x0 = X[:,0]; x1 = X[:,1]; x2 = X[:,2] ax = plt.subplot(111, projection='3d') color = np.array(['r', 'g', 'b']) Color = np.array(color[Y]) ax.scatter(x0,x1,x2, c=Color) plt.show()
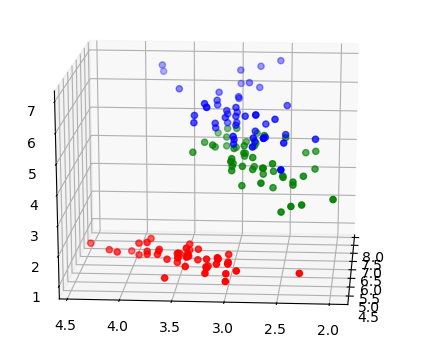
三.训练分类器:

四.进行预测:

五.规范化过程:
import numpy as np from sklearn import datasets import matplotlib.pyplot as plt from sklearn import metrics from sklearn.naive_bayes import GaussianNB from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler iris = datasets.load_iris() #加载数据 X = iris.data Y = iris.target scaler = StandardScaler() #特征归一化 X = scaler.fit_transform(X) train_X,test_X, train_y, test_y = train_test_split(X, Y, test_size=0.2) #划分训练集、测试集 model = GaussianNB() #创建贝叶斯分类器 model.fit(train_X, train_y) expected = test_y #实际值 predicted = model.predict(test_X) #预测值 print metrics.classification_report(expected, predicted) #输出分类效果

















 783
783

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









